MaxCompute执行引擎核心技术DAG揭秘
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MaxCompute执行引擎核心技术DAG揭秘相关的知识,希望对你有一定的参考价值。
简介: 作为业界少有的EB级数据分布式平台,MaxCompute每天支撑上千万个分布式作业的运行。这些作业特点各异,既有包含数十万计算节点的超大型作业,也有中小规模的分布式作业。不同用户对于不同规模/特点的作业,在运行时间,资源使用效率,数据吞吐率等方面,也有着不同的期待。DAG作为MaxCompute执行引擎的核心技术之一,在提供了底层统一的动态执行框架的同时,实现了一个在离线混合的执行模式(Bubble Execution),达到了平衡极致性能以及高效的资源利用率的目的。
作为业界少有的EB级别数据分布式平台,MaxCompute系统每天支撑上千万个分布式作业的运行。在这个量级的作业数目上,毫无疑问平台需要支撑的作业特点也多种多样:既有在"阿里体量"的大数据生态中独有的包含数十万计算节点的超大型作业,也有中小规模的分布式作业。同时不同用户对于不同规模/特点的作业,在运行时间,资源使用效率,数据吞吐率等方面,也有着不同的期待。

Fig.1 MaxCompute线上数据分析
基于作业的不同规模,当前MaxCompute平台提供了两种不同的运行模式,下表对于这两种模式做了总结对比:
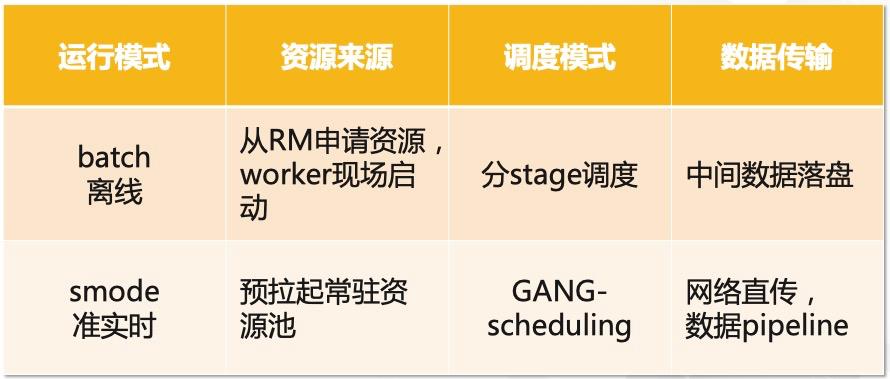
Fig.2 离线(batch)模式 vs 一体化调度准实时(smode)模式
从上图可以看到,离线作业和一体化调度的准实时作业,在调度方式,数据传输,使用资源来源等多个方面,都有非常显著的区别。可以说,这两种运行方式分别代表了在海量数据场景上按需申请资源来优化吞吐量和资源利用率,以及在处理中等(少量)数据时通过计算节点的全量预拉起来(以及数据直传等手段加速)降低执行时延的两个极端。而这些区别,最终会通过执行时间和作业资源利用率等方面体现出来。很显然,以高Throughput为主要优化目标的离线模式,和以追求低Latency的准实时模式,在各方面的性能指标会有很大的区别。比如以1TB-TPCH标准benchmark为例,此报告执行时间(性能)和资源消耗两个维度来做比较。可以看到,准实时的(SMODE)在性能上有着非常明显的优势(2.3X),但是这样的性能提升也并不是没有代价的。在TPCH这个特定的场景上,一体化执行的SMODE模式,在获取了2.3X性能提升的同时,也消耗了3.2X的系统资源(cpu * time)。
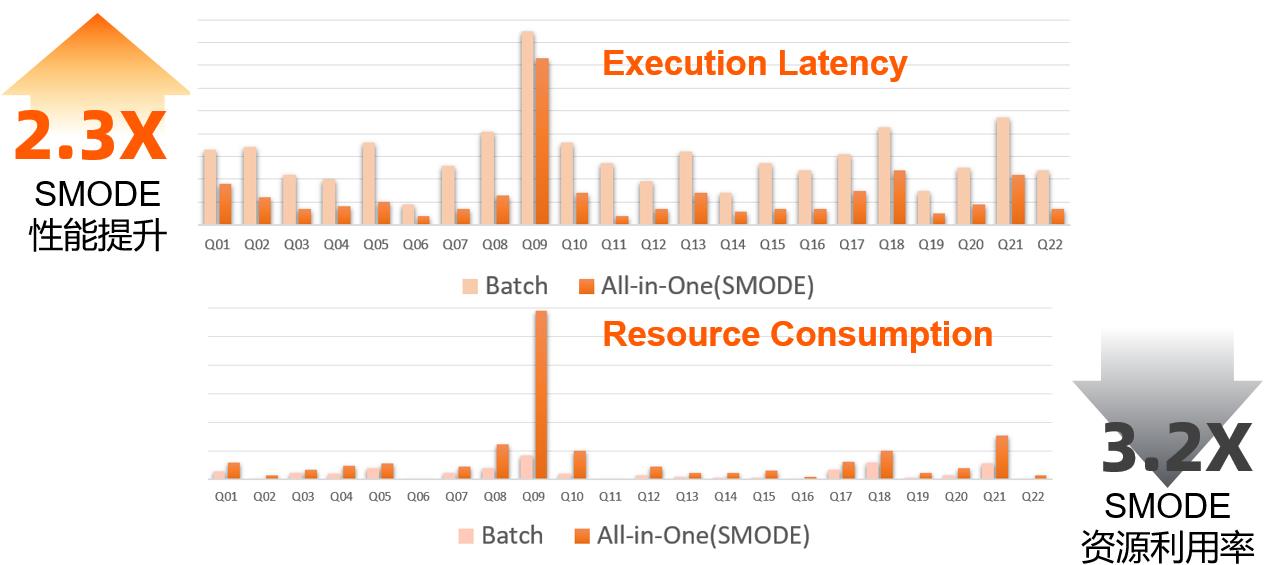
Fig.3 性能/资源消耗比较:离线(batch)模式 vs 一体化调度准实时(smode)模式
这个观察结论其实并不意外,或者从某种程度上是by design的。拿下图一个典型SQL产生的DAG来看,所有计算节点都在作业提交伊始就被拉起,虽然这样的调度方式允许数据得以(在需要的时候)pipeline起来,从而可能加速数据的处理。但并不是所有的执行计划里的所有上下游计算节点都可以有理想化的pipelined dataflow。事实上对于许多作业而言,除了DAG的根节点(下图中的M节点)以外,下游的计算节点在某种程度上都存在着一定程度的浪费。
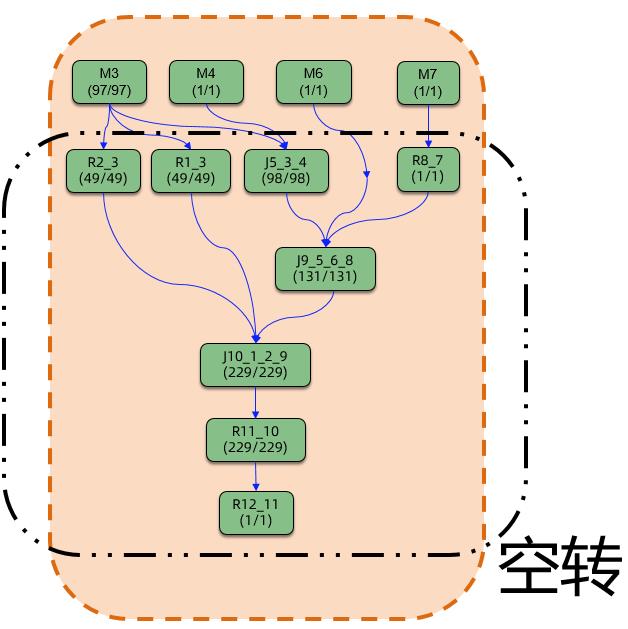
Fig.4 一体化调度准实时(smode)模式下,可能的资源使用低效
这种空转造成的资源使用的低效,在数据的处理流程上存在barrier算子而无法pipeline,以及在DAG图比较深的情况下会尤为明显。当然对于希望极致优化作业运行时间的场景而言,通过更多的资源消耗,来获取极致的性能优化,在一些场景上是有其合理性的。 事实上,在一些business-critical的在线服务系统中,为了保证服务总是能迅速响应并处理峰值数据,平均个位数的CPU利用率也并非少见。但是对于计算平台这种量级的分布式系统,能否在极致性能以及高效的资源利用率之间,获取一个更好的平衡呢?
