深度学习与图神经网络核心技术实践应用高级研修班-Day4深度强化学习(Deep Q-learning)
Posted ZSYL
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习与图神经网络核心技术实践应用高级研修班-Day4深度强化学习(Deep Q-learning)相关的知识,希望对你有一定的参考价值。
深度强化学习(Deep Q-learning)

1. 深度强化学习简介
- 传统的强化学习通常是使用马尔可夫决策过程来描述,它局限于动作空间与采样空间都很小,而且一般都是在离散空间中。
- 在实际情况中,输入往往是连续值(如图片,声音等),比如Flappy Bird游戏。
- 深度强化学习解决的正是强化学习在高维输入问题中遇到的困难。
2. DQN算法解析

3. DQN在游戏中的应用
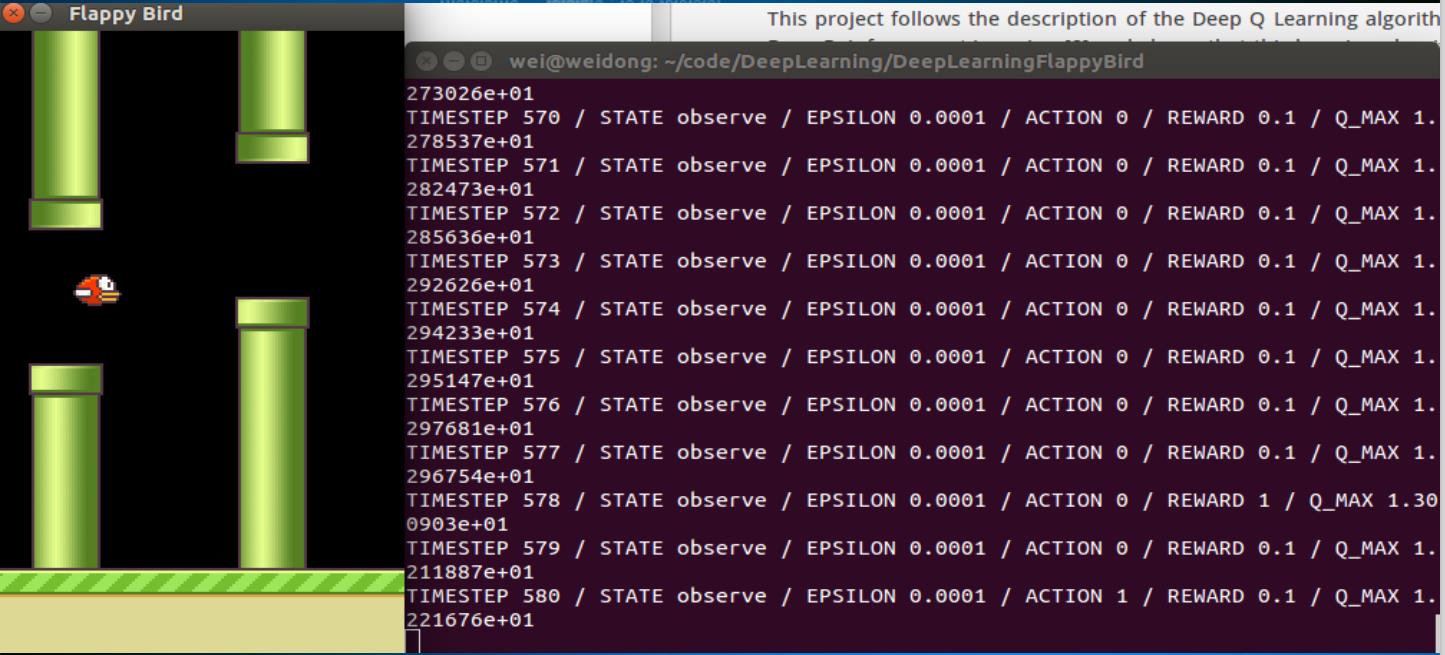
