机器学习--入门介绍
Posted 胜天半月子
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习--入门介绍相关的知识,希望对你有一定的参考价值。
文章目录
两个定义
Machine Learning(机器学习)
定义一:ARTHUR SAMUL
- 什么是机器学习?

ARTHUR SAMUEL对机器学习的定义:

显著式编程⭐
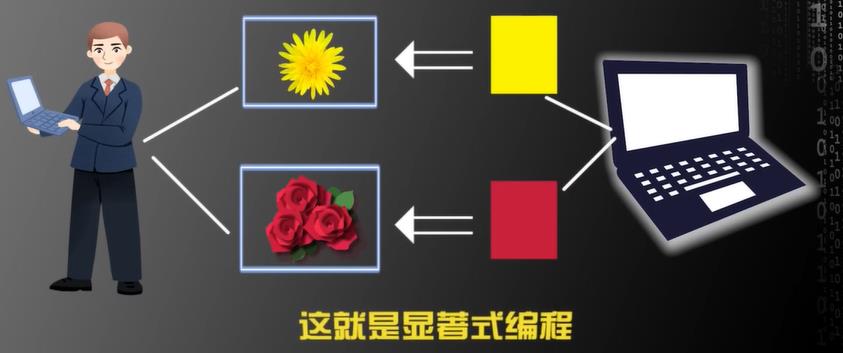
什么是显著式编程?
举例:我们要编程序让计算机自动区别菊花和玫瑰,如果我们人为的告诉计算机菊花是黄色,玫瑰是红色,所以计算机看到黄色识别为菊花、看到红色识别为玫瑰。
如果我们同时给计算机一堆菊花和玫瑰的图片,然后编写程序让计算机自己去总结菊花和玫瑰的区别,只要我们的程序没有问题,计算机很有可能通过大量的图片,也能总结出菊花是黄色的,玫瑰是红色的这个规律。计算也有可能总结出菊花的花瓣很长、玫瑰的而花瓣很圆等等规律!

我们实现并不越是计算机必须总结什么规律。而是让计算机自己挑出最能区分菊花和玫瑰的一些规律。
让计算机自己总结的规律的编程方法叫做非显著式编程。

- 总结
- 显著式编程

- 非显著式编程

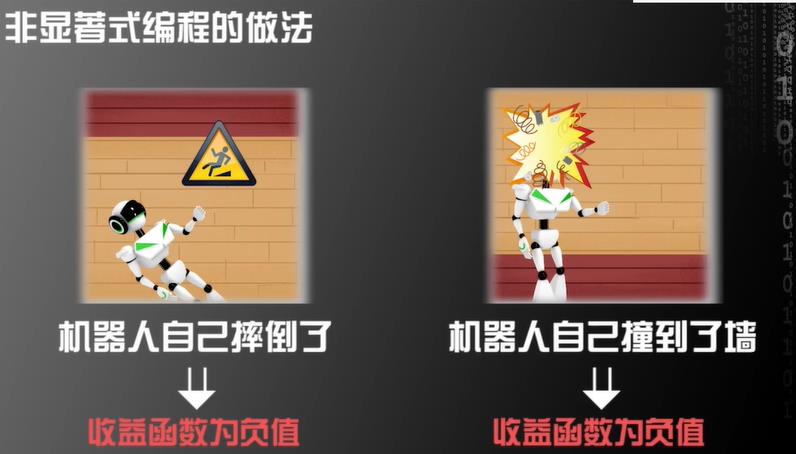

我们规定了行为和收益函数后,让计算机自己去找最大化收益函数的行为。
一开始,计算机采用随机化的行为,但是只要程序编的足够好,计算机是可能找到一个最大化收益函数的行为模式的
定义二:Tom Mitshell