答案是肯定的。这就是我们在这里要介绍的混合计算模式:Bubble Execution
1. Bubble Execution 概述
DAG框架的核心架构思想,在于对执行计划的逻辑层与物理层的清晰分层设计。物理执行图是通过对逻辑图中的节点、边等的物理特性(如数据传输介质,调度时机,资源特性等)的物化来实现的。对比在Fig.2中描述的batch模式和smode模式,DAG提供了在一套灵活的调度执行框架之上,统一离线模式和准实时一体化执行模式的实现。如同下图所示,通过调整计算节点和数据连接边的不同物理特性,不仅能对现有的两种计算模式做清晰的表述,在对其进行更通用化的扩展后,还可以探索一种全新的混合运行模式,也就是Bubble Execution。
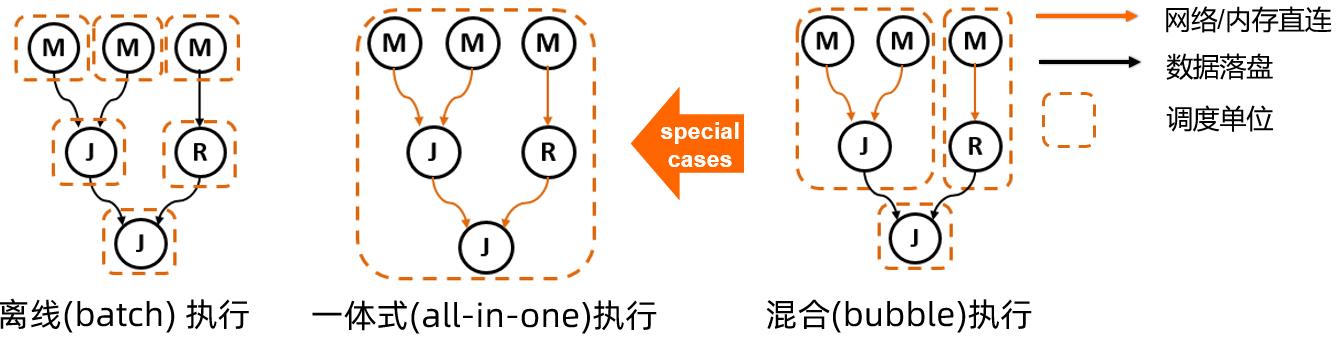
Fig.5 DAG框架上的多种计算模式
直观上来理解,如果我们把一个Bubble当作一个大的调度单位,Bubble内部的资源一起申请运行,并且内部上下游节点的数据均通过网络/内存直连传输。与之相对的,Bubbles之间连接边上的数据传输,则通过落盘方式来传输。那么离线和准实时作业执行,其实可以认为是Bubble执行的两个极端场景:离线模式可以认为是每个stage都单独作为single-bubble的特例,而准实时框架则是将作业所有计算节点都规划到一个大Bubble内部,来做一体化调度执行的另一个极端。DAG AM已经将两种计算模式统一到一套调度执行infra之上。使得在两种模式上进行优点互补成为可能,为引入Bubble Execution奠定了基础。
Bubble Execution通过灵活自适应的子图(Bubble)切割,在现有的两个极端之间,提供了一种选取更细粒度,更通用的调度执行方法,达到作业性能和资源利用率之间获取优化的tradeoff的方法。在根据输入数据量、算子特性、作业规模等信息进行分析后,DAG的Bubble执行模式可以将一个离线作业切分出多个Bubbles,在Bubble内部充分利用网络/内存直连和计算节点预热等方式提升性能。这种切分方式下,一个DAG运行图中的计算节点,可以都被切入某个Bubble,根据所在DAG中的位置被切入不同Bubbles,还可以完全不被切入任何Bubble(依然以传统离线作业模式运行)。这种高度灵活的混合运行模式,使整个作业的运行能更加灵活的自适应线上多种多样作业的特点,在实际生产中具有重要的意义:
- Bubble模式使更多作业的加速成为可能:一体化调度的准实时作业具有基于整体规模(线上默认2000)的"一刀切"式的准入条件。这一方面是出于有限资源的公平使用,另一方面也是为了控制节点failure带来的cost。但对于中大型作业,虽然整体规模可能超过准入门限,但是其内部的不同子图,有可能是规模合适,且可以通过数据pipeline等方法来加速的。此外线上部分计算节点由于其本身的特性(比如包含UDF等用户逻辑需要安全沙箱),无法使用预热的准实时资源池执行,而当前非黑即白的模式,会使得一个作业中,只要包含一个这种计算节点,整个作业都无法使用加速模式执行。Bubble模式能较好的解决这些问题。
- Bubble模式将enable线上两个资源池的打通:当前离线资源(cold)和准实时资源池(warm)作为两种特性不同的线上资源,完全隔离,各自管理。这种分离的现状,可能导致资源的浪费。比如对于大规模作业,因为完全无法利用准实时资源池,排队等待离线资源,而同时准实时资源池可能正处于空闲状态,反之亦然。Bubble模式能通过在作业内部拉通不同资源的混合使用,使得两者各自补充,削峰填谷。
- Bubble模式可以整体上提高资源的利用率:从资源利用的角度来看,对于可以满足准实时模式准入的中型作业,由于准实时模式一体式调度拉起的运行模式,虽然运行速度能有所提升,但客观上会造成一定程度资源的空转与浪费(尤其是DAG图较深以及计算逻辑有barrier时)。这种情况下,按照节点数目,计算barrier等条件,将一体化模式拆解成多个Bubble。这能够有效的减少节点大量的空转消耗,而且在拆分条件合理的情况下,性能方面的损失也可以做到较低。
