pandas入门
Posted 临风而眠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了pandas入门相关的知识,希望对你有一定的参考价值。
Pandas入门(2)
准备工作:
#导入库
import pandas as pd
import numpy as np
先读入pandas入门(1)中保存的movie_data.xlsx
#路径相同,只要写文件名
df=pd.read_excel('movie_data.xlsx')
df.head()
| Unnamed: 0 | Unnamed: 0.1 | 名字 | 投票人数 | 类型 | 产地 | 上映时间 | 时长 | 年代 | 评分 | 首映地点 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 肖申克的救赎 | 692795 | 剧情/犯罪 | 美国 | 1994-09-10 00:00:00 | 142 | 1994 | 9.6 | 多伦多电影节 |
| 1 | 1 | 1 | 控方证人 | 42995 | 剧情/悬疑/犯罪 | 美国 | 1957-12-17 00:00:00 | 116 | 1957 | 9.5 | 美国 |
| 2 | 2 | 2 | 美丽人生 | 327855 | 剧情/喜剧/爱情 | 意大利 | 1997-12-20 00:00:00 | 116 | 1997 | 9.5 | 意大利 |
| 3 | 3 | 3 | 阿甘正传 | 580897 | 剧情/爱情 | 美国 | 1994-06-23 00:00:00 | 142 | 1994 | 9.4 | 洛杉矶首映 |
| 4 | 4 | 4 | 霸王别姬 | 478523 | 剧情/爱情/同性 | 中国大陆 | 1993-01-01 00:00:00 | 171 | 1993 | 9.4 | 香港 |
一.数据格式转换
由于各种各样的原因,原始数据可能会有数据格式问题,而数据格式的错误可能会造成严重后果
并且,很多异常值也是我们经过格式转换之后才发现,所以数据格式转换对规整数据,数据清洗有重要的作用
1.查看格式
查看格式使用dtype
查看投票人数的格式
df['投票人数'].dtype
运行结果:
dtype('int64')
查看产地
df['产地'].dtype
运行结果:
dtype('O')
2.转化格式
转换格式用
.astype()
①将产地转为字符串
df['产地']=df['产地'].astype('str')
②将年份转换为整数格式
转换的过程中也可能发现异常值,因为有些类型无法正常转换
df['年代'] = df['年代'].astype('int')
此时报错:

通过条件判断来找到异常数据
df[df.年代=='2008\\u200e']
| Unnamed: 0 | Unnamed: 0.1 | 名字 | 投票人数 | 类型 | 产地 | 上映时间 | 时长 | 年代 | 评分 | 首映地点 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 15203 | 15205 | 15205 | 狂蟒惊魂 | 544 | 恐怖 | 中国大陆 | 2008-04-08 00:00:00 | 93 | 2008 | 2.7 | 美国 |
查看具体的值
df[df.年代 == '2008\\u200e']['年代'].values
运行结果:
array(['2008\\u200e'], dtype=object)
\\u200e是unicode的格式控制字符,使2008靠左
那么修改这条数据:
df.loc[15203,'年代']=2008
修改完了,查看数据
df.loc[15203]
运行结果:
Unnamed: 0 15205
Unnamed: 0.1 15205
名字 狂蟒惊魂
投票人数 544
类型 恐怖
产地 中国大陆
上映时间 2008-04-08 00:00:00
时长 93
年代 2008
评分 2.7
首映地点 美国
Name: 15203, dtype: object
这事就可以修改数据类型了
df['年代']=df['年代'].astype('int')
查看转化结果
df['年代'].dtype
运行结果:
dtype('int32')
df['年代']
运行结果:
0 1994
1 1957
2 1997
3 1994
4 1993
...
38723 1983
38724 1935
38725 1986
38726 1986
38727 1977
Name: 年代, Length: 38728, dtype: int32
③将时长转化为整数格式
df['时长']
运行结果:
0 142
1 116
2 116
3 142
4 171
...
38723 58
38724 98
38725 91
38726 78
38727 97
Name: 时长, Length: 38728, dtype: object
df['时长']=df['时长'].astype('int')
也报错了

df[df['时长']=='8U']
| Unnamed: 0 | Unnamed: 0.1 | 名字 | 投票人数 | 类型 | 产地 | 上映时间 | 时长 | 年代 | 评分 | 首映地点 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 31636 | 31644 | 31644 | 一个被隔绝的世界 | 46 | 纪录片/短片 | 瑞典 | 2001-10-25 00:00:00 | 8U | 1948 | 7.8 | 美国 |
并不知道8U到底是多长时间,可以直接删除这条数据
#inplace=True 直接在原数据上面修改
df.drop([31636],inplace=True)
df['时长']=df['时长'].astype('int')
又报错了!

