pandas入门
Posted 临风而眠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了pandas入门相关的知识,希望对你有一定的参考价值。
Pandas入门(3)
准备工作
导入包
import pandas as pd
import numpy as np
读入数据
df=pd.read_excel("movie_data2.xlsx")
df.head()
| 名字 | 投票人数 | 类型 | 产地 | 上映时间 | 时长 | 年代 | 评分 | 首映地点 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 肖申克的救赎 | 692795 | 剧情/犯罪 | 美国 | 1994-09-10 00:00:00 | 142 | 1994 | 9.6 | 多伦多电影节 |
| 1 | 控方证人 | 42995 | 剧情/悬疑/犯罪 | 美国 | 1957-12-17 00:00:00 | 116 | 1957 | 9.5 | 美国 |
| 2 | 美丽人生 | 327855 | 剧情/喜剧/爱情 | 意大利 | 1997-12-20 00:00:00 | 116 | 1997 | 9.5 | 意大利 |
| 3 | 阿甘正传 | 580897 | 剧情/爱情 | 美国 | 1994-06-23 00:00:00 | 142 | 1994 | 9.4 | 洛杉矶首映 |
| 4 | 霸王别姬 | 478523 | 剧情/爱情/同性 | 中国大陆 | 1993-01-01 00:00:00 | 171 | 1993 | 9.4 | 香港 |
一.数据重塑和轴向旋转
1.层次化索引
层次化索引能使我们在一个轴上拥有多个索引
①Series的层次化索引
来看一个两层索引
s = pd.Series(np.arange(1, 11), index=[
['a', 'a', 'a', 'a', 'a', 'b', 'b', 'b', 'c', 'c'],['①', '②', '③', '④', '⑤', '①', '②', '③', '①', '②']])
s
运行结果:
a ① 1
② 2
③ 3
④ 4
⑤ 5
b ① 6
② 7
③ 8
c ① 9
② 10
dtype: int32
s.index
运行结果:
MultiIndex([('a', '①'),
('a', '②'),
('a', '③'),
('a', '④'),
('a', '⑤'),
('b', '①'),
('b', '②'),
('b', '③'),
('c', '①'),
('c', '②')],
)
对外层索引进行操作
s['a']
运行结果:
① 1
② 2
③ 3
④ 4
⑤ 5
dtype: int32
#切片
s['a':'b']
#和原生切片不一样,两边都是闭
运行结果:
a ① 1
② 2
③ 3
④ 4
⑤ 5
b ① 6
② 7
③ 8
dtype: int32
对内层操作
#逗号前面表示外层索引,冒号两边没东西那就是全取
s[:,'①']
#取出来了('a', '①'),('b', '①'),('c', '①')的值
运行结果:
a 1
b 6
c 9
dtype: int32
取具体的值
s['c','②']
运行结果:
10
②通过unstack方法将Series变成一个DataFrame
例如:
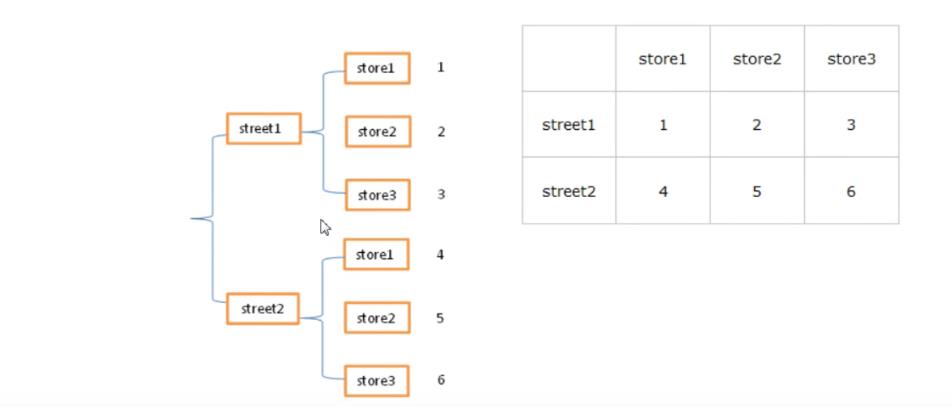
s.unstack()
运行结果:
| ① | ② | ③ | ④ | ⑤ | |
|---|---|---|---|---|---|
| a | 1.0 | 2.0 | 3.0 | 4.0 | 5.0 |
| b | 6.0 | 7.0 | 8.0 | NaN | NaN |
| c | 9.0 | 10.0 | NaN | NaN | NaN |
s.unstack().stack()
运行结果:
a ① 1.0
② 2.0
③ 3.0
④ 4.0
⑤ 5.0
b ① 6.0
② 7.0
③ 8.0
c ① 9.0
② 10.0
dtype: float64
#stack堆叠:将列转到行, unstack为反操作:行转到列