- Bubble模式能有效降低单个计算节点failure带来的代价:一体化的准实时模式执行,由于其数据pipeline的特性,作业的容错粒度和其调度粒度是紧密挂钩的:都是all-in-one。也就是说,只要有一个节点运行失败,整个作业都要重新运行。因为作业规模越大,运行过程中可能有节点失败的概率也就越大,这样的failover粒度无疑也限制了其能支持的最大作业规模。而Bubble模式则提供了一个更好的平衡点:单个计算节点的失败,最多只影响同处于一个Bubble的节点。此外Bubble模式对于各种failover做了细粒度的各种处理,我们将在下文描述。
我们可以通过标准的TPCH-1TB测试benchmark来直观评测Bubble执行模式的效果。在上层计算引擎(MaxCompute优化器以及runtime等)保持不变,并且Bubble的大小维持在500(具体Bubble切分规则下文介绍)时,做一下Bubble执行模式与标准离线模式,以及准实时模式,在性能(Latency) 以及资源消耗(cpu * time)两个方面的比较:
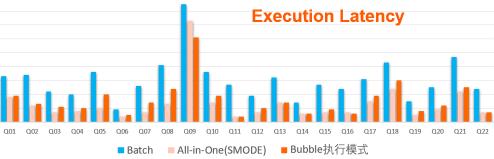
Fig.6.a 性能(Latency)比较:Bubble模式 vs 离线(batch)模式 vs 一体化调度准实时(smode)模式
从运行时间来看,Bubble模式显然要远优于离线模式(整体2X的性能提升),而较准实时的一体化调度模式而言,Bubble的执行性能也并没有太明显的下降。当然在一些数据可以非常有效利用pipeline处理的query(比如Q5, Q8等),准实时作业还是有一定的优势。但SMODE作业在执行时间上的优势并不是没有代价的,如果同时考虑资源消耗,在下图中,我们可以看到,准实时作业的性能提升是建立在资源消耗远远大于Bubble模式的前提之上的。而Bubble在性能远优于离线模式的同时,其资源消耗,则整体上是相近的。
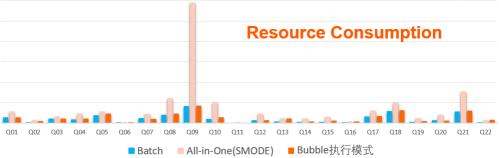
Fig.6.b 资源消耗(cpu * time)比较:
Bubble模式 vs 离线(batch)模式 vs 一体化调度准实时(smode)模式
综合起来看,Bubble Execution可以很好的结合batch模式和准实时模式的优点:
- 在执行时间层面,对于TPCH测试集中的任意query,bubble模式的执行时间都比batch模式要短,整体上22个Queries总耗时缩减将近2X,接近service mode模式的耗时;
- 在资源消耗层面,bubble模式基本上和batch模式相当,相比于service mode模式有大幅度的减少,整体缩减2.6X。
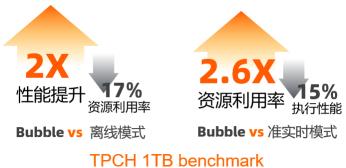
Fig.6.c Bubble模式与离线/准实时模式的整体比较
值得说明的是,在上面的TPCH Benchmark比较中,我们把Bubble切分条件简单化了,也就是整体上之限制bubble的大小在500,而没有充分考虑barrier等条件,如果在切分bubble的时候进一步调优,比如对于数据可以有效pipeline起来的节点,尽量保证切分在bubble内部,那作业的执行性能和资源利用率等方面都还可以进一步得到的提升,这是我们在实际生产系统上线过程中会注重考虑的。具体上线的效果见Section 3。
在了解了Bubble执行模式的整体设计思想与架构后,接下来展开来讲一下具体Bubble模式的实现细节,以及将这种全新的混合执行模式推上线所需要的具体工作。
2. Bubble的切分与执行
采用Bubble Execution的作业(以下简称Bubble作业)和传统的离线作业一样,会通过一个DAG master(aka. Application Master)来管理整个DAG的生命周期。AM负责对DAG进行合理的bubble切分,以及对应的资源申请和调度运行。整体而言,Bubble内部的计算节点,将按照计算加速度原则,包括同时使用预拉起的计算节点以及数据传输通过内存/网络直传进行pipeline加速。而不切在bubble内部的计算节点则通过经典离线模式执行,不在bubble内部的连接边(包括横跨bubble boundary的边)上的数据,均通过落盘方式进行传输。