df[df.时长 == '12J']
| Unnamed: 0 | Unnamed: 0.1 | 名字 | 投票人数 | 类型 | 产地 | 上映时间 | 时长 | 年代 | 评分 | 首映地点 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 32941 | 32949 | 32949 | 渔业危机 | 41 | 纪录片 | 英国 | 2009-06-19 00:00:00 | 12J | 2008 | 8.2 | USA |
同样,删掉这条数据
df.drop([32941],inplace=True)
再次替换
df['时长'] = df['时长'].astype('int')
df['时长']
运行结果:
0 142
1 116
2 116
3 142
4 171
...
38723 58
38724 98
38725 91
38726 78
38727 97
Name: 时长, Length: 38726, dtype: int32
终于没有幺蛾子了
二.排序
默认排序
df[:7]
| Unnamed: 0 | Unnamed: 0.1 | 名字 | 投票人数 | 类型 | 产地 | 上映时间 | 时长 | 年代 | 评分 | 首映地点 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 肖申克的救赎 | 692795 | 剧情/犯罪 | 美国 | 1994-09-10 00:00:00 | 142 | 1994 | 9.6 | 多伦多电影节 |
| 1 | 1 | 1 | 控方证人 | 42995 | 剧情/悬疑/犯罪 | 美国 | 1957-12-17 00:00:00 | 116 | 1957 | 9.5 | 美国 |
| 2 | 2 | 2 | 美丽人生 | 327855 | 剧情/喜剧/爱情 | 意大利 | 1997-12-20 00:00:00 | 116 | 1997 | 9.5 | 意大利 |
| 3 | 3 | 3 | 阿甘正传 | 580897 | 剧情/爱情 | 美国 | 1994-06-23 00:00:00 | 142 | 1994 | 9.4 | 洛杉矶首映 |
| 4 | 4 | 4 | 霸王别姬 | 478523 | 剧情/爱情/同性 | 中国大陆 | 1993-01-01 00:00:00 | 171 | 1993 | 9.4 | 香港 |
| 5 | 5 | 5 | 泰坦尼克号 | 157074 | 剧情/爱情/灾难 | 美国 | 2012-04-10 00:00:00 | 194 | 2012 | 9.4 | 中国大陆 |
| 6 | 6 | 6 | 辛德勒的名单 | 306904 | 剧情/历史/战争 | 美国 | 1993-11-30 00:00:00 | 195 | 1993 | 9.4 | 华盛顿首映 |
按投票人数排序
要用sort_values()
df.sort_values(by='投票人数')[:5]
| Unnamed: 0 | Unnamed: 0.1 | 名字 | 投票人数 | 类型 | 产地 | 上映时间 | 时长 | 年代 | 评分 | 首映地点 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 37264 | 37273 | 37273 | 生生舞不息 | 21 | 剧情/歌舞 | 法国 | 2002-04-12 00:00:00 | 100 | 2002 | 6.8 | 美国 |
| 35586 | 35595 | 35595 | 川崎的玫瑰 | 21 | 剧情 | 其他 | 2009-12-21 00:00:00 | 100 | 2009 | 6.1 | 美国 |
| 37032 | 37041 | 37041 | 魂惊一线 | 21 | 惊悚/恐怖 | 美国 | 2003-08-21 00:00:00 | 108 | 2002 | 5.3 | 美国 |
| 22867 | 22875 | 22875 | 少年邓恩铭 | 21 | 剧情/传记 | 中国大陆 | 2011-07-01 00:00:00 | 90 | 2011 | 3.8 | 美国 |
| 1990 | 1990 | 1990 | 爱和一颗子弹 | 21 | 动作/犯罪 | 美国 | 2002-08-30 00:00:00 | 85 | 2002 | 7.0 | 美国 |
默认是升序排序,ascending默认是为True,降序要改为False
ascending中文意思:上升的
df.sort_values(by='投票人数',ascending=False)[:5]
| Unnamed: 0 | Unnamed: 0.1 | 名字 | 投票人数 | 类型 | 产地 | 上映时间 | 时长 | 年代 | 评分 | 首映地点 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 肖申克的救赎 | 692795 | 剧情/犯罪 | 美国 | 1994-09-10 00:00:00 | 142 | 1994 | 9.6 | 多伦多电影节 |
