事件相机与计算机视觉论文分享--Event-based Vision meets Deep Learning on Steering Prediction for Self-driving Car
Posted Angelus·
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了事件相机与计算机视觉论文分享--Event-based Vision meets Deep Learning on Steering Prediction for Self-driving Car相关的知识,希望对你有一定的参考价值。
.前言
事件相机作为一种新型的图像数据形式,由于其时间分辨率高、高动态范围、低功耗的优点,在许多CV问题上有着比传统相机更好的表现。笔者本次分享的是2018年CVPR上发表的一篇文章,将事件相机用于自动驾驶中的转向预测,通过结合事件相机与深度学习,实现了超越现有基于传统相机转向预测算法的表现。
论文原文:
Event-based Vision meets Deep Learning on Steering Prediction for Self-driving Cars
若不了解事件相机,关于事件相机的综述导读可以阅读笔者的文章:
Event-based Vision: A Survey——从这篇综述开始了解事件相机(一)
1. 论文总览
本篇论文利用深度卷积神经网络来处理事件数据,以预测汽车的转向角。预测汽车转向角是自动驾驶领域的一个重要问题,即汽车行驶至一个转弯口时,根据场景信息判断转弯角度,以实现自动转向。
目前已经有利用深度神经网络来预测汽车转角的工作展开,然而这些工作都是利用传统相机拍出的灰度图进行特征提取的。对于高速行驶在不同光照条件下的汽车来说,高速行驶造成的图像模糊以及光照变化产生的伪影,会使得预测结果出现较大偏差,这对自动驾驶的安全性造成了致命的影响。而事件相机得到的事件流,在经过合理的转换后,不仅能被深度卷积网络所接收,而且因为时间分辨率高,动态范围大的优势,能够克服传统相机面临的缺陷,作出更加精确的预测。

上图分别展示了在阳光条件和夜晚条件下,利用传统相机和事件相机对汽车转角进行预测的结果,无论在强照明还是暗光条件下,传统相机的预测结果均和实际值有较大偏差;而事件相机的预测结果则十分精确。
该论文的亮点在于:
1):首次实现了基于大规模事件相机数据的深度学习回归任务,并分析了为何事件相机数据能在这类任务上更有优势;
2):采用的深度卷积网络结构是现有的ResNet,并展示了基于ImageNet数据集的迁移学习能使训练得到更好的结果;
3):与现有转向预测的方法进行了对比,体现了本文结果的精确性。
2. 论文方法
预测的整体流程如下图所示:
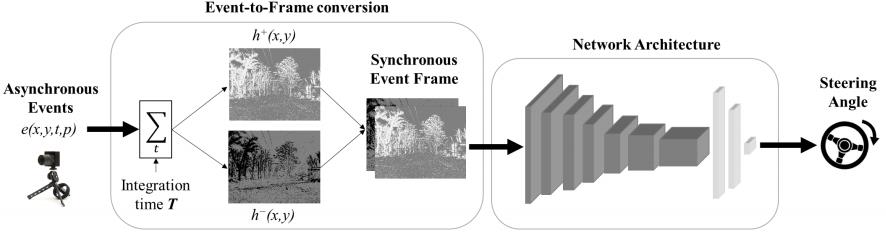
2.1 事件数据转换
本论文采用的是双通道事件帧(Two Channel Event Frame)的事件数据形式,通过选定一段时间间隔,分极性对每个像素沿时间戳进行叠加,得到每个极性对应的事件帧,最后按通道拼接即可作为数据输入深度神经网络。
对于给定时间间隔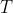 范围内的事件
范围内的事件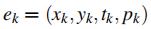 ,沿时间戳逐像素叠加,获得2D事件帧:
,沿时间戳逐像素叠加,获得2D事件帧:

上式为对于正极性事件的叠加方式,采用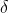 函数将事件量化(有正事件的像素输出1,否则为0), 再在指定时间间隔内按时间轴叠加,负极性事件按照同样方式处理,最终即可得到双通道的事件帧。
函数将事件量化(有正事件的像素输出1,否则为0), 再在指定时间间隔内按时间轴叠加,负极性事件按照同样方式处理,最终即可得到双通道的事件帧。
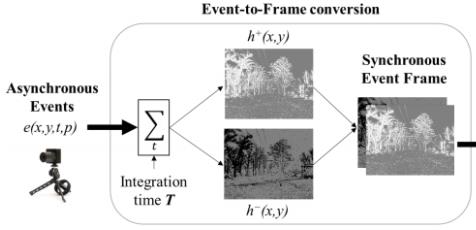
2.2 网络训练
2.2.1 数据处理
本处的数据处理并不是之前提到的对事件流数据的转换,而是对数据集进行一定的预处理、筛选与规划。
首先,对于一段汽车行驶的视频,其中有很大一部分时候汽车是处于直线行驶的,这样汽车的转角很多时候都是处于[-5°, 5°]的,分布不平衡的数据会给预测带来偏差。因此,对于这些转角较小的数据,仅选取30%用于训练。
其次,汽车行驶时有很多时候是在停车等待(红绿灯处、堵车处),此时汽车是非运动的,而这种情况下产生的事件都是噪声事件,对预测转角的训练是干扰因素。故训练时不考虑汽车时速低于20km/h的数据。
同时,为了去除异常值,文中用整理后训练集中转角的三倍的标准差来进行数据修剪,并归一化至[-1,1]的范围(针对转角数据而言)。在测试阶段,上述剔除的[-5°, 5°]范围以及时速低于20的数据均加入测试集范畴以验证模型的泛化能力。最后,对于输入的事件数据像素值会进行标准化至[0,1]范围,而网络的输出值范围规定至[-180°,180°]
除了对数据进行上述预处理外,论文还对训练集进行了科学的规划和分配。根据数据集标签,先将数据集分为4类:day、day_sun、evening、night,分别对应着不同天气、照明、路况条件下的数据,以观察不同条件下训练模型的表现。接着,作者考虑到了一段行车视频中,连续的数据帧都是很相近的,其对应的转角也很相近,因此不能随机选取训练集和测试集。作者给出的方法是:将视频分为连续、不重复的短序列(持续仅几十秒),用这些序列的子集作为训练集和测试集:40s作为训练集,20s作为测试集。划分效果如下(红色为训练集,蓝色为测试集):

最后,为了对比事件相机与传统相机的性能,文中分别选用灰度帧、灰度帧的差分以及事件帧进行网络训练。在这笔者需要解释一下,灰度帧的差分从原理上来讲是通过相邻灰度帧之间的差分获得的,也反映了明暗的变化情况,这看上去就和事件帧的获取有异曲同工之妙,两者从图像上看也十分相像;但由于是从灰度帧演化而来,其时间分辨率和动态范围的缺陷依然存在。作者旨在通过这样的对比,来体现事件相机的优势不是在于记录亮度差这一特点,而是在于其超高的时间分辨率和较大的动态范围。

2.2.2 网络模型
文章采用的网络模型为CV领域应用极其广泛的ResNet,即一种引入了残差模块的深度卷积神经网络。ResNet的思想在于引入一个深度残差框架来解决梯度消失的问题,让卷积网络去学习残差映射,解决深层网络梯度消失以及返回梯度相关性差的缺陷。关于ResNet的具体介绍可以参考这一篇文章:ResNet介绍,或是直接阅读相关文献。
文章分别用了ResNet18与ResNet50进行了训练,18和50表示的是网络的层数,旨在对比分析网络深度对结果的影响。同时,由于ResNet通常是用于图像分类的,在本任务中,仅将其用作特征提取器,即只用ResNet卷积层的部分,作者自行设置输出的池化和全连接层以用作回归任务。对于ResNet卷积层的输出,作者采用全局平均池化的方法来对提取的特征进行编码,输出向量的形式,全局平均池化即一张特征图仅输出一个值,该值为所有像素点的均值。(这样做的好处是减少了参数,有效防止了过拟合,同时使得梯度更好地传播)在此之后,再经过全连接-ReLu-全连接,最终输出预测的转角结果。根据论文描述笔者自行绘制了文章的网络结构:

2.3 评价指标
用于评价转角预测这一回归任务的表现,文中定了两个评价指标:均方根误差(RMSE)与可释方差(EVA)。
RMSE测量了预测值与真实值误差的平均幅度,表达式如下:

EVA则测量了预测值相对真实值的变化比例,其中Var是方差。如果预测值与真实值相差很小,那么EVA将接近于1;否则较大的偏差会使EVA为0或小于0:

3. 结果分析
3.1 选取合适的时间间隔T
笔者在前一篇综述解读中说过,对于事件帧来说,选取的时间间隔T至关重要,过大的T会使得数据的时间分辨率变小,而太小的T也会造成细小的运动无法捕捉到且噪声严重。
因此作者选取几个不同的T(10ms、25ms、50ms、100ms、200ms)进行事件帧生成,并用这些不同的事件帧输入网络进行训练,通过比较训练网络的表现来分析哪个T最为合适。下面展示了不同T的数据训练的网络对不同大小角度预测的相对误差变化、这些数据训练网络所得预测结果的RMSE与EVA以及变化图。网络均采用的ResNet50,数据则采用的是day_sun下的序列。
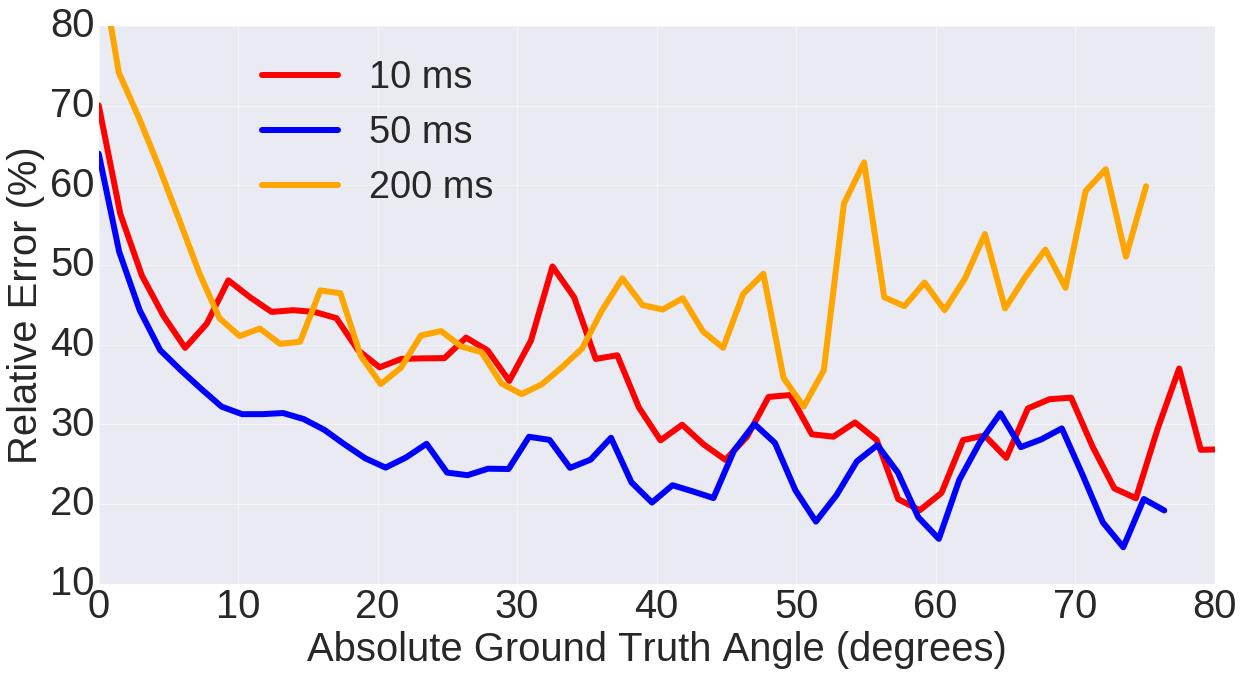
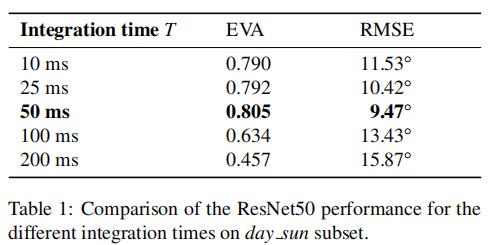
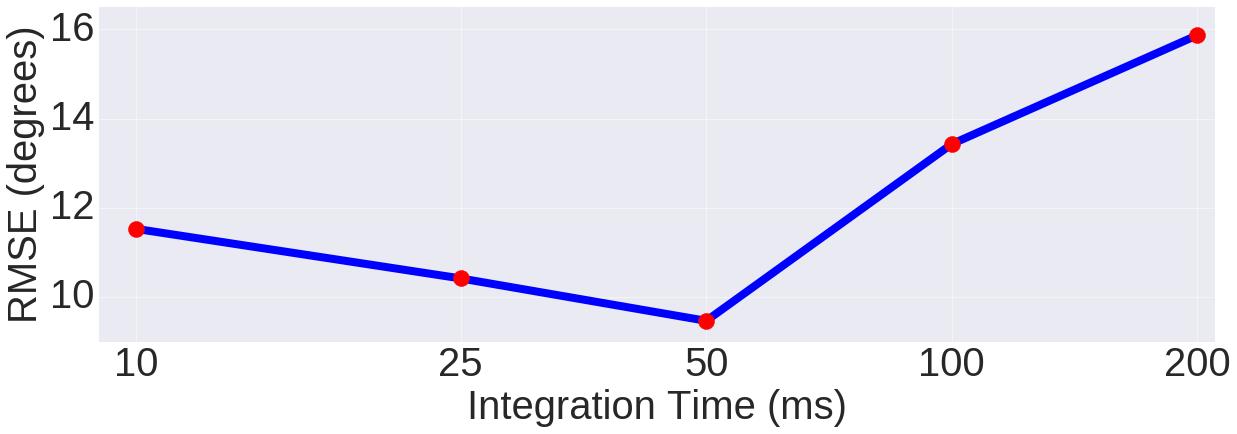
结果表明,50ms的时间间隔是这个转角预测问题下的最优解,它既能保留较丰富的时间信息,也具有一定的长度保证能分辨一些微小运动。在之后的实验中,T都固定为50ms。
3.2 不同路况下事件相机与传统相机对比
作者分别利用了传统灰度图、灰度图差分、事件数据这三类数据在day、day_sun、evening、night这四种路况下进行训练,同时也分别在ResNet18和ResNet50上进行了训练,最终比较各自预测结果EVA与RMSE的情况。可能笔者描述地比较混乱,不过大家看了下面这张表便可明白作者的实验方式:

作者的实验可谓是十分完善与详细,一共进行了24次训练和预测,每次皆得到了对应的EVA与RMSE作为评价标准。从上表可以清晰地看出,事件数据无论在何种情况下皆表现出较好的结果,不仅如此,和传统灰度帧结果相比,事件数据的表现可谓是飞跃性的,在四种路况条件下均有着较大的EVA与较小的RMSE。
作者也对实验作出了总结,汽车行进时光照变化会在灰度图上产生伪影,而高速运动则会造成灰度图的模糊,这些都使得灰度图在预测转角的任务中表现不佳。针对前一个问题,事件帧的高动态范围使得其能应对明暗的突变;对于后一个问题,事件帧的高时间分辨率又能有效防止高速运动模糊的产生。同时高速运动与明暗变化都是汽车行进时不可避免会遇到的情况,因此事件相机在汽车行驶中的转角预测问题上具有显著的优势。
同时还可以发现,深度更深的ResNet50表现出更好的效果,这和预期相符,毕竟更深的网络更能学习负责的映射关系。
3.3 迁移学习与整体对比
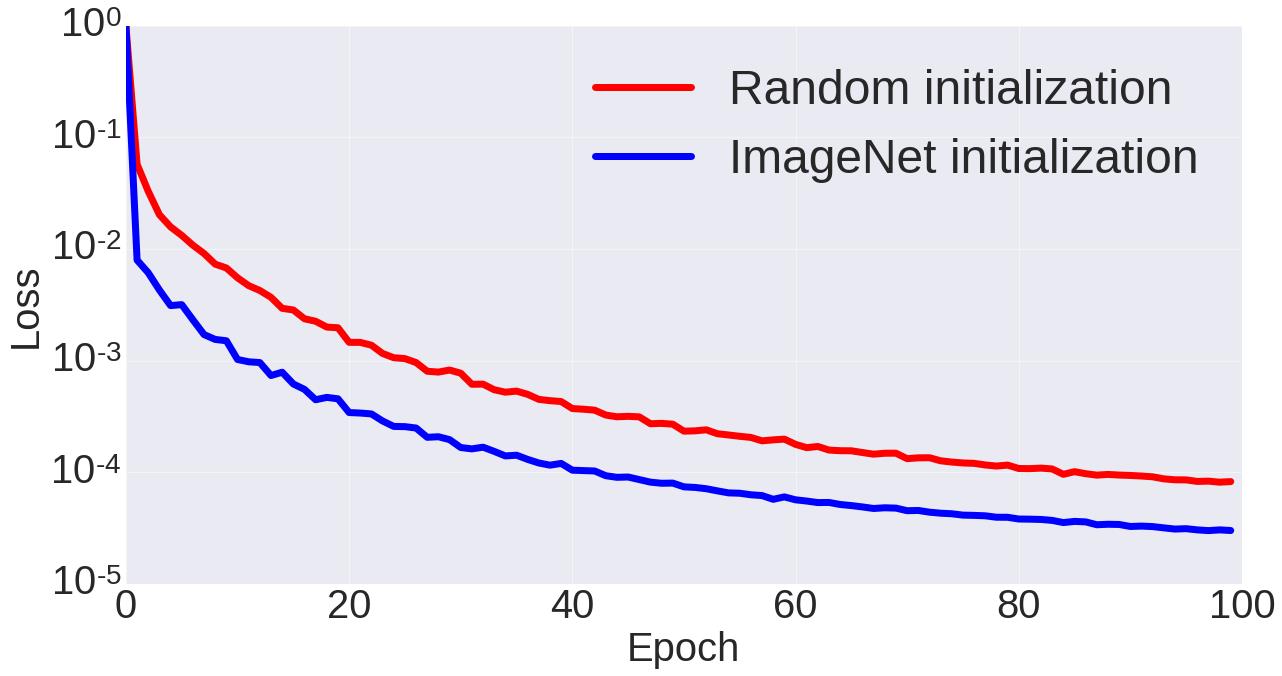
作者还发现,在ImageNet数据集上预先对模型进行训练,将训练值作为初始化值再训练自己的网络,这样的迁移学习能表现出更好的特性。因为即便一个是灰度图一个是事件帧,但都共享一些低阶的特征,预训练能够使得网络能够提取这些低阶特征,从而使得迁移学习后训练效果更好。
最后,作者还将本文提出的基于事件帧的深度学习预测转角的方法和该领域其他的先进方法进行了对比,采用了同样的评价体系,证明了论文方法的优越性。

4.小结
本篇论文是将事件相机数据用于传统深度神经网络的典范之一,仅是将事件流简单处理为事件帧,便能在汽车转角预测问题上表现得十分出色,这证明了事件流这一数据形式的优越性。按照这个思路,我们可以在类似这种对时间分辨率、动态范围要求高的CV问题上,利用事件相机来优化原有算法的性能。同时论文中划分数据集、对比分析的方法也给了我们许多启示,文中精彩的对比分析使得论文方案的优越性凸显得淋漓尽致。我们是否可以沿用论文的这种研究方法,对比各种事件流处理方案,用事件数据训练更多不同的卷积神经网络来处理其他的自动驾驶问题呢?笔者认为可以一试。
以上是关于事件相机与计算机视觉论文分享--Event-based Vision meets Deep Learning on Steering Prediction for Self-driving Car的主要内容,如果未能解决你的问题,请参考以下文章
(IROS 2022) 基于事件相机的单目视觉惯性里程计 / Event-based Monocular Visual Inertial Odometry
(IROS 2022) 基于事件相机的单目视觉惯性里程计 / Event-based Monocular Visual Inertial Odometry
(IROS 2022) 基于事件相机的单目视觉惯性里程计 / Event-based Monocular Visual Inertial Odometry