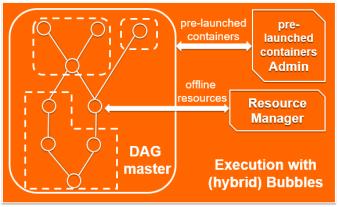
Fig.7 混合Bubble执行模式
Bubble切分方法,决定了作业的执行时间和资源利用率。需要根据计算节点的并发规模,节点内部算子属性等信息综合考虑。而在切分出bubble之后,Bubble的执行则涉及到节点的执行,与数据pipeline/barrier的shuffle方式怎么做到有机的结合,这里分开做一下描述。
2.1 Bubble 切分原理
Bubble Execution的核心思想在于将一个离线作业拆分成多个Bubble来执行。为了切分出有利于作业整体高效运行的bubble,有几个因素需要综合考虑:
- 计算节点内部算子特性:对于同时拉起bubble所有计算节点的调度模式而言,数据在bubble内部的上下游节点之间能否有效的进行pipeline处理,很大程度上决定了在bubble内部,下游节点是否会因处于空转状态带来资源浪费。所以在切分bubble的逻辑中,当节点包含barrier特性的算子而可能阻塞数据的pipeline时,将考虑不将该节点与其下游切入同一个bubble。
- 单个Bubble内部计算节点数目的多少:如同之前讨论的,一体化的资源申请/运行,当包含的计算节点过多时,可能无法申请到资源,或者即使能申请到其failure代价也可能无法控制。限定Bubble的大小,可以避免过大的一体化运行带来的负面作用。
- 聚合计算节点,切割Bubble的迭代方向:考虑到bubble大小的限制,从上而下切分bubble与从下而上切分bubble两种方式,可能导致切分的结果的不同。对于线上大部分作业而言,处理的数据往往呈倒三角型,对应的DAG也大多数是倒三角形态,所以默认采用自底向上的算法来切割bubble,也就是从距离root vertex最远的节点开始迭代。
在上述的几个因素中,算子的barrier属性由上层计算引擎(e.g., MaxCompute的optimizer)给出。一般而言,依赖global sort操作的算子(比如MergeJoin, SorteAggregate等),会被认为会造成数据阻塞(barrier),而基于hash特性操作的算子则对于pipeline更加友好。对于单个Bubble内部允许的计算节点数目,根据我们对线上准实时作业特点的分析和Bubble作业的实际灰度实验,选定的默认上限在500。这是一个在大多数场景下比较合理的值,既能保证比较快速的拿到全量资源,同时由于处理数据量和DoP基本成正相关关系,这个规模的bubble一般也不会出现内存超限的问题。当然这些参数和配置,均允许作业级别通过配置进行微调,同时Bubble执行框架也会后继提供作业运行期间动态实时调整的能力。
在DAG的体系中,边连接的物理属性之一,就是边连接的上下游节点,是否有运行上的前后依赖关系。对于传统的离线模式,上下游先后运行,对应的是sequential的属性,我们称之为sequential edge。而对于bubble内部的上下游节点,是同时调度同时运行的,我们称连接这样的上下游节点的边,为concurrent edge。可以注意到,这种concurrent/sequential的物理属性,在bubble应用场景上,实际与数据的传送方式(网络/内存直传 vs 数据落盘)的物理属性是重合的(Note: 但这两种依然是分开的物理属性,比如在必要的时候concurrent edge上也可以通过数据落盘方式传送数据)。