| 9 | 9 | 9 | 这个杀手不太冷 | 662552 | 剧情/动作/犯罪 | 法国 | 1994-09-14 00:00:00 | 133 | 1994 | 9.4 | 法国 |
| 22 | 22 | 22 | 盗梦空间 | 642134 | 剧情/动作/科幻/悬疑/冒险 | 美国 | 2010-09-01 00:00:00 | 148 | 2010 | 9.2 | 中国大陆 |
| 3 | 3 | 3 | 阿甘正传 | 580897 | 剧情/爱情 | 美国 | 1994-06-23 00:00:00 | 142 | 1994 | 9.4 | 洛杉矶首映 |
| 99 | 99 | 99 | 三傻大闹宝莱坞 | 549808 | 剧情/喜剧/爱情/歌舞 | 印度 | 2011-12-08 00:00:00 | 171 | 2009 | 9.1 | 中国大陆 |
按照年代进行排序
df.sort_values(by='年代')[:10]
| Unnamed: 0 | Unnamed: 0.1 | 名字 | 投票人数 | 类型 | 产地 | 上映时间 | 时长 | 年代 | 评分 | 首映地点 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1700 | 1700 | 1700 | 朗德海花园场景 | 650 | 短片 | 英国 | 1888-10-14 | 60 | 1888 | 8.7 | 美国 |
| 14046 | 14048 | 14048 | 利兹大桥 | 126 | 短片 | 英国 | 1888-10 | 60 | 1888 | 7.2 | 美国 |
| 26162 | 26170 | 26170 | 恶作剧 | 51 | 短片 | 美国 | 1905-03-04 00:00:00 | 60 | 1890 | 4.8 | 美国 |
| 10626 | 10627 | 10627 | 可怜的比埃洛 | 176 | 喜剧/爱情/动画/短片 | 法国 | 1892-10-28 | 60 | 1892 | 7.5 | 法国 |
| 21757 | 21765 | 21765 | 胚胎植入前遗传学筛查 | 69 | 纪录片/短片 | 美国 | 1894-05-18 | 60 | 1894 | 5.7 | 美国 |
| 12372 | 12374 | 12374 | 更衣室之旁 | 148 | 动画/短片 | 法国 | 1894-12 | 60 | 1894 | 7.0 | 法国 |
| 14453 | 14455 | 14455 | 迪克森实验音膜 | 121 | 短片 | 美国 | 1905-03-08 00:00:00 | 60 | 1894 | 7.2 | 美国 |
| 616 | 616 | 616 | 水浇园丁 | 2675 | 喜剧/短片 | 法国 | 1895-12-28 | 60 | 1895 | 8.5 | 美国 |
| 932 | 932 | 932 | 婴儿的午餐 R | 1417 | 纪录片/短片 | 法国 | 1895-12-28 | 60 | 1895 | 7.7 | 法国 |
| 590 | 590 | 590 | 工厂大门 L | 2849 | 纪录片/短片 | 法国 | 1895-03-22 | 60 | 1895 | 8.4 | 法国 |
根据多个值排序
给by参数设置多个值即可
先按照评分,评分相同的情况下再按照投票人数
df.sort_values(by=['评分','投票人数'],ascending=False)[:20]
| Unnamed: 0 | Unnamed: 0.1 | 名字 | 投票人数 | 类型 | 产地 | 上映时间 | 时长 | 年代 | 评分 | 首映地点 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 9278 | 9278 | 9278 | 平安结祈 平安結 | 208 | 音乐 | 日本 | 2012-02-24 00:00:00 | 60 | 2012 | 9.9 | 美国 |
| 13880 | 13882 | 13882 | 武之舞 | 128 | 纪录片 | 中国大陆 | 1997-02-01 00:00:00 | 60 | 34943 | 9.9 | 美国 |
| 1110 | 1110 | 1110 | 未知电影 | 76 | 科幻/纪录片 | 美国 | 1905-06-23 00:00:00 | 75 | 2001 | 9.9 | 美国 |
| 23551 | 23559 | 23559 | 未作回答的问题:伯恩斯坦哈佛六讲 | 61 | 纪录片 | 美国 | 1905-05-29 00:00:00 | 60 | 1973 | 9.9 | 美国 |
| 35461 | 35470 | 35470 | 未知电影 | 46 | 纪录片/音乐 | 韩国 | 2013-10-31 00:00:00 | 90 | 2013 | 9.9 | 韩国 |
