Pyecharts“可视化大屏“,带你重温 “2020东京奥运会“,不看直播尽知其事!
Posted 数据分析与统计学之美
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Pyecharts“可视化大屏“,带你重温 “2020东京奥运会“,不看直播尽知其事!相关的知识,希望对你有一定的参考价值。
本文禁止其他人转载,违者必究!
目录
1、项目背景
2、奥运会相关信息爬取
① 导入相关库
② 爬虫代码完整讲解
3、数据预处理
① 数据替换
② 数据分组
③ 中英文名映射转换
4、可视化展示
① 2020东京奥运会各国金牌分布地图
② 2020东京奥运会奖牌榜详情堆积柱形图
③ 2020东京奥运会奖牌榜总数前十名柱形图
④ 2020东京奥运会金牌榜总数前十名柱形图
⑤ 2020东京奥运会中国各项目获奖详情饼图
⑥ 中国选手每日获得奖牌数折线图
⑦ 中国选手每日获得金牌数折线图
⑧ 中国选手夺金详细数据表格
⑨ 组合为可视化大屏
整体思路

1、项目背景
奥运会刚刚过去,你是否已经看过2020东京奥运会呢?本文将手把手带你爬取奥运会相关信息,并利用可视化大屏为你展示奥运详情。让一个没关注过奥运会的朋友,也能够秒懂奥运会。
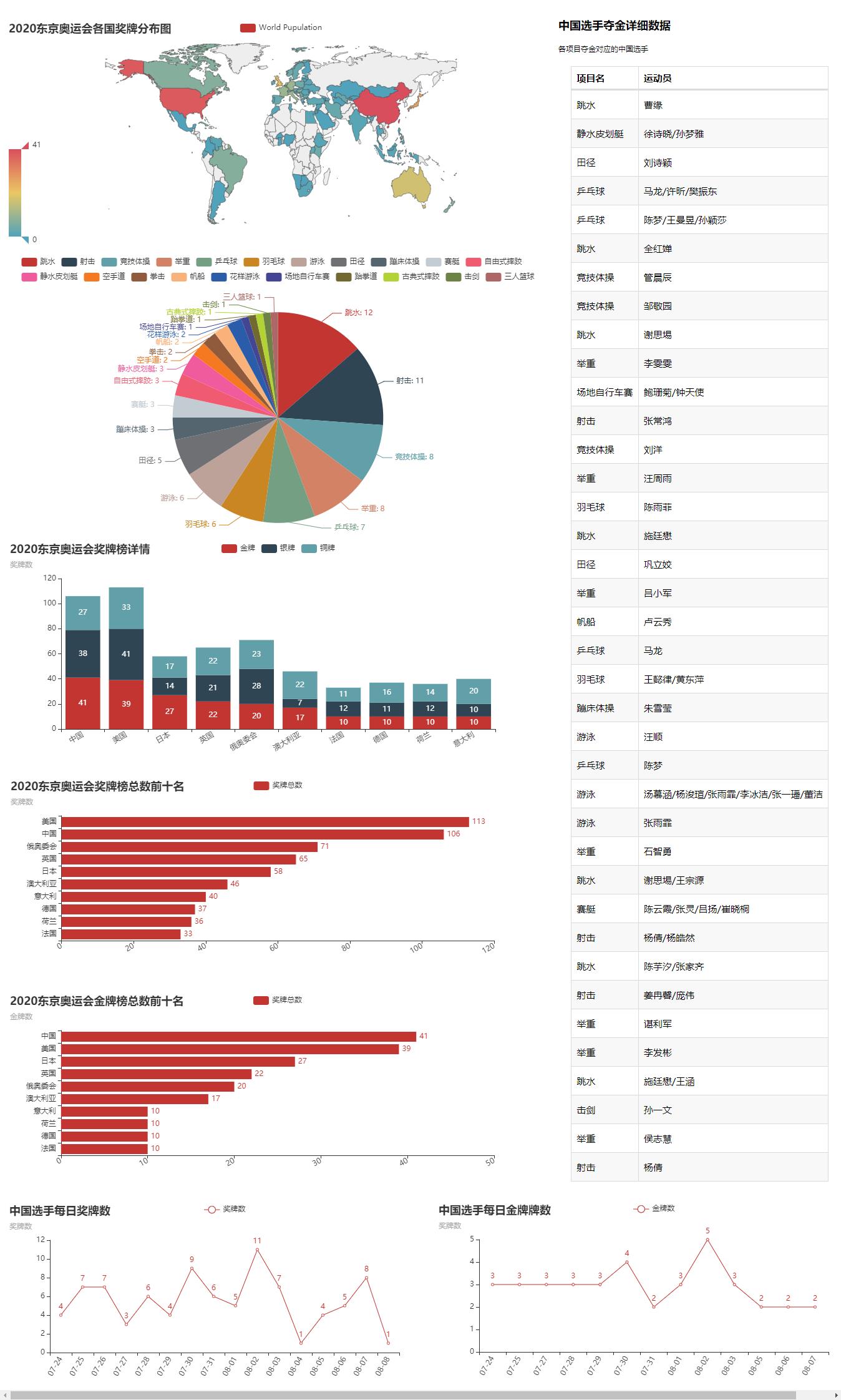
学完本文后,你将学会如下可视化大屏的制作。
2、奥运会相关信息爬取
- 爬取字段: 国家、国家ID、排名、金牌数、银牌数、铜牌数、奖牌总数、项目名、运动员、获奖类型、获奖时间;
- 爬取说明: 基于两个接口的数据爬取【json格式的数据】,直接采用键值对的方式获取相关数据;
- 使用工具: Pandas+requests
本文是基于两个接口的数据爬取,相对容易的多。
# 这个链接主要展示:各国的金银铜牌及其总数!
https://app-sc.miguvideo.com/vms-livedata/olympic-medal/total-table/15/110000004609
# 这个链接主要展示:每个参赛队员的参赛项目和获得的奖牌情况!
https://app-sc.miguvideo.com/vms-livedata/olympic-medal/total-table/15/110000004609
① 导入相关库
import requests
import pandas as pd
from pprint import pprint