基于这样的分层抽象,Bubble切分算法,本质上就是尝试聚合DAG图的节点,将不满足bubble准入条件的concurrent edge还原成sequential edge的过程。最终,由concurrent edge联通的子图即为bubble。在这里我们通过一个实际的例子来展示Bubble切分算法的工作原理。假设存在下图所示的DAG图,图中的圆圈表示计算顶点(vertex),每个圆圈中的数字表示该vertex对应的实际计算节点并发度。其中V1和V3因为在作业提交初始,就因为其内部包含barrier算子,而被标注成barrier vertex。圆圈之间的连接线表示上下游的连接边(edge)。橙色线代表(初始)concurrent edge,黑色线代表sequential edge,初始状态图中的sequential edge根据barrier vertex的输出边均为sequential edge的原则确定,其他边默认均初始化为concurrent edge。
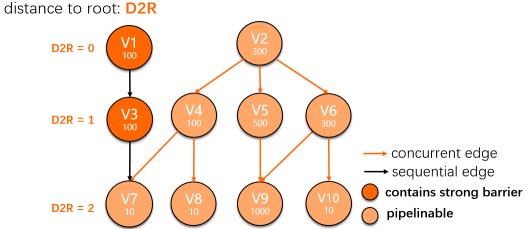
Fig.8 示例DAG图(初始状态)
在这个初始DAG基础上,按照上面介绍过的整体原则,以及本章节最后描述的一些实现细节,上图描述的初始状态,可以经过多轮算法迭代,最终产生如下的Bubble切分结果。在这个结果中产生了两个Bubbles: Bubble#0 [V2, V4, V7, V8],Bubble#1 [V6, V10], 而其他的节点则被判断将使用离线模式运行。
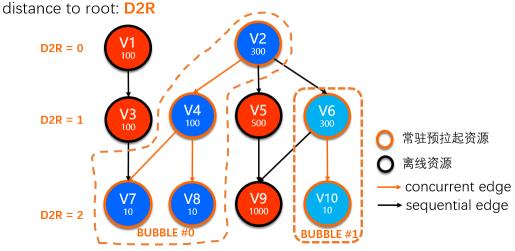
Fig.9 示例DAG图Bubble切分结果
在上图的切分过程中,自底向上的遍历vertex,并秉承如下原则:
若当前vertex不能加入bubble,将其输入edge均还原为sequential edge(比如DAG图中的V9);
若当前vertex能够加入bubble,执行广度优先遍历算法聚合生成bubble,先检索输入edge连接的vertex,再检索输出edge连接的,对于不能联通的vertex,将edge还原为sequential edge(比如DAG图中遍历V2的输出vertex V5时会因为total task count超过500触发edge还原)。
而对任意一个vertex,只有当满足以下条件才能被添加到bubble中:
- vertex和当前bubble之间不存在sequential edge连接;
- vertex和当前bubble不存在循环依赖,即:
- Case#1:该vertex的所有下游vertex中不存在某个vertex是当前bubble的上游;
- Case#2:该vertex的所有上游vertex中不存在某个vertex是当前bubble的下游;
- Case#3:该vertex的所有下游bubble中不存在某个vertex是当前bubble的上游;
- Case#4:该vertex的所有上游bubble中不存在某个vertex是当前bubble的下游;
注:这里的上游/下游不仅仅代表当前vertex的直接后继/前驱,也包含间接后继/前驱
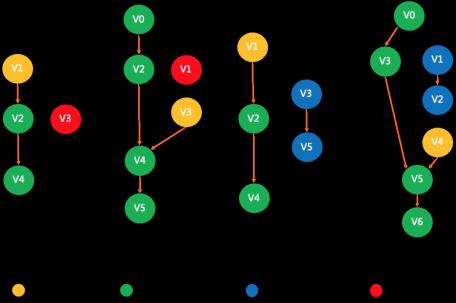
Fig.10 切分Bubble过程可能存在循环依赖的几种场景
而实际线上bubble的切分还会考虑到实际资源和预期运行时间等信息,比如计算节点的plan memory 是否超过一定数值,计算节点中是否包含UDF算子,生产作业中计算节点基于历史信息(HBO)的预估执行时间是否超长,等等,这里不再赘述。
2.2 Bubble的调度与执行
2.2.1 Bubble调度
为了实现计算的加速,Bubble内部的计算节点的来源默认均来自常驻的预热资源池,这一点与准实时执行框架相同。与此同时我们提供了灵活的可插拔性,在必要的情况下,允许Bubble计算节点从Resource Manager当场申请(可通过配置切换)。
从调度时机上来看,一个Bubble内部的节点调度策略与其对应的输入边特性相关,可以分成下面几种情况:
- 不存在任何input edge的bubble root vertext(比如 Fig.9中的V2):作业一运行就被调度拉起。
- 只有sequential edge输入bubble root vertex(比如 Fig.9中的V6):等待上游节点完成度达到配置的min fraction比例(默认为100%,即所有上游节点完成)才被调度。
