网络协议分析 | 应用层:HTTP协议详解HTTP代理服务器
Posted ·Jormungand
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了网络协议分析 | 应用层:HTTP协议详解HTTP代理服务器相关的知识,希望对你有一定的参考价值。
概念
先了解一下 因特网(Internet) 与 万维网(World Wide Web)。
因特网是使用 IP(Internet Protocol,因特网协议) 连接在一起的计算机构成的网络。因特网上有很多服务,包括万维网,以及电子邮件、文件共享、因特网电话等。因此,万维网(World Wide Web,简称Web)只是因特网上的一种服务形式。
Tim Berners-Lee 当初发明万维网时,一共创造了三项核心技术:
- HTTP协议: 超文本传输协议,是用于从 万维网服务器 传输 超文本 到 本地浏览器 的传送协议。
- URL(Uniform Resource Locator): 统一资源定位符,用于标识唯一资源,也就是我们通常所说的网址。
- HTML(Hypertext Markup Language): 超文本标记语言,用于构造网页的。
说到HTTP,其实主要是说万维网。但随着越来越多的服务甚至一些没有 传统Web前端界面 的服务开始使用HTTP,这个界限变得越来越模糊。比如,你可以在自己的手机应用中通过HTTP向家里的灯发出开或关的指令。
那么日常中浏览器向web服务器请求网页时交互过程是怎样的呢?
- 浏览器根据
DNS(Domain Name System,域名系统)服务器返回的真实地址请求网页。DNS主要负责把对人类友好的域名www.google.com转换为对机器友好的IP地址。
PS:我们常说的网址和域名有什么区别?比如https://www.baidu.com/这就是一个网址,而域名指的是www.baidu.com这一部分。 - 浏览器请求计算机建立对这个
IP地址的标准Web端口(80,QUIC协议常用)或标准安全Web端口(443,HTTPS协议常用)的TCP(Transmission Control Protocol,传输控制协议)连接。 - 浏览器连接到
Web服务器之后会请求网站。这一步就要用到HTTP了,具体细节我们在下面讨论。现在,只需知道浏览器会使用HTTP向Google的服务器请求Google主页就行了。 web服务器会根据请求的URL响应相关内容。访问成功会返回html格式的网页文本,访问错误则会返回对应的HTTP响应码。Web浏览器负责处理返回的响应。假设返回的响应是HTML,则浏览器就会解析HTML中的代码,并在内存中构建DOM(Document Object Model,文档对象模型),一种页面的内部表现形式。处理期间,浏览器可能会发现正常显示页面还需要 其他资源(比如CSS、javascript和图片)。- 如果正常显示页面还需要其他资源,
Web浏览器会请求自己需要的额外资源。而每次请求额外资源时,都必须重复1~6步。这是导致上网慢的一个重要因素,因而催生了HTTP/2,其主要目的是使得请求多资源时更有效率。 - 浏览器在获取了足够的关键资源后,开始在屏幕上渲染页面。但是,选择在屏幕上渲染的时机又是一个挑战:如果浏览器等到所有资源都下载完毕才渲染,那么用户就要等很久才能看到网页,上网的体验会很差。相反,如果浏览器过早渲染页面,那么伴随着更多资源下载,页面结构也会跳来跳去。假如你正在阅读一篇文章,而页面突然抖动了一下,你不生气才怪。
- 在页面刚刚显示在屏幕上之后,浏览器会在后台继续下载其他资源,并在处理完它们之后更新页面。这些资源包括不那么重要的图片和广告追踪脚本。因此,我们经常会看到网页刚显示时并没有图片(特别是在网速比较慢的情况下),而过了一会儿图片才慢慢下载并显示出来。