s.unstack().stack().unstack()
运行结果:
| ① | ② | ③ | ④ | ⑤ | |
|---|---|---|---|---|---|
| a | 1.0 | 2.0 | 3.0 | 4.0 | 5.0 |
| b | 6.0 | 7.0 | 8.0 | NaN | NaN |
| c | 9.0 | 10.0 | NaN | NaN | NaN |
③DataFrame的层次化索引
DataFrame的行和列都可以层次化索引
data=pd.DataFrame(np.arange(12).reshape(4,3))
data
#默认索引是数字
| 0 | 1 | 2 | |
|---|---|---|---|
| 0 | 0 | 1 | 2 |
| 1 | 3 | 4 | 5 |
| 2 | 6 | 7 | 8 |
| 3 | 9 | 10 | 11 |
行的层次化,增加index参数
data2 = pd.DataFrame(np.arange(12).reshape(4, 3),index=[['一','二','二','二'],['a','a','b','c']])
data2
#默认索引是数字
| 0 | 1 | 2 | ||
|---|---|---|---|---|
| 一 | a | 0 | 1 | 2 |
| 二 | a | 3 | 4 | 5 |
| b | 6 | 7 | 8 | |
| c | 9 | 10 | 11 |
列的层次化,增加columns参数
data3 = pd.DataFrame(np.arange(12).reshape(4, 3), index=[
['一', '二', '二', '二'], ['a', 'a', 'b', 'c']],columns=[['(1)','(1)','(2)'],['Ⅰ','Ⅰ','Ⅱ']])
data3
#默认索引是数字
| (1) | (2) | |||
|---|---|---|---|---|
| Ⅰ | Ⅰ | Ⅱ | ||
| 一 | a | 0 | 1 | 2 |
| 二 | a | 3 | 4 | 5 |
| b | 6 | 7 | 8 | |
| c | 9 | 10 | 11 | |
注意像上面那样写(1)的话,要加单引号,否则会被认为是只有一个数字的元组(只有一个数字没有逗号的元组就是数字本身)
选取列
data3['(1)']
| Ⅰ | Ⅰ | ||
|---|---|---|---|
| 一 | a | 0 | 1 |
| 二 | a | 3 | 4 |
| b | 6 | 7 | |
| c | 9 | 10 |
给行索引设定名称
data3.index.names=['row1','row2']
data3
| (1) | (2) | |||
|---|---|---|---|---|
| Ⅰ | Ⅰ | Ⅱ | ||
| row1 | row2 | |||
| 一 | a | 0 | 1 | 2 |
| 二 | a | 3 | 4 | 5 |
| b | 6 | 7 | 8 | |
| c | 9 | 10 | 11 | |
给列索引设定名称
data3.columns.names=['col1','col2']
data3
| col1 | (1) | (2) | ||
|---|---|---|---|---|
| col2 | Ⅰ | Ⅰ | Ⅱ | |
| row1 | row2 | |||
| 一 | a | 0 | 1 | 2 |
| 二 | a | 3 | 4 | 5 |
| b | 6 | 7 | 8 | |
| c | 9 | 10 | 11 | |
调整行索引的顺序
data3.swaplevel('row1','row2')
| col1 | (1) | (2) | ||
|---|---|---|---|---|
| col2 | Ⅰ | Ⅰ | Ⅱ | |
| row2 | row1 | |||
| a | 一 | 0 | 1 | 2 |
| 二 | 3 | 4 | 5 | |
| b | 二 | 6 | 7 | 8 |
| c | 二 | 9 | 10 | 11 |
④将豆瓣电影数据处理成多索引结构
df.index