- Bubble内部的vertex(即所有输入边都是concurrent edge,比如 Fig.9中的V4, V8, V10),因为其完全是通过concurrent edge进行连接的,会自然的被与上游同时触发调度。
- Bubble边界上存在mixed-inputs的bubble root vertex(比如 Fig.9中的V7)。这种情况需要一些特殊处理,虽然V7与V4是通过concurrent edge链接,但是由于V7的调度同时被V3通过sequential edge控制,所以事实上需要等待V3完成min-fraction后才能调度V7。对于这种场景,可以将V3的min-fraction配置为较小(甚至0)来提前触发;此外Bubble内部我们也提供了progressive调度的能力,对这种场景也会有帮助。
比如图7中的Bubble#1,只有一条SequentialEdge外部依赖边,当V2完成后,就会触发V6 + V10(通过concurrent edge)的整体调度,从而将整个Bubble#1运行起来。
在Bubble被触发调度后,会直接向SMODE Admin申请资源,默认使用的是一体化Gang-Scheduling(GS)的资源申请模式,在这种模式下,整个Bubble会构建一个request,发送给Admin。当Admin有足够的资源来满足这个申请时,会将,再包含预拉起worker信息的调度结果发送给bubble作业的AM。
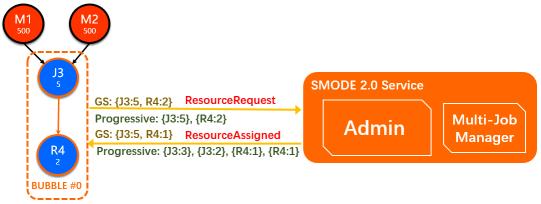
Fig.11 Bubble与Admin之间的资源交互
为了同时支持紧张资源上以及Bubble内部动态调整的场景,Bubble同时还支持Progressive的资源申请模式。这种模式允许Bubble内的每个Vertex独立申请资源和调度。对于这种申请,Admin只要有增量的资源调度即会将结果发送给AM,直到对应Vertex的request完全满足。对于这种场景上的独特应用这里暂时不做展开。
在准实时执行框架升级后,SMODE服务中的资源管理(Admin)和多DAG作业管理逻辑(MultiJobManager)已经解耦,因此bubble模式中的资源申请逻辑,只需要和Admin进行交互,而不会对于正常准实时作业的DAG执行管理逻辑带来任何影响。另外,为了支持线上灰度热升级能力,Admin管理的资源池中的每个常驻计算节点均通过Agent+多Labor模式运行,在调度具体资源时,还会根据AM版本,进行worker版本的匹配,并调度满足条件的labor给Bubble作业。
2.2.2 Bubble数据Shuffle
对于穿越Bubble bourndary上的sequential edge,其上传输的数据和普通离线作业相同,都是通过落盘的方式来进行数据传输。这里我们主要讨论在Bubble内部的数据传输方式。根据之前描述的作业bubble切分原则,bubble内部的通常具备充分的数据pipeline特性,且数据量不大。因此对于bubble内部concurrent edge上的数据,均采用执行速度最快的网络/内存直传方式来进行shuffle。
这其中网络shuffle的方式和经典的准实时作业相同,通过上游节点和下游节点之间建立TCP链接,进行网络直连发送数据。这种push-based的网络传送数据方式,要求上下游必须同时拉起,根据链式的依赖传递,这种网络push模式强依赖于Gang-Scheduling,此外在容错,长尾规避等问题上也限制了bubble的灵活性。
为了更好的解决以上问题,在Bubble模式上,探索了内存shuffle模式。在这一模式下,上游节点将数据直接写到集群ShuffleAgent(SA)的内存中,而下游节点则从SA中读取数据。内存shuffle模式的容错,扩展,包括在内存不够的时候将部分数据异步落盘保证更高的可用性等能力,由ShuffleService独立提供。这种模式可以同时支持Gang-Scheduling/Progressive两种调度模式,也使其具备了较强的可扩展性,比如可以通过SA Locality调度实现更多的Local数据读取,通过基于血缘的instance level retry实现粒度更精细的容错机制等等。