- 举例一

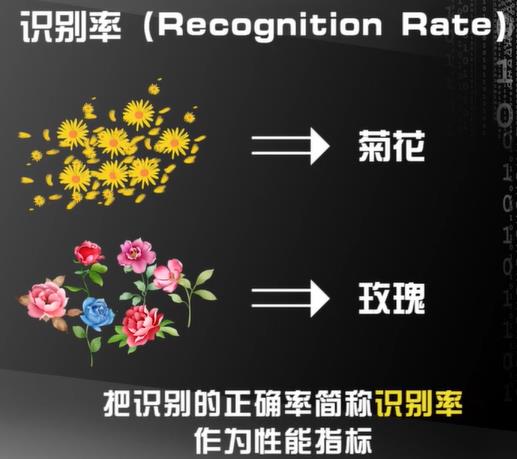

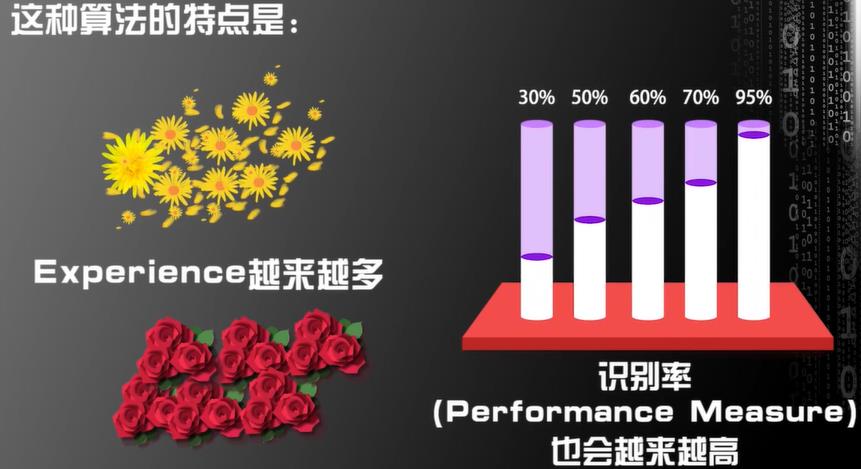
显著式编程是无法达到这一目的的,因为显著式编程定死了程序的输入和输出,识别率不会随着训练样本的增加而变化
- 举例二
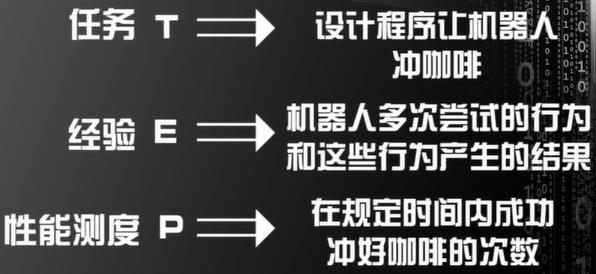
如果程序编写的机器学习程序的足够好,机器人在运行的过程中,收集的行为越多,机器人就可以通过以往的行为和经验进行学习,从而在规定的时间内获得更多的咖啡。



一、机器学习的分类

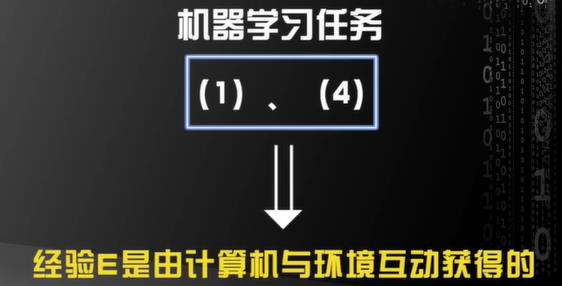
划分的标准? ==> 经验E
监督学习



我们把告诉计算机每一个训练样本是什么的过程:
为训练样本打标签
经验E ==》 训练样本和标签的集合
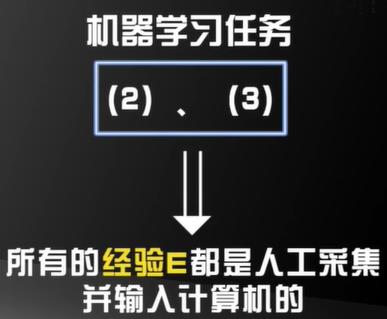
我们把这一类输入计算机训练数据同时加上标签的机器学习称为监督学习(Supervised Learning)
分类一