运行结果:
RangeIndex(start=0, stop=38722, step=1)
set_index可以把列变成索引, reset_index可以把索引变成列
将产地作为外索引,年代作为内索引
df2=df.set_index(['产地','年代'])
df2
| 名字 | 投票人数 | 类型 | 上映时间 | 时长 | 评分 | 首映地点 | ||
|---|---|---|---|---|---|---|---|---|
| 产地 | 年代 | |||||||
| 美国 | 1994 | 肖申克的救赎 | 692795 | 剧情/犯罪 | 1994-09-10 00:00:00 | 142 | 9.6 | 多伦多电影节 |
| 1957 | 控方证人 | 42995 | 剧情/悬疑/犯罪 | 1957-12-17 00:00:00 | 116 | 9.5 | 美国 | |
| 意大利 | 1997 | 美丽人生 | 327855 | 剧情/喜剧/爱情 | 1997-12-20 00:00:00 | 116 | 9.5 | 意大利 |
| 美国 | 1994 | 阿甘正传 | 580897 | 剧情/爱情 | 1994-06-23 00:00:00 | 142 | 9.4 | 洛杉矶首映 |
| 中国大陆 | 1993 | 霸王别姬 | 478523 | 剧情/爱情/同性 | 1993-01-01 00:00:00 | 171 | 9.4 | 香港 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 法国 | 1983 | 神学院 S | 46 | Adult | 1905-06-05 00:00:00 | 58 | 8.6 | 美国 |
| 美国 | 1935 | 1935年 | 57 | 喜剧/歌舞 | 1935-03-15 00:00:00 | 98 | 7.6 | 美国 |
| 中国大陆 | 1986 | 血溅画屏 | 95 | 剧情/悬疑/犯罪/武侠/古装 | 1905-06-08 00:00:00 | 91 | 7.1 | 美国 |
| 1986 | 魔窟中的幻想 | 51 | 惊悚/恐怖/儿童 | 1905-06-08 00:00:00 | 78 | 8.0 | 美国 | |
| 俄罗斯 | 1977 | 列宁格勒围困之星火战役 Блокада: Фильм 2: Ленинградский ме... | 32 | 剧情/战争 | 1905-05-30 00:00:00 | 97 | 6.6 | 美国 |
38722 rows × 7 columns
这样的情况下,每一个索引都是一个元组
df2.index[0]
运行结果:
('美国', 1994)
df2.index[1]
运行结果:
('美国', 1957)
若要获取所有的美国电影信息,此时产地已经变成了索引,要用.loc()
.loc根据行标签获取行数据,下面会获得以年代为索引的dataframe
df2.loc['美国']
| 名字 | 投票人数 | 类型 | 上映时间 | 时长 | 评分 | 首映地点 | |
|---|---|---|---|---|---|---|---|
| 年代 | |||||||
| 1994 | 肖申克的救赎 | 692795 | 剧情/犯罪 | 1994-09-10 00:00:00 | 142 | 9.6 | 多伦多电影节 |
| 1957 | 控方证人 | 42995 | 剧情/悬疑/犯罪 | 1957-12-17 00:00:00 | 116 | 9.5 | 美国 |
| 1994 | 阿甘正传 | 580897 | 剧情/爱情 | 1994-06-23 00:00:00 | 142 | 9.4 | 洛杉矶首映 |
| 2012 | 泰坦尼克号 | 157074 | 剧情/爱情/灾难 | 2012-04-10 00:00:00 | 194 | 9.4 | 中国大陆 |
| 1993 | 辛德勒的名单 | 306904 | 剧情/历史/战争 | 1993-11-30 00:00:00 | 195 | 9.4 | 华盛顿首映 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 1987 | 跷家的一夜 | 82 | 喜剧/动作/惊悚/冒险 | 1987-07-01 00:00:00 | 102 | 7.8 | 美国 |