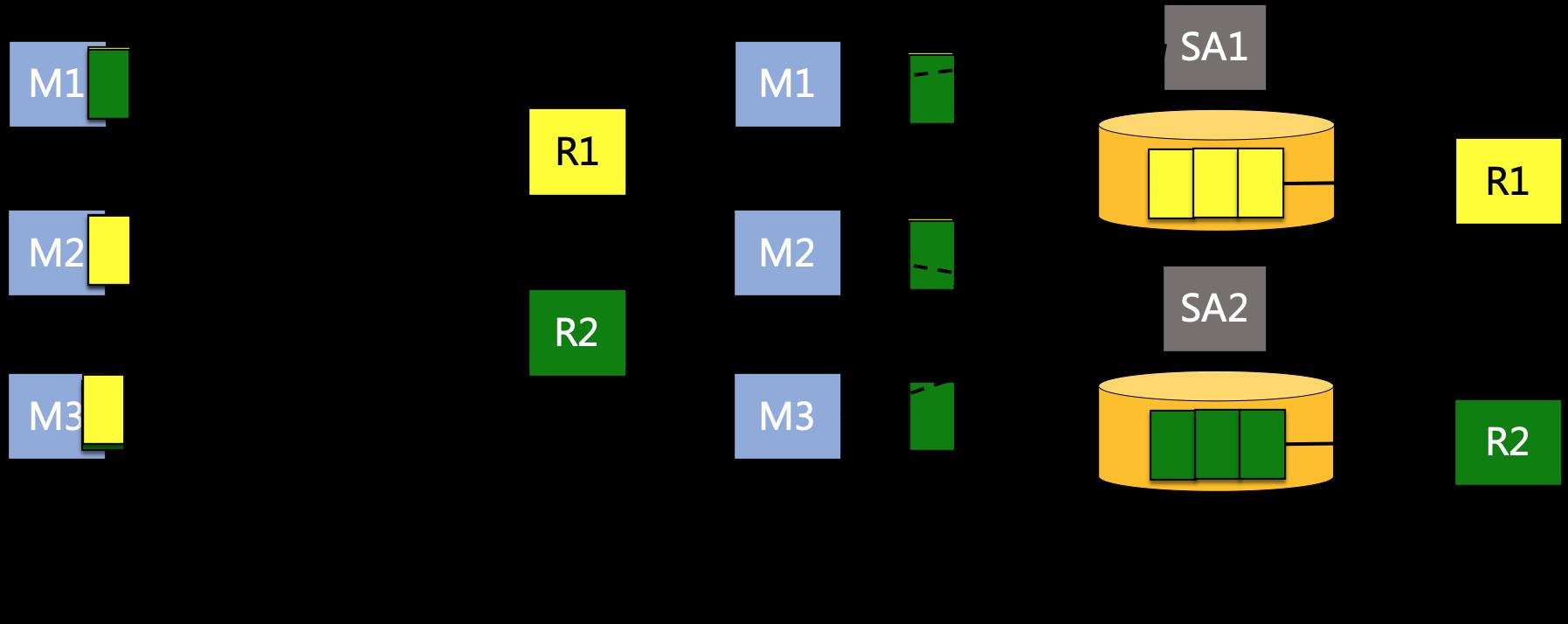
Fig.12 Network Shuffle VS Memory Shuffle
鉴于内存shuffle提供的诸多可扩展优势,这也是线上Bubble作业选用的默认shuffle方式,而网络直传则作为备选方案,允许在容错代价很小的超小规模作业上,通过配置使用。
2.3 Fault-Tolerance
作为一种全新的混合执行模式,Bubble执行探索了在离线作业和一体化调度的准实时作业间的各种细粒度平衡。在线上复杂的集群中,运行过程中各种各样的失败在所难免。而bubble这种全新模式下,为了保证失败的影响最小,并在可靠性和作业性能之间取得最佳的平衡,其对于失败处理的策略也更加的多样化。
针对不同的异常问题,我们设计了各种针对性容错策略,通过各种从细到粗的力度,处理执行过程中可能涉及的各种异常场景处理,比如:向admin申请资源失败、bubble中的task执行失败(bubble-rerun)、bubble多次执行失败的回退(bubble-renew),执行过程中AM发生failover等等。
2.3.1 Bubble Rerun
目前Bubble在内部计算节点失败时,默认采用的retry策略是rerun bubble。即当bubble内的某个节点的本次执行(attempt)失败,会立即rerun整个bubble,取消正在执行的同一版本的attempt。在归还资源的同时,触发bubble重新执行。通过这种方式,保证bubble内所有计算节点对应的(retry) attempt版本一致。
触发bubble rerun的场景有很多,比较常见的有以下几种:
- Instance Failed:计算节点执行失败,通常由上层引擎的runtime错误触发(比如抛出retryable-exception)。
- Resource Revoked:在线上生产环境,有很多种场景会导致资源节点重启。比如所在的机器整机oom、机器被加黑等。在worker被杀之后,重启之后的worker会依照最初的启动参数重新连回admin。此时,admin会将这个worker重启的消息封装成Resource Revoked发送给对应的AM,触发bubble rerun。
- Admin Failover: 由于Bubble作业所使用的计算资源来自于SMODE的admin资源池,当admin由于某些原因Failover,或者SMODE整体服务被重启时,分配给AM的计算节点会被停止。Admin在Failover之后不感知当前各个节点被分配的AM信息,无法将这些重启的消息发送给AM。目前的处理方法是,每个AM订阅了admin对应的nuwa,在admin重启之后会更新这个文件. AM感知到信息更新后,会触发对应的taskAttempt Failed,从而rerun bubble。
- Input Read Error:在计算节点执行时,读不到上游数据是一个很常见的错误,对于bubble来说,这个错误实际上有三种不同的类型:
- Bubble内的InputReadError:由于shuffle数据源也在bubble内,在rerun bubble时,对应上游task也会重跑。不需要再做针对性的处理。
- Bubble边界处的InputReadError: shuffle数据源是上游离线vertex(或也可能是另一个bubble)中的task产生,InputReadError会触发上游的task重跑,当前bubble rerun之后会被delay住,直到上游血缘(lineage)的新版本数据全部ready之后再触发调度。
- Bubble下游的InputReadError: 如果bubble下游的task出现了InputReadError,这个事件会触发bubble内的某个task重跑,此时由于该task依赖的内存shuffle数据已经被释放,会触发整个bubble rerun。
2.3.2 Bubble Renew