- 当页面完全被加载后,浏览器会停止显示加载图标(在多数浏览器上都位于地址栏旁边),然后触发
OnLoad JavaScript事件。根据这个事件,JavaScript就知道可以执行某些操作了。 - 此时,页面已经完全加载了,但浏览器并不会停止发送请求。 网页只包含静态内容的时代早就过去了。如今的很多网页其实已经是功能齐全的应用了,因此接下来浏览器还会发送或加载更多内容。
- 这些内容有的来自用户输入,比如你在
Google主页的搜索框中填写了一个关键字,但没有按搜索按钮就立即看到了搜索建议; - 有的来自应用驱动的操作,比如你的
QQ或者微博动态,不需要你点击刷新按钮就能自动刷新。
这些操作通常在后面悄悄发生,你看不到它们,特别是广告分析脚本,它会跟踪你在网站上的操作,并将该信息发送给站长或者广告服务商。
- 这些内容有的来自用户输入,比如你在
URL
URL:统一资源定位符,用于在网络中定位某台主机上的某一个资源,
URL由以下几部分组成
协议 :// 用户名 : 密码 @ 服务器IP地址 : 服务器端口 / 文件路径 ? 查询字符串 # 片段标识符
- 协议: 请求需要使用的协议,现在通常为
HTTP、HTTPS。 - 用户名密码: 认证用户的用户名密码,为了安全一般都不会显示。
- 服务器地址: 这里通常都不会是IP地址,而是域名,通过域名解析服务器(DNS服务器)就能够得到服务器的IP地址。
- 服务器端口: HTTP协议的端口默认是80,但也可以选择其他的,默认是不显示的。
- 文件路径: 即请求的资源在服务器上的存储路径。
- 查询字符串: 客户端请求中的额外参数,由
key=value的键值对组成,以&作为分隔符。 - 片段标识符: HTML的
标签id,可以直接跳转到页面的某个位置。
以B站为例:

对于 ? # / : 等特殊字符,会通过 urlencode 的方式进行转义。转义的规则如下:
将需要转码的字符转为 16进制 ,然后从右到左,取 4位(不足4位直接处理) ,每 2位 做 1位,前面加上 % ,编码成 %XY 格式
举例:
-
当我们在百度中搜索时:

-
但是如果我们将网址复制出来就会成这样:
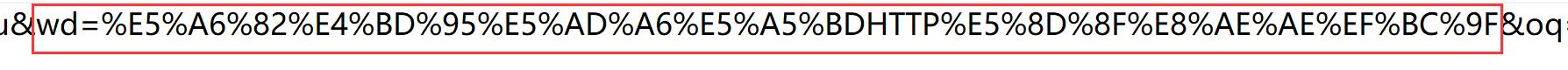
这种将 特殊字符(包括汉字) 转变为 16进制的额过程被称为 urlencode ,反过来就是一个 urldecode 过程。
HTTP协议的特点
-
HTTP是无连接:
无连接的含义是限制每次连接只处理一个请求。服务端处理客户端的请求,并收到客户的应答后,即断开连接。采用这种方式可以节省传输时间,亦不用花费资源维护连接。 -
HTTP是灵活的:
只要客户端和服务器知道如何处理的数据内容,任何类型的数据都可以通过HTTP发送。通过头部中的Content-Type来标记正在传输的类型 -
HTTP是无状态的:
无状态是指对于事务处理没有记忆能力,服务器不知道客户端是什么状态,即我们给服务器发送 HTTP 请求之后,服务器会根据请求给我们发送数据过来,但是发送完后不会记录任何信息。
无状态是一把双刃剑,如果处理当前请求时需要之前的信息,则必须重传,这样可能导致每次连接传送的数据量增大。而如果服务器不需要先前信息时,它的应答就较快。
HTTP协议版本
HTTP协议有 5 个版本,分别是 0.9、1.0、1.1、2.0、3.0 。
0.9版本:
- 这时的HTTP协议 没有标准格式 ,仅用于传输HTML(超文本标记语言)数据。
- 请求方法只有
GET。 - 连接方式为 短连接: 建立连接,发送一个请求,得到相应后关闭连接。

1.0版本:
- 正式规定了HTTP协议格式,支持不同文件格式的数据流.