| 1987 | 零下的激情 | 199 | 剧情/爱情/犯罪 | 1987-11-06 00:00:00 | 98 | 7.4 | 美国 |
| 1986 | 离别秋波 | 240 | 剧情/爱情/音乐 | 1986-02-19 00:00:00 | 90 | 8.2 | 美国 |
| 1986 | 极乐森林 | 45 | 纪录片 | 1986-09-14 00:00:00 | 90 | 8.1 | 美国 |
| 1935 | 1935年 | 57 | 喜剧/歌舞 | 1935-03-15 00:00:00 | 98 | 7.6 | 美国 |
11976 rows × 7 columns
df2.loc['中国大陆']
| 名字 | 投票人数 | 类型 | 上映时间 | 时长 | 评分 | 首映地点 | |
|---|---|---|---|---|---|---|---|
| 年代 | |||||||
| 1993 | 霸王别姬 | 478523 | 剧情/爱情/同性 | 1993-01-01 00:00:00 | 171 | 9.4 | 香港 |
| 1961 | 大闹天宫 | 74881 | 动画/奇幻 | 1905-05-14 00:00:00 | 114 | 9.2 | 上集 |
| 2015 | 穹顶之下 | 51113 | 纪录片 | 2015-02-28 00:00:00 | 104 | 9.2 | 中国大陆 |
| 1982 | 茶馆 | 10678 | 剧情/历史 | 1905-06-04 00:00:00 | 118 | 9.2 | 美国 |
| 1988 | 山水情 | 10781 | 动画/短片 | 1905-06-10 00:00:00 | 19 | 9.2 | 美国 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 1986 | T省的八四、八五 | 380 | 剧情 | 1905-06-08 00:00:00 | 94 | 8.7 | 美国 |
| 1986 | 失踪的女中学生 | 101 | 儿童 | 1905-06-08 00:00:00 | 102 | 7.4 | 美国 |
| 1986 | 血战台儿庄 | 2908 | 战争 | 1905-06-08 00:00:00 | 120 | 8.1 | 美国 |
| 1986 | 血溅画屏 | 95 | 剧情/悬疑/犯罪/武侠/古装 | 1905-06-08 00:00:00 | 91 | 7.1 | 美国 |
| 1986 | 魔窟中的幻想 | 51 | 惊悚/恐怖/儿童 | 1905-06-08 00:00:00 | 78 | 8.0 | 美国 |
3802 rows × 7 columns
调整行索引的顺序
df2=df2.swaplevel('产地','年代')
df2.head()
| 名字 | 投票人数 | 类型 | 上映时间 | 时长 | 评分 | 首映地点 | ||
|---|---|---|---|---|---|---|---|---|
| 年代 | 产地 | |||||||
| 1994 | 美国 | 肖申克的救赎 | 692795 | 剧情/犯罪 | 1994-09-10 00:00:00 | 142 | 9.6 | 多伦多电影节 |
| 1957 | 美国 | 控方证人 | 42995 | 剧情/悬疑/犯罪 | 1957-12-17 00:00:00 | 116 | 9.5 | 美国 |
| 1997 | 意大利 | 美丽人生 | 327855 | 剧情/喜剧/爱情 | 1997-12-20 00:00:00 | 116 | 9.5 | 意大利 |
| 1994 | 美国 | 阿甘正传 | 580897 | 剧情/爱情 | 1994-06-23 00:00:00 | 142 | 9.4 | 洛杉矶首映 |
| 1993 | 中国大陆 | 霸王别姬 | 478523 | 剧情/爱情/同性 | 1993-01-01 00:00:00 | 171 | 9.4 | 香港 |