requests库用于发起网页请求,获取网页中的源代码;pandas库用于存储和读取获取到的信息;pprint库是漂亮的打印,对于json格式的数据,能够很好的展示结构,方便我们解析;
② 爬虫讲解
url = 'https://app-sc.miguvideo.com/vms-livedata/olympic-medal/total-table/15/110000004609'
data = requests.get(url).json()
pprint(data)
三行代码就可以获取到网页的源代码,利用pprint库,可以清晰的展示json结构,对于我们解析数据很有帮助。
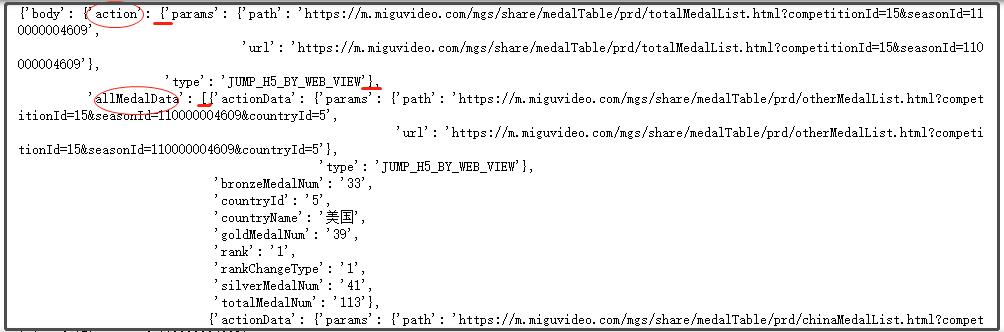
从图中可以很清晰地看到,我们要的数据,都存在于body键下面的allMedalData键中,allMedalData键的值是一个列表,里面有很多字典组成的键值对信息,就是我们要爬取的数据。
直接利用键获取对应的值信息,代码如下:
df1 = pd.DataFrame()
for info in data1['body']['allMedalData']:
name = info['countryName']
name_id = info['countryId']
rank = info['rank']
gold = info['goldMedalNum']
silver = info['silverMedalNum']
bronze = info['bronzeMedalNum']
total = info['totalMedalNum']
# 组织数据
orangized_data = [[name,name_id,rank,gold,silver,bronze,total]]
# 然后追加df
df1 = df1.append(orangized_data)
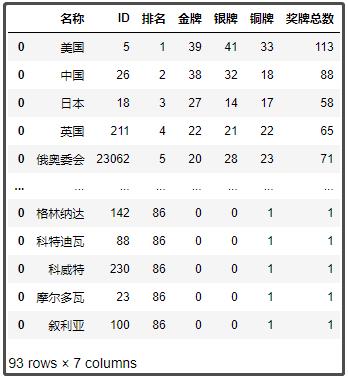
df1.columns = ['名称', 'ID', '排名', '金牌', '银牌', '铜牌', '奖牌总数']
df1
结果如下:
对于另外一个网页,我们采取同样的方式。
url = 'https://app-sc.miguvideo.com/vms-livedata/olympic-medal/detail-total/15/110000004609'
data2 = requests.get(url).json()
pprint(data2)
结果如下:

是不是此时感觉结构更清楚了?
df2 = pd.DataFrame()
for info in data2['body']['medalTableDetail']:
english_name = info['countryName']
name_id = info['countryId']
award_time = info['awardTime']
item_name = info['bigItemName']
sports_name = info['sportsName']
medal_type = info['medalType']
# 组织数据
orangized_data = [[english_name,name_id,award_time,item_name,sports_name,medal_type]]
# 然后追加df
df2 = df2.append(orangized_data)
df2.columns = ['英文缩写', 'ID', '获奖时间', '项目名', '运动员', '金牌类型']
df2
结果如下:

3、数据预处理
对于爬取到的数据,往往是有问题的,我们需要提前预处理一下,方便后续做可视化展示。
① 数据替换
对于上述爬取到的数据,我们做一个数据筛选。
df1 = pd.read_excel("各国奖牌数.xlsx")
df1[df1["名称"].str.contains("中国")]
结果如下:
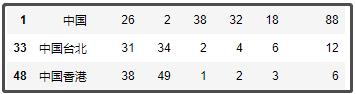
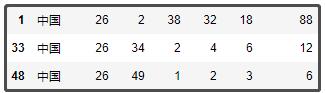
虽说中国香港、中国台湾都单独参加了奥运会,但她们都属于中国,我们将她们的都改为中国,ID也都改为26。
df1["名称"].replace(["中国台北","中国香港"],"中国",inplace=True)
df1["ID"].replace([31,38],26,inplace=True)
df1[df1["名称"].str.contains("中国")]
结果如下:
② 数据分组
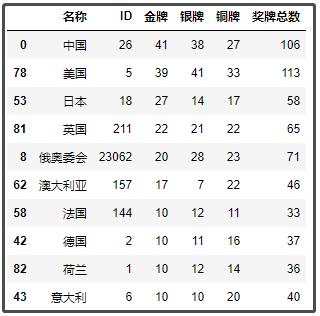
经过上述处理,那么中国就相当于有3条数据了。我们以名称+ID作为联合字段,进行分组,然后求和,将这3条数据进行合并。最后,再以金牌字段为基准,进行降序排列。
df2 = df1.groupby(["名称","ID"])[["金牌","银牌","铜牌","奖牌总数"]].sum().reset_index().sort_values(by="金牌",axis=0,ascending=False)
df2.head(10)
结果如下:
③ 中英文名映射转换
由于使用pyecharts绘制世界地图时,名称必须是英文的,所以我们需要将这里的中文名称映射为英文名称。于是我在网上找到了下面这个文件:
我们要做的就是将它与表格中的数据,做个映射转换。先把它转换为一个Excel文件吧,方便我们以后直接使用。
with open("国家名中英文对照表.txt","r",encoding="utf-8") as f:
x = f.read()
df3 = pd.DataFrame()
for i in x.split("\\n"):
x = i.split(":")[0].strip()
y = i.split(":")[1].strip()
orangined_data = [[x,y]]
df3 = df3.append(orangined_data)
df3.columns = ["名称","英文名称"]
df3.to_excel("国家名中英文对照表.xlsx",index=None)
然后,在和上述的df2表格做一个左连接即可。
df4 = pd.merge(df2,df3,on="名称",how="left")
df4
结果如下:

4、可视化展示
关于可视化部分,使用的是pyecharts库。这部分一共分以下8个主题:
- ① 2020东京奥运会各国奖牌分布图;
- ② 2020东京奥运会奖牌榜详情;
- ③ 2020东京奥运会奖牌榜总数前十名;
- ④ 2020东京奥运会金牌榜总数前十名;
- ⑤ 2020东京奥运会中国各项目获奖详情;
- ⑥ 中国选手每日获得奖牌数;
- ⑦ 中国选手每日获得金牌数;
- ⑧ 中国选手夺金详细数据;
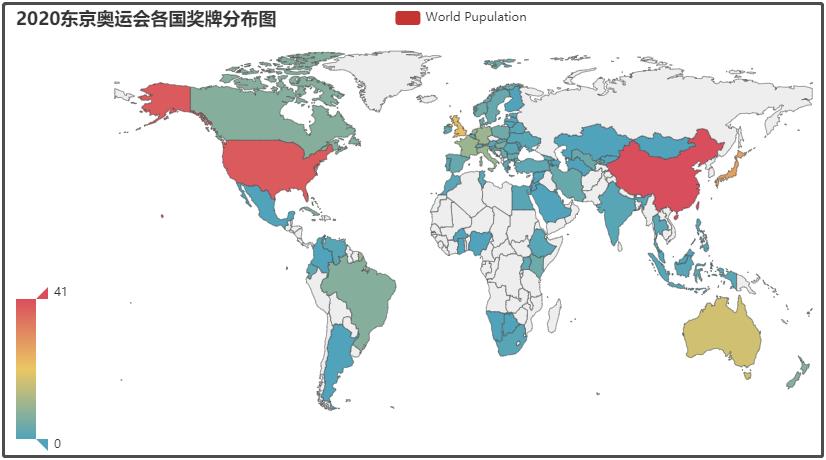
① 2020东京奥运会各国金牌分布图
② 2020东京奥运会奖牌榜详情

③ 2020东京奥运会奖牌榜总数前十名
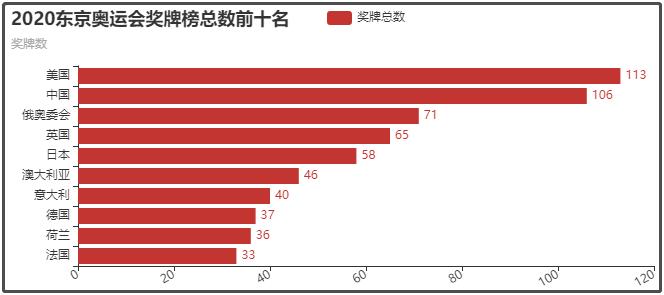
④ 2020东京奥运会金牌榜总数前十名

⑤ 2020东京奥运会中国各项目获奖详情
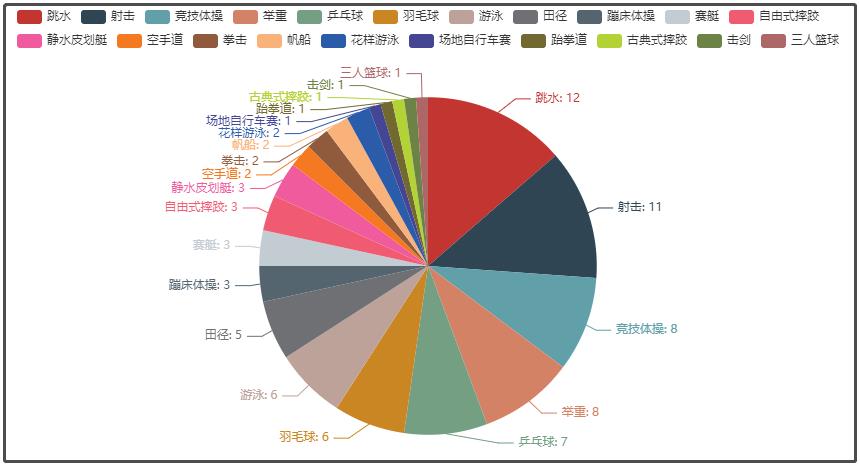
⑥ 中国选手每日获得奖牌数

⑦ 中国选手每日获得金牌数
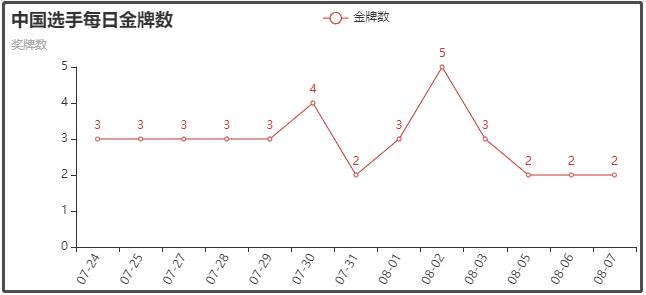
⑧ 中国选手夺金详细数据

⑨ 组合为可视化大屏

说明: 这里就不做结果分析了,因为通过上图,相信大家应该能够很清晰的了解到2020东京奥运会,哪怕你没看过。
以上是关于Pyecharts“可视化大屏“,带你重温 “2020东京奥运会“,不看直播尽知其事!的主要内容,如果未能解决你的问题,请参考以下文章