- 同时部分应用商已经开始使用 优化的短连接: 一次连接可以发送多条请求。
- 定义了三种请求方法:
GET、POST和HEAD方法。

1.1版本:
- 增加了更多的请求方法和头部描述信息,并支持长连接和管线化传输。
- 新增了五种请求方法:
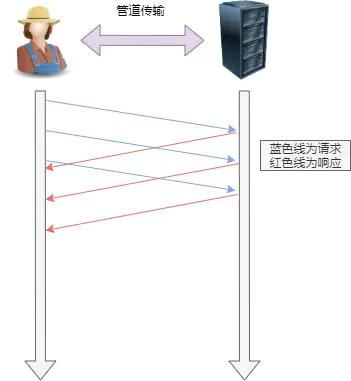
OPTIONS、PUT、DELETE、TRACE和CONNECT方法 - 管线化传输:可以连续发送多个请求,只要 按顺序响应 就行,不需要响应后才发下一个请求。
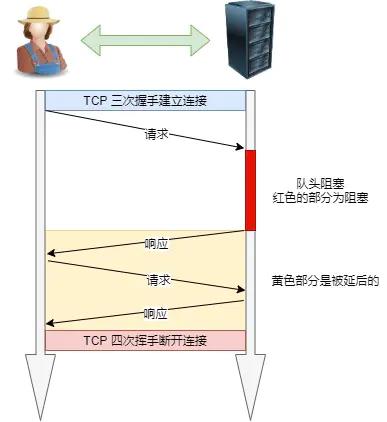
但是还存在约束条件,响应的顺序必须与请求的顺序保持一致,通过队列实现,如果不一致则在 队首阻塞 。
队头阻塞: 当顺序发送的请求序列中的一个请求因为某种原因被阻塞时,在后面排队的所有请求也一同被阻塞了,导致客户端一直请求不到数据。
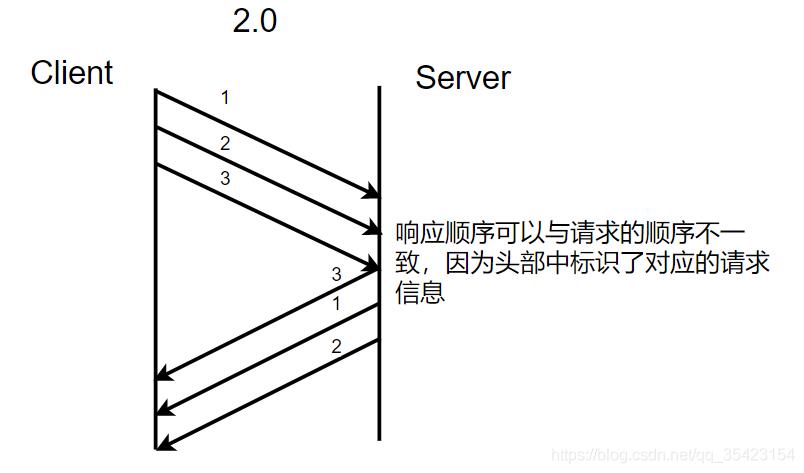
2.0版本:
- 采用二进制流传输,并且进行多路复用,允许服务端主动推送数据。
- 多路复用:响应顺序可以与请求的顺序不一致,因为头部中标识了对应的请求信息,提高了信道的利用率。
3.0版本:
在 3.0 版本中 HTTP 采取了革命性的变化,其将网络协议从 TCP 切换至 QUIC (Quick UDP Internet Connections), 快速 UDP 互联网连接。 QUIC 是基于 UDP协议 的。
QUIC 协议主要解决了两个问题:
- 线头阻塞问题: 基于
TCP的HTTP2.0的多路复用机制,尽管从逻辑上来说,不同的流之间相互独立,不会相互影响,但在实际传输方面,数据还是要一帧一帧的发送和接收,一旦某一个流的数据有丢包,则同样会阻塞在它之后传输的流数据传输。而基于UDP的QUIC协议则可以更为彻底地解决这样的问题,让不同的流之间真正的实现相互独立传输,互不干扰。 - 切换网络时的连接保持: 当前移动端的应用环境,用户的网络可能会经常切换,比如从办公室或家里出门,WiFi断开,网络切换为移动网络。基于TCP的协议,由于切换网络之后,IP会改变,因而之前的连接不可能继续保持。而基于UDP的QUIC协议,则可以内建与TCP中不同的连接标识方法,从而在网络完成切换之后,恢复之前与服务器的连接。
格式
请求报文
HTTP报文由 从客户机到服务器的请求 和 从服务器到客户机的响应 构成。请求报文格式如下:

首行
[请求方法] [URL] [协议版本]\\r\\n

| 请求方法 | 功能 |
|---|---|
| GET | 请求指定的页面信息,并返回实体主体。一般将数据放到 URL 中. |
| HEAD | 类似于 GET 请求,只不过返回的响应中没有具体的内容,用于获取报头。 |
| POST | 向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在 请求正文 中。POST请求可能会导致新的资源的建立 和/或 已有资源的修改。 |
| PUT | 从客户端向服务器传送的数据取代指定的文档的内容。 |
| DELETE | 请求服务器删除指定的页面。 |