传统的监督学习
每一个训练数据都有对应的标签

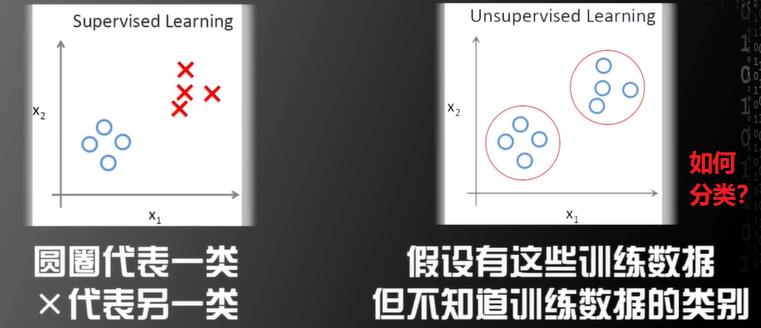
非监督学习
所有的训练数据都没有对应标签
为什么可能通过没有标签的训练数据获得类别信息?
- 解释


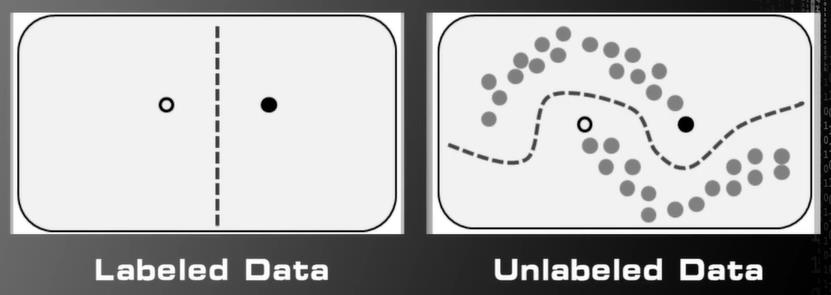
半监督学习⭐⭐
训练数据中一部分有标签一部分没有标签
该领域获得越来越多的关注,是因为随着网络的发展,网络中存在大量的数据,但是标注数据是成本巨大的工作。

- 举例
分类二
另一种分类是基于标签的固有属性
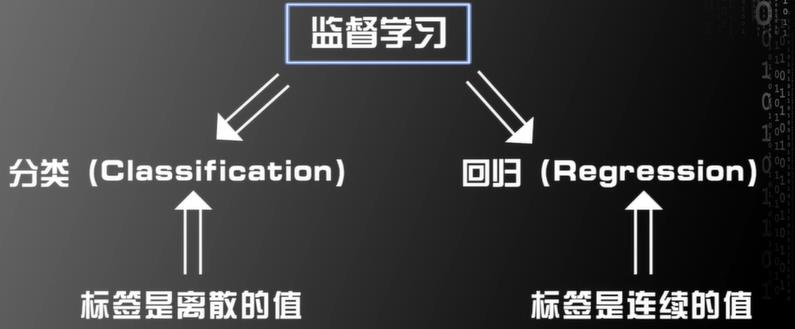
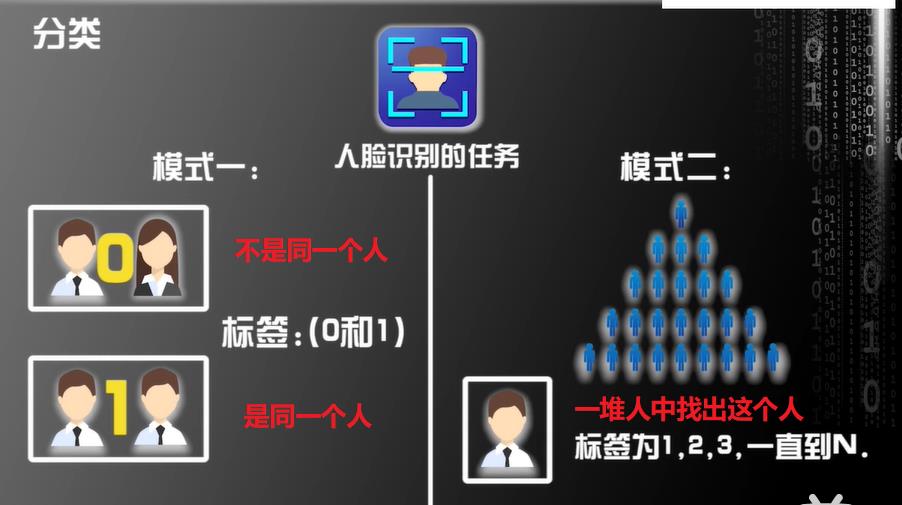
分类问题
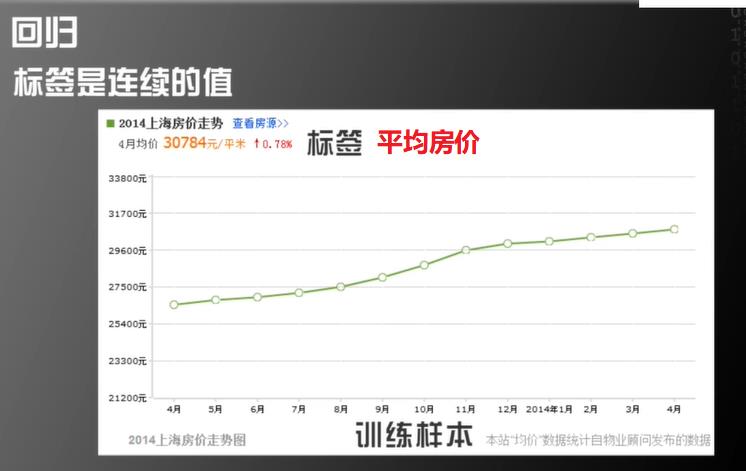
回归问题
标签是连续的数值
分类和回归问题的界限其实是非常模糊的,因为连续和离散问题的定义也是可以相互转换的,一个解决分类问题的机器学习模型稍加改造可以解决回归问题,反之亦然!