| 25265 | 25273 | 25273 | 索科洛夫:巴黎现场 | 43 | 音乐 | 法国 | 2002-11-04 00:00:00 | 127 | 2002 | 9.9 | 美国 |
| 11477 | 11479 | 11479 | 公园现场 | 163 | 音乐 | 英国 | 2012-12-03 00:00:00 | 60 | 2012 | 9.8 | 美国 |
| 35900 | 35909 | 35909 | 未知电影 | 157 | 纪录片/音乐 | 美国 | 1988-02-02 00:00:00 | 60 | 1988 | 9.8 | 美国 |
| 1289 | 1289 | 1289 | Sant | 143 | 脱口秀 | 日本 | 2003-01-01 00:00:00 | 135 | 2014 | 9.8 | 美国 |
| 26017 | 26025 | 26025 | 天使之声:自由童声合唱团 | 97 | 纪录片/音乐 | 美国 | 2007-10-02 00:00:00 | 75 | 2007 | 9.8 | 美国 |
| 19426 | 19428 | 19428 | 绿洲乐队海洋现场演唱会 | 82 | 音乐 | 英国 | 1995-08-28 00:00:00 | 60 | 1995 | 9.8 | 美国 |
| 698 | 698 | 698 | 未知电影 | 52 | 纪录片 | 英国 | 2008-07-25 00:00:00 | 40 | 2008 | 9.8 | 美国 |
| 27013 | 27021 | 27021 | 阿森纳 - 2 | 48 | 运动 | 英国 | 2008-06-09 00:00:00 | 60 | 2008 | 9.8 | 美国 |
| 27323 | 27331 | 27331 | 阿森纳: 再见海布里 - | 47 | 运动 | 英国 | 2006-06-19 00:00:00 | 60 | 2006 | 9.8 | 美国 |
| 35093 | 35102 | 35102 | 自由颂:柏林墙拆除庆祝音乐会 | 41 | 纪录片/音乐 | 其他 | 1989-12-25 00:00:00 | 94 | 1989 | 9.8 | 美国 |
| 31084 | 31092 | 31092 | 急救精英 | 37 | 纪录片 | 美国 | 1905-06-27 00:00:00 | 60 | 2008 | 9.8 | 美国 |
| 33377 | 33385 | 33385 | 未知电影 | 31 | 音乐 | 英国 | 1999-11-23 00:00:00 | 60 | 1999 | 9.8 | 美国 |
| 14207 | 14209 | 14209 | 久石让在武道馆:与宫崎骏动画一同走过的25年 久石譲 in 武道館 ~宮崎アニ | 8601 | 纪录片/音乐 | 日本 | 2008-08-05 00:00:00 | 116 | 2008 | 9.7 | 日本 |
| 19555 | 19557 | 19557 | 涅磐纽约不插电演唱会 | 5840 | 纪录片/音乐 | USA | 1993-12-16 00:00:00 | 72 | 1993 | 9.7 | 美国 |
| 14367 | 14369 | 14369 | 剧院魅影:25周年纪念 | 2417 | 剧情/音乐/歌舞 | 英国 | 2011-10-02 00:00:00 | 137 | 2011 | 9.7 | 美国 |
三.基本统计分析
1.描述性统计
dataframe.describe():对dataframe中的数值型数据进行统计性描述
df.describe()
| Unnamed: 0 | Unnamed: 0.1 | 投票人数 | 评分 | |
|---|---|---|---|---|
| count | 38728.000000 | 38728.000000 | 38728.000000 | 38728.000000 |
| mean | 19368.021509 | 19368.021509 | 6187.424912 | 6.935636 |
| std | 11183.434153 | 11183.434153 | 26146.706294 | 1.270194 |
| min | 0.000000 | 0.000000 | 21.000000 | 2.000000 |
| 25% | 9681.750000 | 9681.750000 | 98.000000 | 6.300000 |
| 50% | 19365.500000 | 19365.500000 | 341.000000 | 7.100000 |
| 75% | 29053.250000 | 29053.250000 | 1741.000000 | 7.800000 |
| max | 38737.000000 | 38737.000000 | 692795.000000 | 9.900000 |

遇到的问题:Unnamed
官方文档上说,describe默认会显示数值类型的列,但是为啥我的电影年代都没显示?
而且,为啥我的数据会有unnamed?