| CONNEC | HTTP/1.1 协议中预留给能够将连接改为管道方式的代理服务器。 |
| OPTIONS | 允许客户端查看服务器的性能。 |
| TRACE | 回显服务器收到的请求,主要用于测试或诊断。 |
| PATCH | 是对 PUT方法的补充,用来对已知资源进行局部更新 。 |
头部
描述本次请求的关键字段信息,由 key:value 形式的键值对组成,并且每个键值对以 \\r\\n 作为结尾。

HTTP请求报文常用的Header:
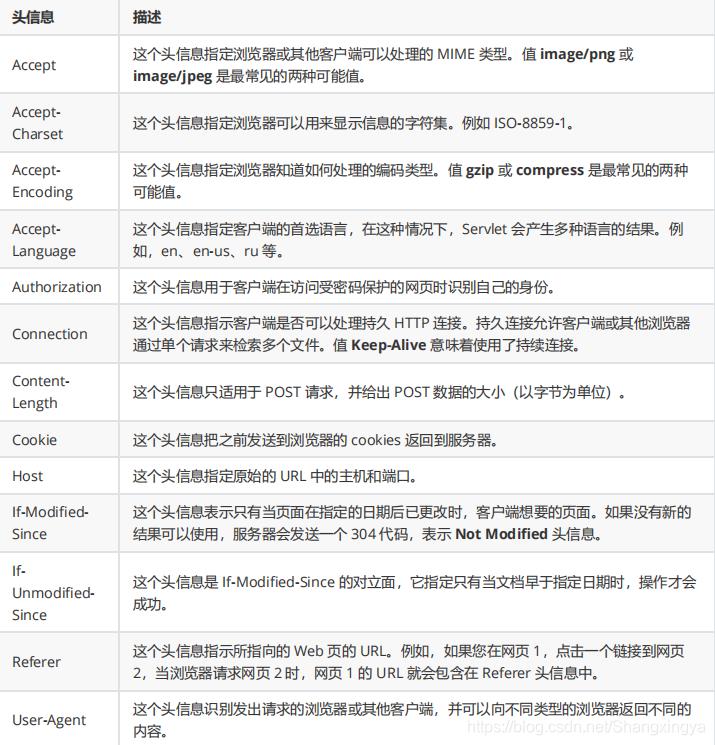
空行
空行即为 \\r\\n,用于间隔头部和正文。因为头部的每一个键值对以 \\r\\n 结束,所以一旦连续接受到两个 \\r\\n 的时候就代表着头部的接收结束。
正文
客户端提交的数据,允许为空字符串。

响应报文
响应报文格式如下:
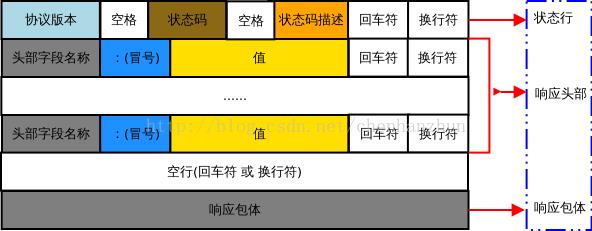
首行
[协议版本] [响应状态码] [响应状态码描述]\\r\\n

响应状态码: 对于本次请求,服务端做出的响应结果。
状态码描述: 对状态码的描述信息,可自定义。
HTTP的响应状态码:
| 消息 | 描述 |
|---|---|
| 1XX Informational | 信息状态码,表示接受的请求正在处理。 |
| 100 Continue | 服务器仅接收到部分请求,但是一旦服务器并没有拒绝该请求,客户端应该继续发送其余的请求。 |
| 101 Switching Protocols | 服务器转换协议:服务器将遵从客户的请求转换到另外一种协议。 |
| 2XX Success | 成功状态码,表示请求正常处理完毕。 |
| 200 OK | 请求成功(其后是对 GET 和 POST 请求的应答文档。) |
| 201 Created | 请求被创建完成,同时新的资源被创建。 |
| 202 Accepted | 供处理的请求已被接受,但是处理未完成。 |
| 203 Non-authoritative Information | 文档已经正常地返回,但一些应答头可能不正确,因为使用的是文档的拷贝。 |
| 204 No Content | 没有新文档。浏览器应该继续显示原来的文档。如果用户定期地刷新页面,而 Servlet 可以确定用户文档足够新,这个状态代码是很有用的。 |
| 205 Reset Content | 没有新文档。但浏览器应该重置它所显示的内容。用来强制浏览器清除表单输入内容。 |
| 206 Partial Content | 客户发送了一个带有 Range 头的 GET请求 ,服务器完成了它。 |
| 3XX Redirection | 重定向状态码,需要进行附加操作以完成请求。 |
| 300 Multiple Choices | 多重选择。链接列表。用户可以选择某链接到达目的地。最多允许五个地址。 |
| 301 Moved Permanently | 所请求的页面已经转移至新的 URL 。 |
| 302 Found | 所请求的页面已经临时转移至新的 URL 。 |