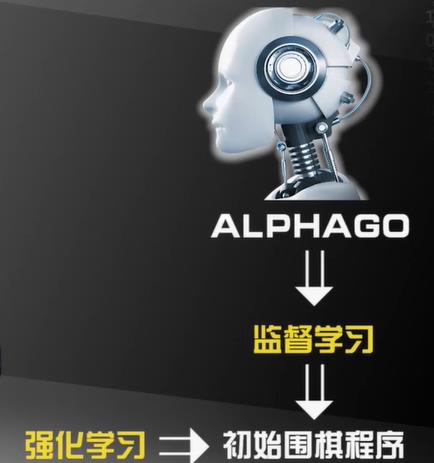
强化学习
Reinforcement Learning
让计算机通过与环境的互动逐渐强化自己的行为模式


总结

二、机器学习算法过程

- 观察数据,总结规律

第一步:特区特征(Feature Extraction)
特征提取:通过训练样本获得的,对机器学习任务有帮助的多维度数据

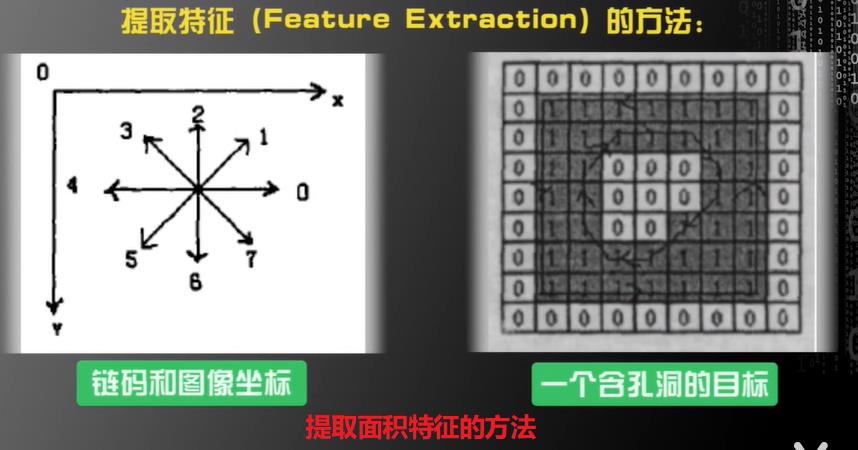


为什么不重点研究提取特征?
因为不同任务提取特征方式不同,例如图像、语音、点云等,因为不同媒质的属性不同导致提取特征的方式千变万化