4. 代码讲解
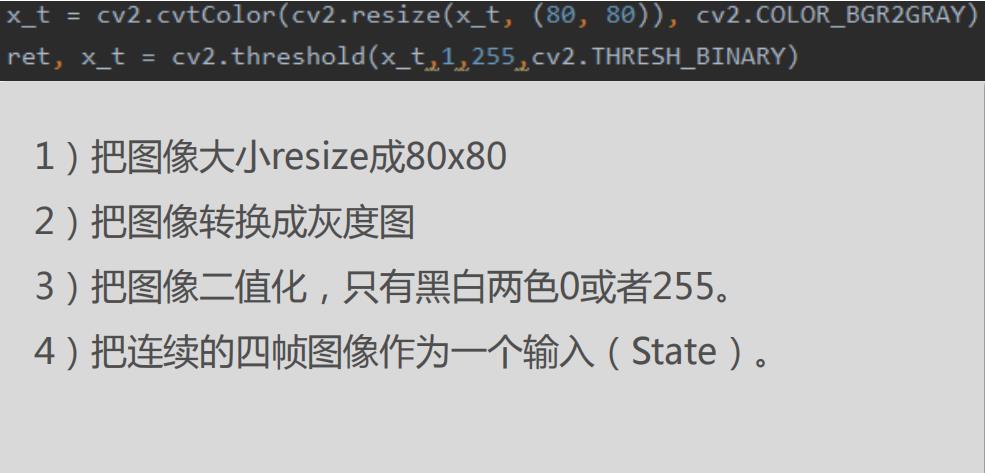
4.1 数据预处理

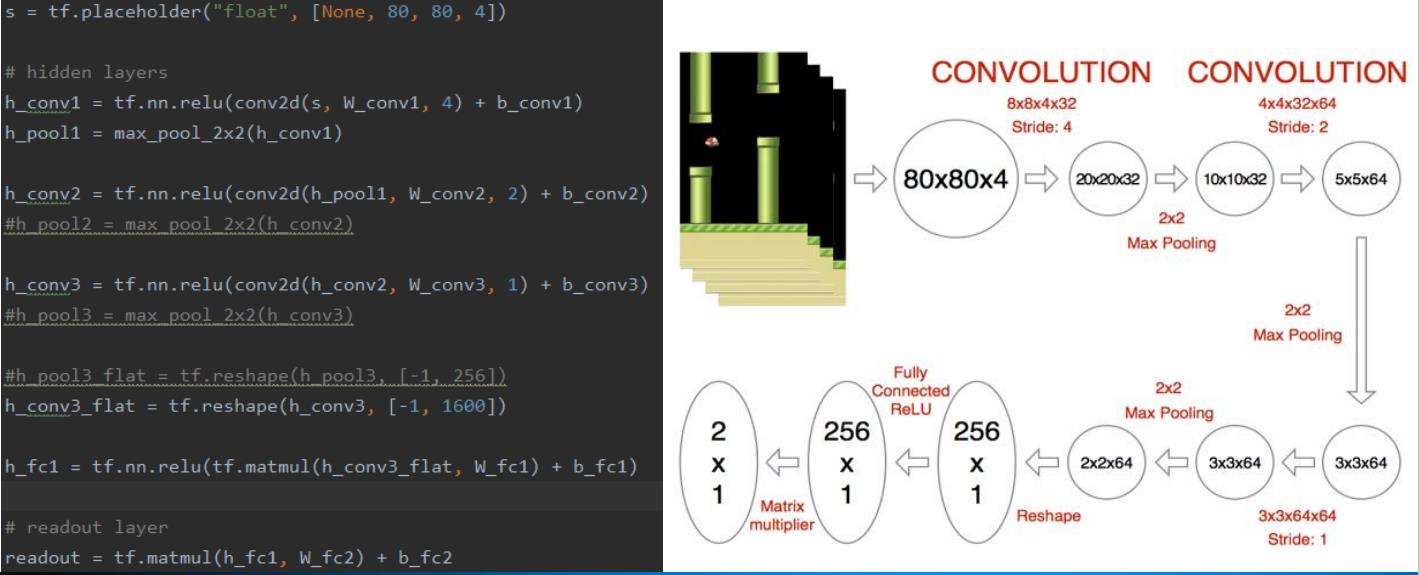
4.2 网络结构
4.3 Exploration & Exploitation
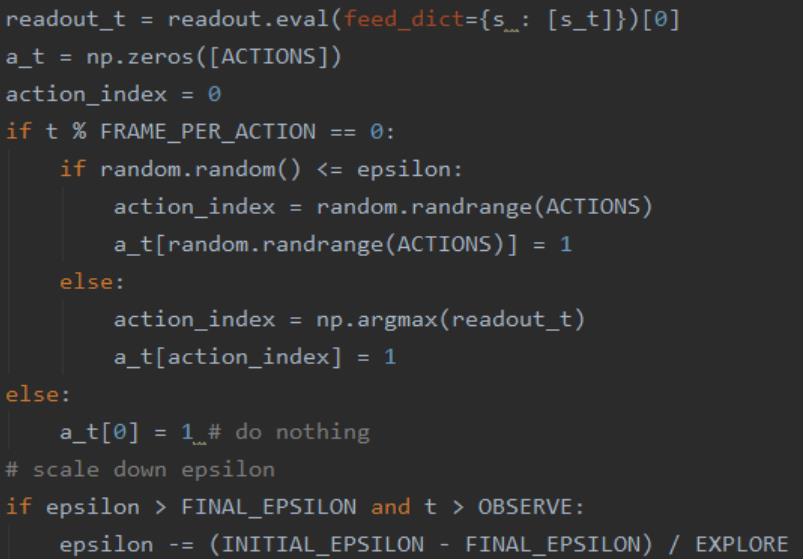
Exploration & Exploitation:探索与利用
前者强调发掘环境中的更多信息,并不局限在已知
的信息中;
后者强调从已知的信息中最大化奖励。
而greedy策略只注重了后者,没有涉及前者。
所以它并不是一个好的策略。
4.4 经验回放机制
监督学习的前提
- 独立同分布
经验回放机制
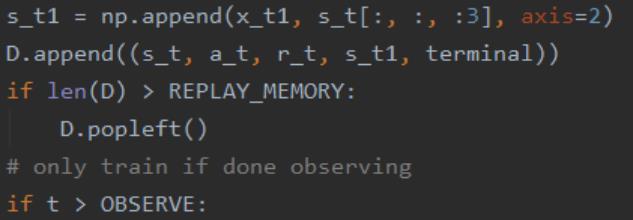
在强化学习中,观测数据是有序的,用这样的数据去更新神经网络的参数会有问题。而在监督学习中,数据之间都是独立的。