| 303 See Other | 所请求的页面可在别的 URL 下被找到。 |
| 304 Not Modified | 未按预期修改文档。客户端有缓冲的文档并发出了一个条件性的请求(一般是提供 If-Modified-Since 头表示客户只想要比指定日期更新的文档)。服务器告诉客户,原来缓冲的文档还可以继续使用。 |
| 305 Use Proxy | 客户请求的文档应该通过Location头所指明的代理服务器提取。 |
| 306 Unused | 此代码被用于前一版本。目前已不再使用,但是代码依然被保留。 |
| 307 Temporary Redirect | 被请求的页面已经临时移至新的 URL 。 |
| 4XX Client Error | 客户端状态错误码:表示服务器无法处理请求。 |
| 400 Bad Request | 服务器未能理解请求。 |
| 401 Unauthorized | 被请求的页面需要用户名和密码。 |
| 401.1 | 登录失败。 |
| 401.2 | 服务器配置导致登录失败。 |
| 401.3 | 由于 ACL(访问控制列表) 对资源的限制而未获得授权。 |
| 401.4 | 筛选器授权失败。 |
| 401.5 | ISAPI/CGI 应用程序授权失败。 |
| 401.7 | 访问被 Web服务器 上的 URL 授权策略拒绝。这个错误代码为 IIS 6.0 所专用。 |
| 402 Payment Required | 此代码尚无法使用。 |
| 403 Forbidden | 对被请求页面的访问被禁止。 |
| 403.1 | 执行访问被禁止。 |
| 403.2 | 读访问被禁止。 |
| 403.3 | 写访问被禁止。 |
| 403.4 | 要求 SSL(安全套接字协议) 。 |
| 403.5 | 要求 SSL 128位证书 。 |
| 403.6 | IP地址被拒绝。 |
| 403.7 | 要求客户端证书。 |
| 403.8 | 站点访问被拒绝。 |
| 403.9 | 用户数过多。 |
| 403.10 | 配置无效。 |
| 403.11 | 密码更改。 |
| 403.12 | 拒绝访问映射表。 |
| 403.13 | 客户端证书被吊销。 |
| 403.14 | 拒绝目录列表。 |
| 403.15 | 超出客户端访问许可。 |
| 403.16 | 客户端证书不受信任或无效。 |
| 403.17 | 客户端证书已过期或尚未生效。 |
| 403.18 | 在当前的应用程序池中不能执行所请求的 URL 。这个错误代码为 IIS 6.0 所专用。 |
| 403.19 | 不能为这个应用程序池中的客户端执行 CGI 。这个错误代码为 IIS 6.0 所专用。 |
| 403.20 | Passport 登录失败。这个错误代码为 IIS 6.0 所专用。 |
| 404 Not Found | 服务器无法找到被请求的页面。 |
| 404.0 | (无)–没有找到文件或目录。 |
| 404.1 | 无法在所请求的端口上访问Web站点。 |
| 404.2 | Web服务扩展锁定策略阻止本请求。 |
| 404.3 | MIME 映射策略阻止本请求。 |