第二步:特征选择(Feature Selection)
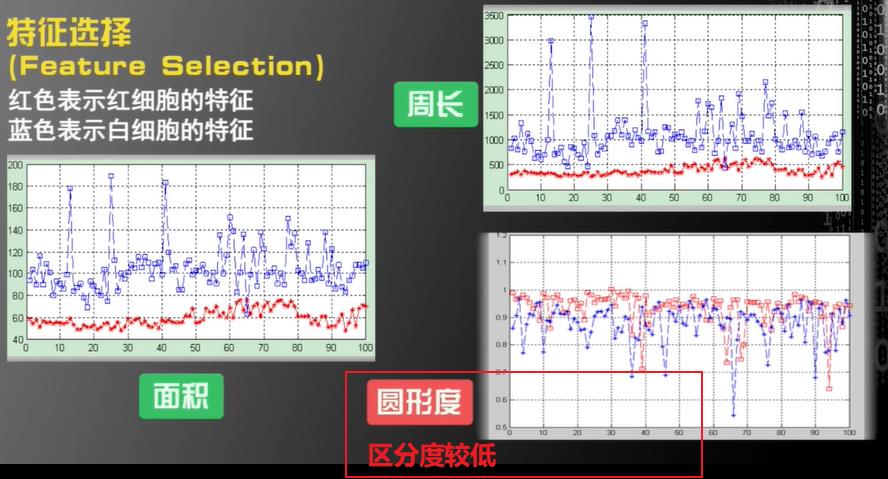
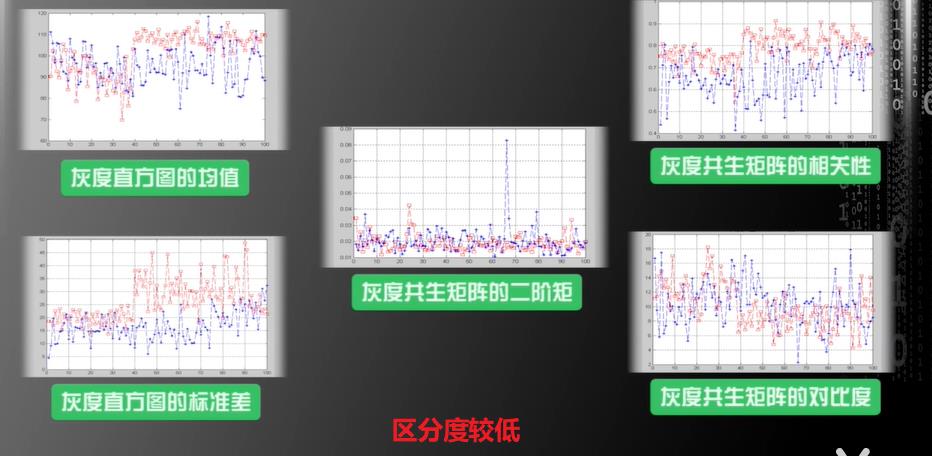
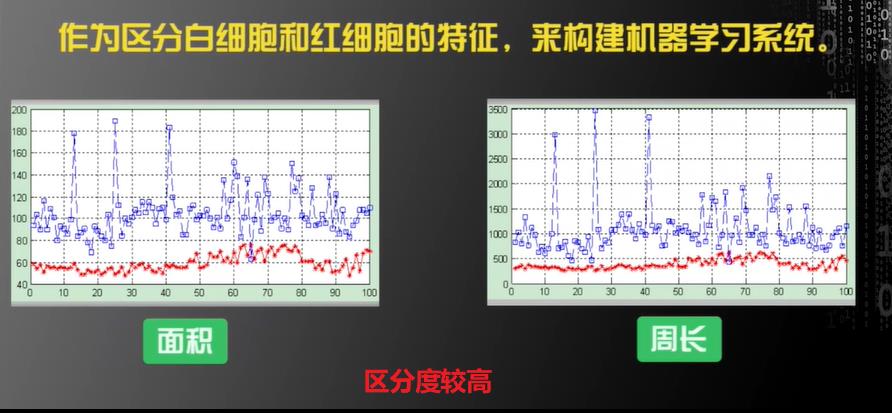
如何基于两个特征构建算法呢?
支持向量机
- 线性内核
- 多项式核
- 高斯径向基函数核
(可以简单认为三种不同算法)
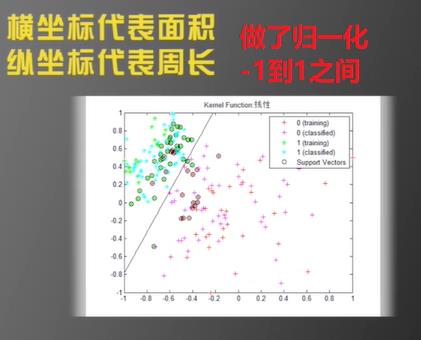
把这两个特征组成的二维平面叫做特征空间(Feature Space),如果多个特征,则可以高于二维。