在Admin资源紧张时, Bubble从Admin的资源申请可能等因为等待而超时。在一些异常情况下,比如bubble申请资源时刚好onlinejob服务处于重启的间隔,也会出现申请资源失败的情况。在这种情况下,bubble内所有vertex都将回退成纯离线vertex状态执行。此外对于rerun次数超过上限的bubble,也会触发bubble renew。在bubble renew发生后,其内部所有边都还原成sequential edge,并在所有vertex重新初始化之后,通过回放内部所有调度状态机触发事件,重新以纯离线的方式触发这些vertex的内部状态转换。确保当前bubble内的所有vertex在回退后,均会以经典离线的模式执行,从而有效的保障了作业能够正常terminated。
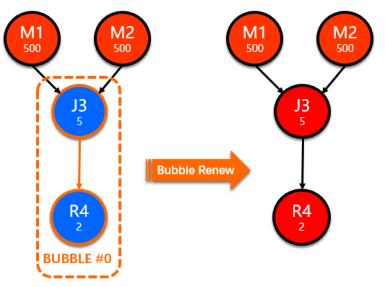
Fig. 13 Bubble Renew
2.3.3 Bubble AM Failover
对于正常的离线作业,在DAG框架中,每个计算节点相关的内部调度事件都会被持久化存储,方便做计算节点级别的增量failover。但是对于bubble作业来说,如果在bubble执行过程发生了AM failover重启,通过存储事件的replay来恢复出的bubble,有可能恢复到running的中间状态。然而由于内部shuffle数据可能存储在内存而丢失,恢复成中间running状态的bubble内未完成的计算节点,会因读取不到上游shuffle数据而立刻失败。
这本质上是因为在Gang-Scheduled Bubble的场景上,bubble整体是作为failover的最小粒度存在的,所以一旦发生AM的failover,恢复粒度也应该在bubble这个层面上。所以对于bubble相关的所有调度事件,在运行中都会被当作一个整体,同时当bubble开始和结束的时候分别刷出bubbleStartedEvent和bubbleFInishedEvent。一个bubble所有相关的events在failover后恢复时会被作为一个整体,只有结尾的bubbleFInishedEvent才表示这个bubble可以被认为完全结束,否则将重跑整个bubble。
比如在下图这个例子中,DAG中包含两个Bubble(Bubble#0: {V1, V2}, Bubble#1: {V3, V4}),在发生AM重启时,Bubble#0已经TERMINATED,并且写出BubbleFinishedEvent。而Bubble#1中的V3也已经Terminated,但是V4处于Running状态,整个Bubble #1并没有到达终态。AM recover之后,V1,V2会恢复为Terminated状态,而Bubble#1会重头开始执行。
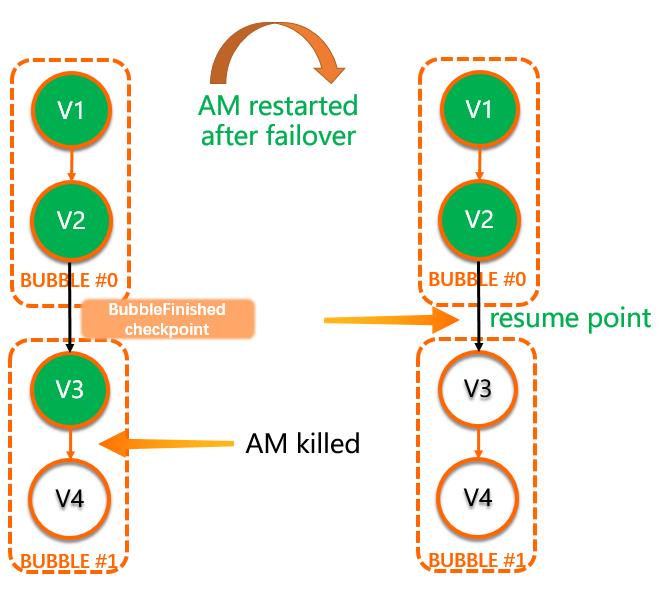
Fig 14. AM Failover with Bubbles
3. 上线效果
当前Bubble模式已经在公共云全量上线,SQL作业中34%执行Bubble,日均执行包含176K个Bubble。
我们针对signature相同的query在bubble execution关闭和打开时进行对比,我们发现在整体的资源消耗基本不变的基础上,作业的执行性能提升了34%,每秒处理的数据量提升了54%。
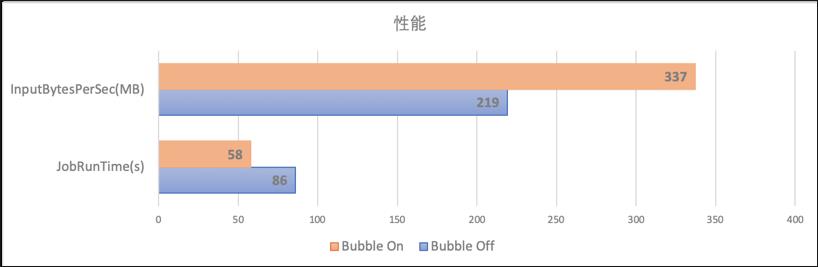
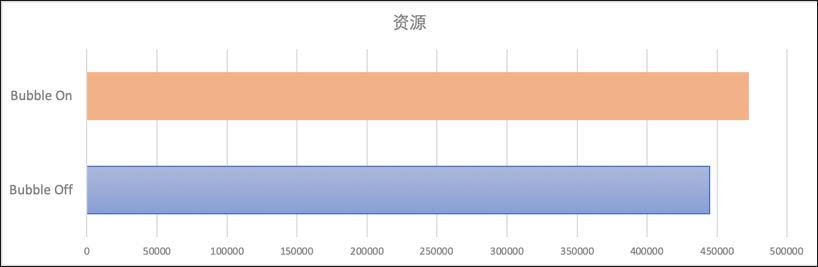
Fig 15. 执行性能/资源消耗对比
除了整体的对比之外,我们针对VIP用户也进行了针对性的分析,用户Project在打开了Bubble开关之后(下图中红色标记的点为打开Bubble的时间点),作业的平均执行性能有非常明显的提升。
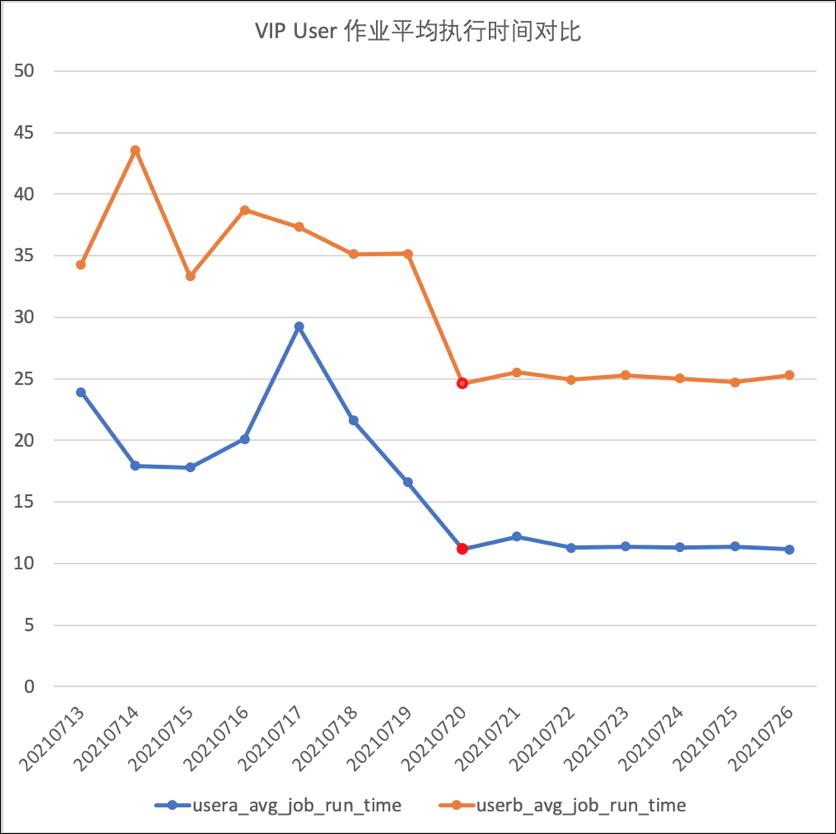
Fig 16. VIP用户开启Bubble后平均执行时间对比
本文为阿里云原创内容,未经允许不得转载。
以上是关于MaxCompute执行引擎核心技术DAG揭秘的主要内容,如果未能解决你的问题,请参考以下文章
Hologres揭秘:高性能原生加速MaxCompute核心原理