| 405 Method Not Allowed | 请求中指定的方法不被允许。 |
| 406 Not Acceptable | 服务器生成的响应无法被客户端所接受。 |
| 407 Proxy Authentication Required | 用户必须首先使用代理服务器进行验证,这样请求才会被处理。 |
| 408 Request Timeout | 请求超出了服务器的等待时间。 |
| 409 Conflict | 由于冲突,请求无法被完成。 |
| 410 Gone | 被请求的页面不可用。 |
| 411 Length Required | Content-Length(POST请求报文的长度) 未被定义。如果无此内容,服务器不会接受请求。 |
| 412 Precondition Failed | 请求中的前提条件被服务器评估为失败。 |
| 413 Request Entity Too Large | 由于所请求的实体的太大,服务器不会接受请求。 |
| 414 Request-url Too Long | 由于 URL 太长,服务器不会接受请求。当post请求被转换为带有很长的查询信息的get请求时,就会发生这种情况。 |
| 415 Unsupported Media Type | 由于媒介类型不被支持,服务器不会接受请求。 |
| 416 Requested Range Not Satisfiable | 服务器不能满足客户在请求中指定的Range头。 |
| 417 Expectation Failed | 执行失败。 |
| 423 | 锁定的错误。 |
| 5XX Server Error | 服务器状态错误码:表示服务器处理请求出错。 |
| 500 Internal Server Error | 请求未完成。服务器遇到不可预知的情况。 |
| 500.12 | 应用程序正忙于在Web服务器上重新启动。 |
| 500.13 | Web服务器太忙。 |
| 500.15 | 不允许直接请求 Global.asa 。 |
| 500.16 | UNC(通用命名规则) 授权凭据不正确。这个错误代码为 IIS 6.0 所专用。 |
| 500.18 | URL 授权存储不能打开。这个错误代码为 IIS 6.0 所专用。 |
| 500.100 | 内部 ASP(动态服务器设备) 错误。 |
| 501 Not Implemented | 请求未完成。服务器不支持所请求的功能。 |
| 502 Bad Gateway | 请求未完成。服务器从上游服务器收到一个无效的响应。 |
| 502.1 | CGI 应用程序超时。 |
| 502.2 | CGI 应用程序出错。 |
| 503 Service Unavailable | 请求未完成。服务器临时过载或宕机。 |
| 504 Gateway Timeout | 网关超时。 |
| 505 HTTP Version Not Supported | 服务器不支持请求中指明的HTTP版本。 |
头部
描述本次响应的关键字段信息,由 key:value 形式的键值对组成,并且每个键值对以 \\r\\n 作为结尾。