DQN中使用经验回放,即用一个Memory来存储经历过的数据,每次更新参数的时候从Memory中抽取一部分的数据来用于更新,以此来打破数据间的关联。
4.5 经验存储
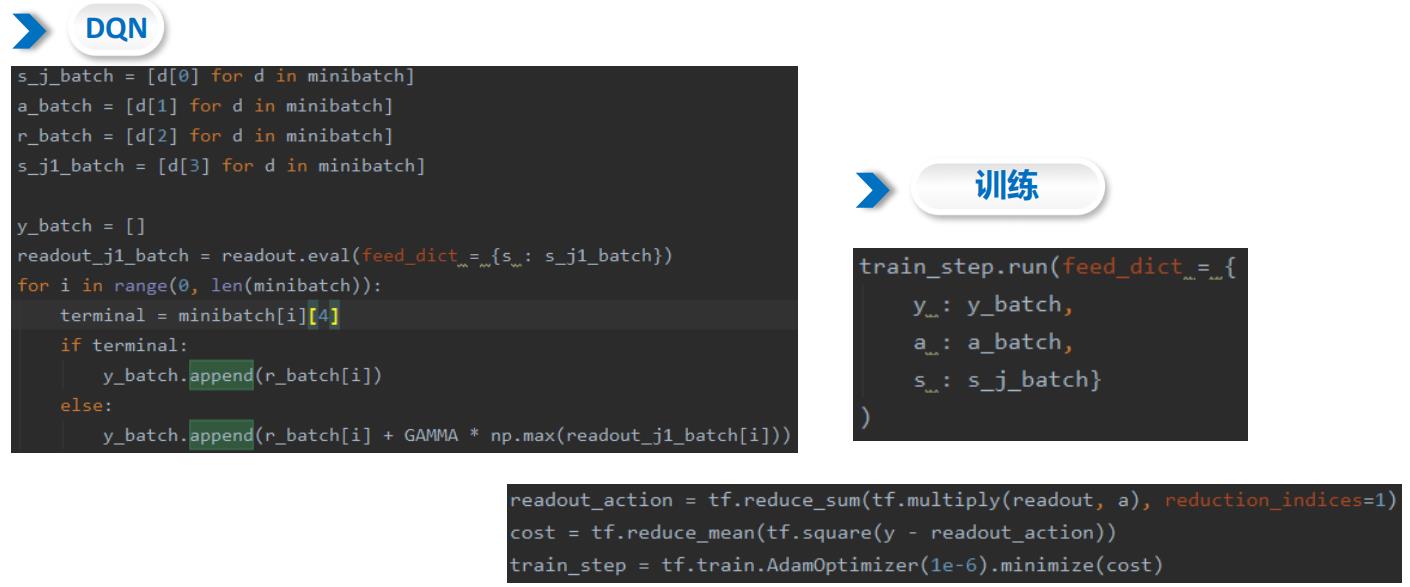
4.6 经验回放


以上是关于深度学习与图神经网络核心技术实践应用高级研修班-Day4深度强化学习(Deep Q-learning)的主要内容,如果未能解决你的问题,请参考以下文章
深度学习与图神经网络核心技术实践应用高级研修班-Day3迁移学习(Transfer Learning)
深度学习与图神经网络核心技术实践应用高级研修班-Day1典型深度神经网络模型
深度学习与图神经网络核心技术实践应用高级研修班-Day1Tensorflow和Pytorch
深度学习与图神经网络核心技术实践应用高级研修班-Day2基于Keras的深度学习程序开发