原始数据是没有unnamed,然后我第一次读取"豆瓣电影数据.xlsx",多了一列Unnamed:0,第二次读取’movie_data.xlsx’多了一列Unnamed:0.1
去查了一下,确实有不少人pandas读取excel的时候出现了这个问题,看到👉这个教程
教程里面说的index_col=0有效,但那个index=False是写入数据的时候用的,我还没试过
看到一个解释的更详细的教程
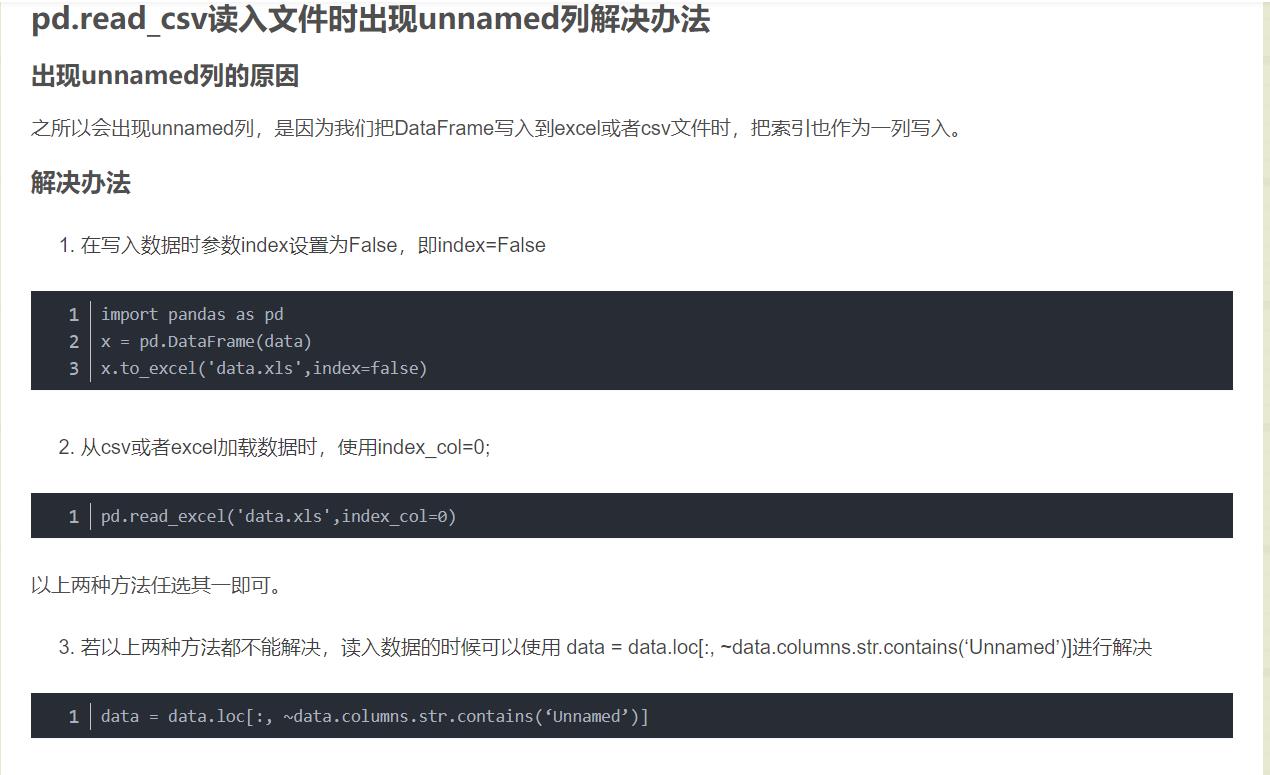
df_test1 = pd.read_excel('豆瓣电影数据.xlsx', index_col=0)
df_test1.head()
| 名字 | 投票人数 | 类型 | 产地 | 上映时间 | 时长 | 年代 | 评分 | 首映地点 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 肖申克的救赎 | 692795.0 | 剧情/犯罪 | 美国 | 1994-09-10 00:00:00 | 142 | 1994 | 9.6 | 多伦多电影节 |
| 1 | 控方证人 | 42995.0 | 剧情/悬疑/犯罪 | 美国 | 1957-12-17 00:00:00 | 116 | 1957 | 9.5 | 美国 |
| 2 | 美丽人生 | 327855.0 | 剧情/喜剧/爱情 | 意大利 | 1997-12-20 00:00:00 | 116 | 1997 | 9.5 | 意大利 |
| 3 | 阿甘正传 | 580897.0 | 剧情/爱情 | 美国 | 1994-06-23 00:00:00 | 142 | 1994 | 9.4 | 洛杉矶首映 |
| 4 | 霸王别姬 | 478523.0 | 剧情/爱情/同性 | 中国大陆 | 1993-01-01 00:00:00 | 171 | 1993 | 9.4 | 香港 |
df_test1.describe()
| 投票人数 | 评分 | |
|---|---|---|
| count | 38738.000000 | 38738.000000 |
| mean | 6185.833702 | 6.935704 |
| std | 26143.518786 | 1.270101 |
| min | -118.000000 | 2.000000 |
| 25% | 98.000000 | 6.300000 |
| 50% | 341.000000 | 7.100000 |
| 75% | 1739.750000 | 7.800000 |
| max | 692795.000000 | 9.900000 |
额,还是没有显示投票人数?dtype一下
df['年代'].dtype
运行结果:
dtype('O')
知道了…是我jupyter notebook两次登录,前面的单元格没有重新运行的原因…
df.describe()
| Unnamed: 0 | Unnamed: 0.1 | 投票人数 | 时长 | 年代 | 评分 | |
|---|---|---|---|---|---|---|
| count | 38726.000000 | 38726.000000 | 38726.000000 | 38726.000000 | 38726.000000 | 38726.000000 |
| mean | 19367.353819 | 19367.353819 | 6187.742215 | 89.054356 | 1998.791716 | 6.935581 |
| std | 11183.335993 | 11183.335993 | 26147.344193 | 83.343070 | 253.231215 | 1.270203 |
| min | 0.000000 | 0.000000 | 21.000000 | 1.000000 | 1888.000000 | 2.000000 |
| 25% | 9681.250000 | 9681.250000 | 98.000000 | 60.000000 | 1990.000000 | 6.300000 |
| 50% | 19364.500000 | 19364.500000 | 341.000000 | 92.000000 | 2005.000000 | 7.100000 |
| 75% | 29051.750000 | 29051.750000 | 1741.000000 | 106.000000 | 2010.000000 | 7.800000 |
| max | 38737.000000 | 38737.000000 | 692795.000000 | 11500.000000 | 39180.000000 | 9.900000 |
前面验证了df_test1那个index_col=0的方法可行,但对于df的前两列还是直接删掉吧
df = df.drop(['Unnamed: 0'],axis=1)
df.head()