HTTP响应报文常用的Header:
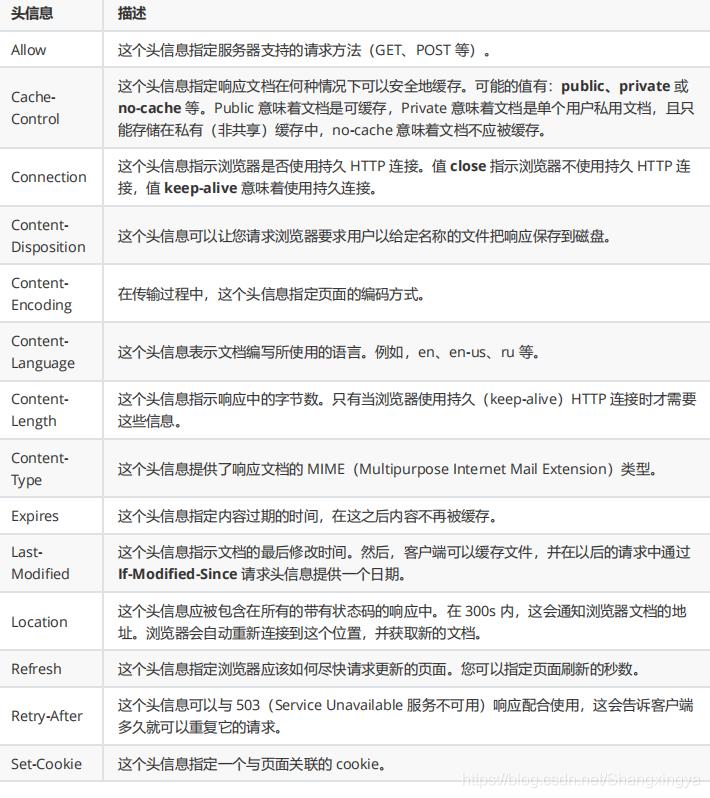
空行:同请求报文空行。
正文
服务端响应的实体资源

显示为乱码的原因是使用的是 HTTPS 协议,该协议会对响应的内容加密,中间者无法直接查看明文内容。
Cookie与Session
因为HTTP是无状态的,但在实际情况中,我们还是需要保持状态的。那么如何让HTTP来保持状态呢?答案就是借助 Header 中的 Cookie 和 Session 。
cookie 是什么?
Cookie 简单理解就是一个保存了用户信息的字符串。举个例子,618作为一个大型的购物节,在一天的不同时间段,不同店铺中,会有着许多不同的活动,为了达到最大折扣,我们通常会在一天内多次进入如淘宝、京东等购物网站进行购物,但是因为 HTTP 是无状态的,所以它并不会记录我们的任何信息,所以我们在每次访问时都需要重新登陆来确认用户的身份,这是一种很麻烦的事情。所以为 HTTP 加入了 Cookie 来帮助其维持状态。
Cookie 分为两类:
- 以文件方式存在硬盘空间上的
长期性的 cookie - 停留在浏览器所占内存中的
临时性的 cookie
有了 Cookie 之后,我们只需要一次登录就能够以 该登录状态 访问 同一域名的不同页面 ,没必要繁琐的每个页面都登录同样的用户以维持登陆状态。
cookie 的运作方式:
在每次通信后,会将 服务端的一些临时验证信息(比如常见的询问用户是否要保存登陆密码)保存在客户端的 cookie 文件中。这样下次通信时,就可以通过读取 cookie 中保存的验证信息,将其传递给服务端,来维持客户端的状态,这样就可以避免多次登录。
为什么需要 session ? 什么是 session ?
Cookie 的使用不够安全 ,因为 Cookie 保存在客户端(浏览器),很容易被脚本、爬虫等截取,所以 Cookie 需要搭配 Session 使用。
Session 其实就是服务端为客户端创建的一种信息管理机制,其中描述了客户端的身份认证信息和状态信息,并且将其保存在 服务端 。 服务端每次通信结束后都会将 Session id(本次会话的ID)保存在客户端的 Cookie 中,客户端在下次通信时通过 Cookie 将保存的 Session id 传递给服务端,这样服务端就可以通过对应的 Session id 来查找到客户端的身份认证信息和状态信息,来为客户端维持状态,避免重复登录。
如果客户端的浏览器禁用了 Cookie ,那么还能使用 Session 吗?
一般这种情况下,会使用一种叫做 URL重写 的技术来进行会话跟踪,即每次 HTTP 交互,URL 后面都会被附加上一个诸如 sid=xxxxx 这样的参数,服务端据此来识别用户。
Cookie 与 Session 的区别是什么?
- Cookie : 保存在客户端上的一种存储机制,用于持续与服务端进行信息传递的一种手段。
- Session: 保存在服务端上的一种数据结构,通过
Cookie传递Session id来查找到对应的 身份状态信息 ,来实现状态维持。
为什么 Session 要比 Cookie 更安全?