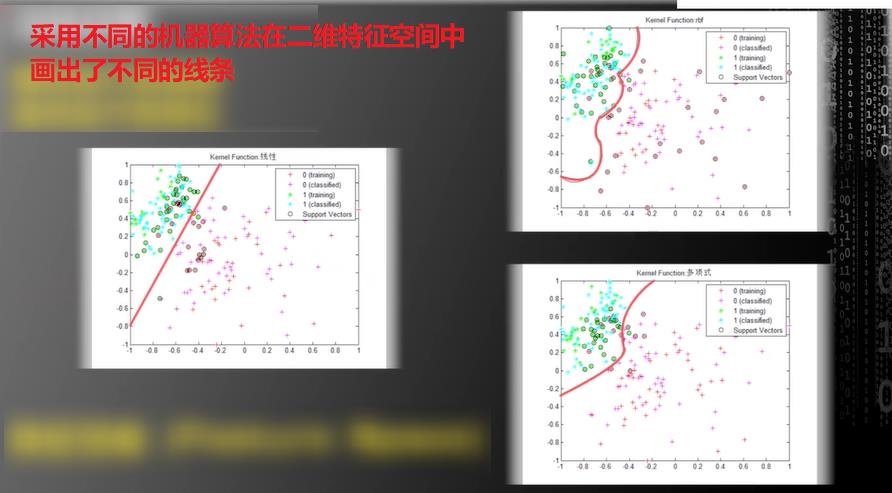
一旦画出这条线,机器学习的过程已经完成了。
因为只要有一个细胞的数据通过特征分析以及落点区域即可判断细胞类别。
维度
人眼对于超过三维的世界缺乏想象力
标准
对某一区域的划分标准不一样的
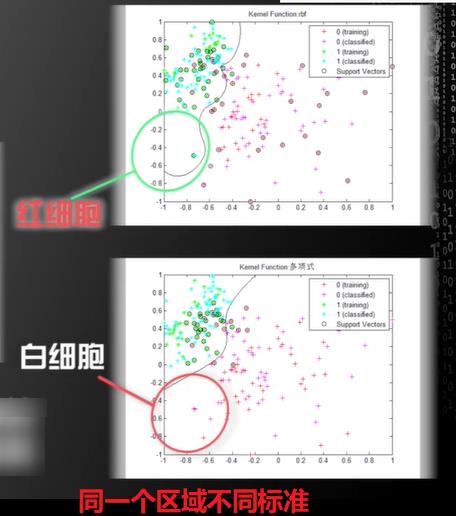
所以我们不能得出一个绝对意义的好和坏的标准。,
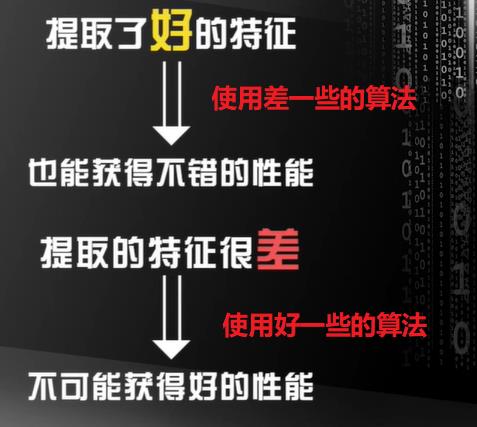
如何针对不同应用场景选择合适的机器学习算法,甚至构造新的机器学习算法解决目前无法解决的应用场景,这是涉及到理论与实践的重要科学问题!
三、没有免费午餐定理