| Unnamed: 0.1 | 名字 | 投票人数 | 类型 | 产地 | 上映时间 | 时长 | 年代 | 评分 | 首映地点 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 肖申克的救赎 | 692795 | 剧情/犯罪 | 美国 | 1994-09-10 00:00:00 | 142 | 1994 | 9.6 | 多伦多电影节 |
| 1 | 1 | 控方证人 | 42995 | 剧情/悬疑/犯罪 | 美国 | 1957-12-17 00:00:00 | 116 | 1957 | 9.5 | 美国 |
| 2 | 2 | 美丽人生 | 327855 | 剧情/喜剧/爱情 | 意大利 | 1997-12-20 00:00:00 | 116 | 1997 | 9.5 | 意大利 |
| 3 | 3 | 阿甘正传 | 580897 | 剧情/爱情 | 美国 | 1994-06-23 00:00:00 | 142 | 1994 | 9.4 | 洛杉矶首映 |
| 4 | 4 | 霸王别姬 | 478523 | 剧情/爱情/同性 | 中国大陆 | 1993-01-01 00:00:00 | 171 | 1993 | 9.4 | 香港 |
再删一列
df = df.drop(['Unnamed: 0.1'], axis=1)
df.head()
| 名字 | 投票人数 | 类型 | 产地 | 上映时间 | 时长 | 年代 | 评分 | 首映地点 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 肖申克的救赎 | 692795 | 剧情/犯罪 | 美国 | 1994-09-10 00:00:00 | 142 | 1994 | 9.6 | 多伦多电影节 |
| 1 | 控方证人 | 42995 | 剧情/悬疑/犯罪 | 美国 | 1957-12-17 00:00:00 | 116 | 1957 | 9.5 | 美国 |
| 2 | 美丽人生 | 327855 | 剧情/喜剧/爱情 | 意大利 | 1997-12-20 00:00:00 | 116 | 1997 | 9.5 | 意大利 |
| 3 | 阿甘正传 | 580897 | 剧情/爱情 | 美国 | 1994-06-23 00:00:00 | 142 | 1994 | 9.4 | 洛杉矶首映 |
| 4 | 霸王别姬 | 478523 | 剧情/爱情/同性 | 中国大陆 | 1993-01-01 00:00:00 | 171 | 1993 | 9.4 | 香港 |
🆗,下面来看describe
df.describe()
| 投票人数 | 时长 | 年代 | 评分 | |
|---|---|---|---|---|
| count | 38726.000000 | 38726.000000 | 38726.000000 | 38726.000000 |
| mean | 6187.742215 | 89.054356 | 1998.791716 | 6.935581 |
| std | 26147.344193 | 83.343070 | 253.231215 | 1.270203 |
| min | 21.000000 | 1.000000 | 1888.000000 | 2.000000 |
| 25% | 98.000000 | 60.000000 | 1990.000000 | 6.300000 |
| 50% | 341.000000 | 92.000000 | 2005.000000 | 7.100000 |
| 75% | 1741.000000 | 106.000000 | 2010.000000 | 7.800000 |
| max | 692795.000000 | 11500.000000 | 39180.000000 | 9.900000 |
通过统计性描述,可以发现异常值
很显然,我不是来自几万年后的人,所以这个年代39180应该是异常值,还有这个最大时长11500,我得看接近10天才看完的电影maybe也不存在吧,也是异常值
df[df['年代']>2021]
| 名字 | 投票人数 | 类型 | 产地 | 上映时间 | 时长 | 年代 | 评分 | 首映地点 | |
|---|---|---|---|---|---|---|---|---|---|
| 13880 | 武之舞 | 128 | 纪录片 | 中国大陆 | 1997-02-01 00:00:00 | 60 | 34943 | 9.9 | 美国 |
| 17113 | 妈妈回来吧-中国打工村的孩子 | 49 | 纪录片 | 日本 | 2007-04-08 00:00:00 | 109 | 39180 | 8.9 | 美国 |
df[df['时长']>1000]
| 名字 | 投票人数 | 类型 | 产地 | 上映时间 | 时长 | 年代 | 评分 | 首映地点 | |
|---|---|---|---|---|---|---|---|---|---|
| 19688 | 怒海余生 | 54 | 剧情/家庭/冒险 | 美国 | 1937-09-01 00:00:00 | 11500 | 1937 | 7.9 | 美国 |