Session ID 是放在 Cookie 里,想要攻破 Session ,首先要破解 Cookie 。而即使得到 Session ID:
- 第一,
Session ID是要有人登录,或者启动session_start才会有,你不知道什么时候会有人登录。 - 第二,
Session ID是加密的,第二次session_start的时候,前一次的Session ID就失效了。换言之,Session是针对某一次通信而言,会话结束Session也就随着消失了,Session消失了Session ID也失效了,而想在短时间内破解加了密的Session ID是很难的。
HTTP代理服务器
在 HTTP通信链 上,客户端和目标服务器之间通常存在某些中转代理服务器。它们最基本的功能是连接,此外还包括安全性、缓存、内容过滤、访问控制管理等功能。一个 HTTP请求 可能被多个代理服务器转发,后面的服务器称为前面服务器的 上游服务器 。代理服务器分为:正向代理服务器、反向代理服务器、透明代理服务器。
正向代理服务器
概念
要求客户端自己设置代理服务器的地址。客户的每次请求都将直接发送到该代理服务器,并由代理服务器来请求目标资源。
处于防火墙内的局域网机器要访问 Internet,或者要访问一些被屏蔽掉的国外网站,就需要用到正向代理服务器。
优点
可以使用缓冲特性(由 mod_cache 提供)减少网络使用率
反向代理服务器
概念
被设置在服务器端,因而客户端无须进行任何设置。反向代理是指用代理服务器来接收 Internet 上的连接请求,然后将请求转发给内部网络上的服务器,并将从内部服务器上得到的结果返回给客户端。对于用户而言,反向代理服务器就相当于目标服务器。
各大网站通常分区域设置了多个代理服务器,所以在不同的地方 ping 同一个域名可能得到不同的 IP地址,因为这些 IP地址 实际上是 代服务器的IP地址 。
优点
- 可用来作为
Web加速: 即使用反向代理作为Web服务器的前置机来降低网络和服务器的负载,提高访问效率。
例如:在内部服务器前放置两台反向代理服务器,分别连接到教育网和公网,这样公网用户就可以直接通过公网线路访问学校服务器,从而避开了公网和教育网之间拥挤的链路。 - 提高内部服务器的安全性: 外部网络用户通过反向代理访向内部服务器,只能看到反向代理服务器的IP地址和端口号,内部服务器对于外部网络来说是完全不可见。而且反向代理服务器上没有保存任何的信息资源,所有的网页程序都保存在内部服务器上,对反向代理服务器的攻击并不能使真的网页信息系统受到破坏。
- 节约了有限的
IP资源: 校园网内部服务器除使用教育网地址外,也会采用公网的IP地址对外提供服务,公网分配的IP地址数目是有限的,如果每个服务器有分配-个公网地址,那是不可能的,通过反向代理技术很好的解决了IP地址不足的问题。
透明代理服务器
概念
透明代理只能设置在网关上,客户端根本不需要知道有代理服务器的存在,它改变你的 request fields(报文) ,并会传送 真实IP ,多用于路由器的 NAT转发 中。注意,加密的透明代理则是属于 匿名代理 ,意思是不用设置使用代理了,例如:Garden 2 程序。透明代理可以看作正向代理的一种特殊情况。
原理
假设 A 为内部网络客户机,B 为外部网络服务器,C 为防火墙。
- 当
A对B有连接请求时,TCP连接请求被防火墙C截取并加以监控。 - 截取后当发现连接需要使用代理服务器时,
A和C之间首先建立连接。 - 然后
防火墙C建立相应的代理服务通道与目标B建立连接。 - 由此通过
代理服务器C建立A和目标地址B的数据传输途径。
从用户的角度看,A 和 B 的连接是直接的,而实际上 A 是通过 代理服务器C 和 B 建立连接的。反之,当 B 对 A 有连接请求时原理相同。由于这些连接过程是自动的,不需要客户端手工配置代理服务器,甚至用户根本不知道代理服务器的存在,因而对用户来说是透明的。
以上是关于网络协议分析 | 应用层:HTTP协议详解HTTP代理服务器的主要内容,如果未能解决你的问题,请参考以下文章