因此没有任何情况下都最好的机器学习算法
- 举例

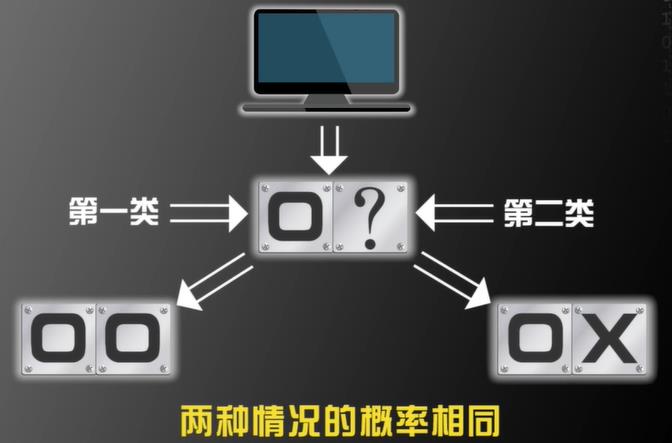
对错的概率都是一半
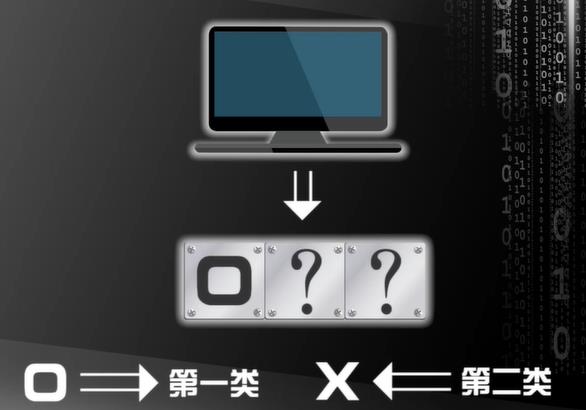
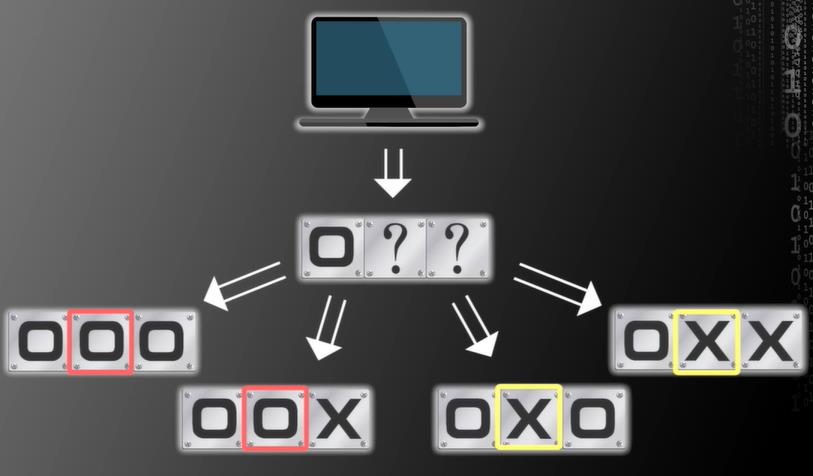
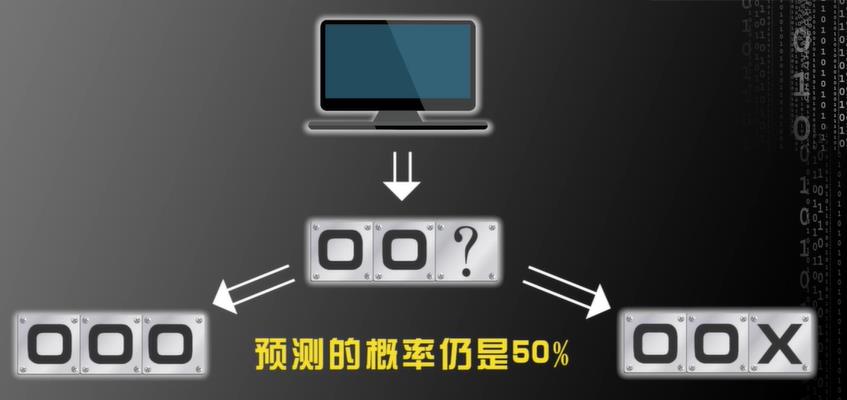


目前流行的机器学习算法都会做这样的预测


道理是从以前的事实中来的
我们可以通过类比推广到未来的预测
- 总结
不对特征空间的先验分布有假设,所有算法的表现都一样
再好的算法也有犯错的风险
没有放之四海而皆准的最好算法

总结
学习这门课程可以做什么?
- 人脸识别
- 五子棋程序对战(强化学习)
- 性别和年龄识别
- 水果识别
- 人脸特征点检测
- 语种识别
- 视频行为识别
以上是关于机器学习--入门介绍的主要内容,如果未能解决你的问题,请参考以下文章