| 38720 | 喧闹村的孩子们 | 36 | 家庭 | 瑞典 | 1986-12-06 00:00:00 | 9200 | 1986 | 8.7 | 瑞典 |
直接删掉就行了,这时要删除的是index,注意下面的.index技巧
df.drop(df[df['年代']>2021].index,inplace=True)
df.drop(df[df['时长']>1000].index, inplace=True)
要注意的是删除行的同时,连带的索引也删掉了,所以要重新给索引赋值
#不太明确有多少行,用len
df.index=range(1,len(df)+1)
df.head()
| 名字 | 投票人数 | 类型 | 产地 | 上映时间 | 时长 | 年代 | 评分 | 首映地点 | |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 肖申克的救赎 | 692795 | 剧情/犯罪 | 美国 | 1994-09-10 00:00:00 | 142 | 1994 | 9.6 | 多伦多电影节 |
| 2 | 控方证人 | 42995 | 剧情/悬疑/犯罪 | 美国 | 1957-12-17 00:00:00 | 116 | 1957 | 9.5 | 美国 |
| 3 | 美丽人生 | 327855 | 剧情/喜剧/爱情 | 意大利 | 1997-12-20 00:00:00 | 116 | 1997 | 9.5 | 意大利 |
| 4 | 阿甘正传 | 580897 | 剧情/爱情 | 美国 | 1994-06-23 00:00:00 | 142 | 1994 | 9.4 | 洛杉矶首映 |
| 5 | 霸王别姬 | 478523 | 剧情/爱情/同性 | 中国大陆 | 1993-01-01 00:00:00 | 171 | 1993 | 9.4 | 香港 |
2.最值
df['评分'].max()
运行结果:
9.9
df['评分'].min()
运行结果:
2.0
df['年代'].min()
运行结果:
1888
3.均值和中值
mean()均值 ,median()中位数
df['年代'].median()
运行结果:
2005.0
df['评分'].mean()
运行结果:
6.935382986415921
df['评分'].median()
运行结果:
7.1
4.方差和标准差
方差:var(),标准差:std()
df['评分'].var()
运行结果:
1.6131523403400334
df['评分'].std()
运行结果:
1.270099342705142
5.求和
df['时长'].sum()
运行结果:
3427850
6.相关系数,协方差
相关系数
.corr(),协方差.cov()
这好像得到的是相关系数矩阵和协方差矩阵… 麻了…数学知识忘了
df[['年代','评分']].corr()
运行结果:
| 年代 | 评分 | |
|---|---|---|
| 年代 | 1.000000 | -0.244311 |
| 评分 | -0.244311 | 1.000000 |
df[['年代', '评分']].cov()
| 年代 | 评分 | |
|---|---|---|
| 年代 | 397.391863 | -6.185716 |
| 评分 | -6.185716 | 1.613152 |
7.计数
统计电影数量
len(df)
运行结果:
38722
想看一下这些电影来自多少个国家和地区
也就是说,产地这一列的取值有多少种(而不是有多少个)
用.unique()统计唯一值的个数
df['产地'].unique()
运行结果:
array(['美国', '意大利', '中国大陆', '日本', '法国', '英国', '韩国', '中国香港', '阿根廷', '德国',
'印度', '其他', '加拿大', '波兰', '泰国', '澳大利亚', '西班牙', '俄罗斯', '中国台湾', '荷兰',
'丹麦', '比利时', 'USA', '苏联', '墨西哥', '巴西', '瑞典', '西德'], dtype=object)
len(df['产地'].unique())
运行结果:
28
由此可知,来自28个,但是好像有些重复,比如说美国和USA
那就可以用数据替换来合并数据
#把USA换成美国, 覆盖数据inplace=True
df['产地'].replace('USA','美国',inplace=True)
df['产地'].unique()
运行结果:
array(['美国', '意大利', '中国大陆', '日本', '法国', '英国', '韩国', '中国香港', '阿根廷', '德国',
'印度', '其他', '加拿大', '波兰', '泰国', '澳大利亚', '西班牙', '俄罗斯', '中国台湾', '荷兰',
'丹麦', '比利时', '苏联', '墨西哥', '巴西', '瑞典', '西德'], dtype=object)
虽然有历史原因,emm,但我还是想把苏联换成俄罗斯,西德换成德国
一起换的话要用列表
df['产地'].replace(['西德','苏联'],['德国','俄罗斯'],inplace=True)
df['产地'].unique()
运行结果:
array(['美国', '意大利', '中国大陆', '日本', '法国', '英国', '韩国', '中国香港', '阿根廷', '德国',
'印度', '其他', '加拿大', '波兰', '泰国', '澳大利亚', '西班牙', '俄罗斯', '中国台湾', '荷兰',
'丹麦', '比利时', '墨西哥', '巴西', '瑞典'], dtype=object)
len(df['产地'].unique())
运行结果:
25
看一下涉及了多少年份
df['年代'].unique()
运行结果:
array([1994, 1957, 1997, 1993, 2012, 2013, 2003, 2016, 2009, 2008, 2001,
1931, 1961, 2010, 2004, 1998, 1972, 1939, 2015, 1946, 2011, 1982,
1960, 2006, 1988, 2002, 1995, 1996, 1984, 2014, 1953, 2007, 2000,
1967, 1983, 1963, 1977, 1966, 1971, 1974, 1985, 1987, 1973, 1962,
1969, 1989, 1979, 1981, 1936, 1954, 1992, 1970, 1991, 2005, 1920,
1933, 1990, 1999, 1896, 1965, 1921, 1947, 1975, 1964, 1943, 1928,
1986, 1895, 1949, 1932, 1919, 1956, 1955, 1951, 1905, 1940, 1908,
1900, 1978, 1958, 1898, 1976, 1938, 1907, 1913, 1968, 1912, 1937,
1952, 1903, 1948, 1926, 1906, 1959, 1934, 1944, 1888, 1909, 1925,
1923, 1945, 1904, 1980, 1917, 1935, 1942, 1950, 1902, 1941, 1930,
1922, 1916, 1929, 1927, 1914, 1924, 1918, 1899, 1901, 1915, 1892,
1894, 1910, 1897, 1911, 1890])
len(df['年代'].unique())
运行结果:
126
如果要计算每一年的电影数量呢?
df['年代'].value_counts
运行结果:
<bound method IndexOpsMixin.value_counts of 1 1994
2 1957
3 1997
4 1994
5 1993
...
38718 1983
38719 1935
38720 1986
38721 1986
38722 1977
Name: 年代, Length: 38722, dtype: int32>
查看电影产出前五的国家地区
df['产地'].value_counts()[:5]
运行结果:
美国 11976
日本 5048
中国大陆 3802
中国香港 2851
法国 2815
Name: 产地, dtype: int64
保存数据
试一试之前查的避免unnamed的方法
df.to_excel('movie_data2.xlsx',index=False)
四.数据透视
读取刚刚的数据
df2=pd.read_excel("movie_data2.xlsx")
df2.head()
| 名字 | 投票人数 | 类型 | 产地 | 上映时间 | 时长 | 年代 | 评分 | 首映地点 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 肖申克的救赎 | 692795 | 剧情/犯罪 | 美国 | 1994-09-10 00:00:00 | 142 | 1994 | 9.6 | 多伦多电影节 |
| 1 | 控方证人 | 42995 | 剧情/悬疑/犯罪 | 美国 | 1957-12-17 00:00:00 | 116 | 1957 | 9.5 | 美国 |
| 2 | 美丽人生 | 327855 | 剧情/喜剧/爱情 | 意大利 | 1997-12-20 00:00:00 | 116 | 1997 | 9.5 | 意大利 |
| 3 | 阿甘正传 | 580897 | 剧情/爱情 | 美国 | 1994-06-23 00:00:00 | 142 | 1994 | 9.4 | 洛杉矶首映 |
| 4 | 霸王别姬 | 478523 | 剧情/爱情/同性 | 中国大陆 | 1993-01-01 00:00:00 | 171 | 1993 | 9.4 | 香港 |
确实,写入excel用index=False,读入excel用index_col=0,两者选其一即可
Excel中数据透视表的使用非常广泛,其实Pandas也
以上是关于pandas入门的主要内容,如果未能解决你的问题,请参考以下文章
pandas GroupBy上的方法apply:一般性的“拆分-应用-合并”