df2.loc[1994]
运行结果:
| 名字 | 投票人数 | 类型 | 上映时间 | 时长 | 评分 | 首映地点 | |
|---|---|---|---|---|---|---|---|
| 产地 | |||||||
| 美国 | 肖申克的救赎 | 692795 | 剧情/犯罪 | 1994-09-10 00:00:00 | 142 | 9.6 | 多伦多电影节 |
| 美国 | 阿甘正传 | 580897 | 剧情/爱情 | 1994-06-23 00:00:00 | 142 | 9.4 | 洛杉矶首映 |
| 法国 | 这个杀手不太冷 | 662552 | 剧情/动作/犯罪 | 1994-09-14 00:00:00 | 133 | 9.4 | 法国 |
| 美国 | 34街的 | 768 | 剧情/家庭/奇幻 | 1994-12-23 00:00:00 | 114 | 7.9 | 美国 |
| 中国大陆 | 活着 | 202794 | 剧情/家庭 | 1994-05-18 00:00:00 | 132 | 9.0 | 法国 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 美国 | 鬼精灵2: 恐怖 | 60 | 喜剧/恐怖/奇幻 | 1994-04-08 00:00:00 | 85 | 5.8 | 美国 |
| 英国 | 黑色第16 | 44 | 剧情/惊悚 | 1996-02-01 00:00:00 | 106 | 6.8 | 美国 |
| 日本 | 蜡笔小新之布里布里王国的秘密宝藏 クレヨンしんちゃん ブリブリ王国の | 2142 | 动画 | 1994-04-23 00:00:00 | 94 | 7.7 | 日本 |
| 日本 | 龙珠Z剧场版10:两人面临危机! 超战士难以成眠 ドラゴンボール Z 劇場版:危険なふたり! | 579 | 动画 | 1994-03-12 00:00:00 | 53 | 7.2 | 美国 |
| 中国香港 | 重案实录之惊天械劫案 重案實錄之驚天械劫 | 90 | 动作/犯罪 | 1905-06-16 00:00:00 | 114 | 7.3 | 美国 |
494 rows × 7 columns
若要取消层次化索引
df2 = df2.reset_index()
df2.head()
运行结果:
| 年代 | 产地 | 名字 | 投票人数 | 类型 | 上映时间 | 时长 | 评分 | 首映地点 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1994 | 美国 | 肖申克的救赎 | 692795 | 剧情/犯罪 | 1994-09-10 00:00:00 | 142 | 9.6 | 多伦多电影节 |
| 1 | 1957 | 美国 | 控方证人 | 42995 | 剧情/悬疑/犯罪 | 1957-12-17 00:00:00 | 116 | 9.5 | 美国 |
| 2 | 1997 | 意大利 | 美丽人生 | 327855 | 剧情/喜剧/爱情 | 1997-12-20 00:00:00 | 116 | 9.5 | 意大利 |
| 3 | 1994 | 美国 | 阿甘正传 | 580897 | 剧情/爱情 | 1994-06-23 00:00:00 | 142 | 9.4 | 洛杉矶首映 |
| 4 | 1993 | 中国大陆 | 霸王别姬 | 478523 | 剧情/爱情/同性 | 1993-01-01 00:00:00 | 171 | 9.4 | 香港 |
2.轴向旋转
取前五行电影数据为例子
Data=df2[:5]
Data
| 年代 | 产地 | 名字 | 投票人数 | 类型 | 上映时间 | 时长 | 评分 | 首映地点 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1994 | 美国 | 肖申克的救赎 | 692795 | 剧情/犯罪 | 1994-09-10 00:00:00 | 142 | 9.6 | 多伦多电影节 |
| 1 | 1957 | 美国 | 控方证人 | 42995 | 剧情/悬疑/犯罪 | 1957-12-17 00:00:00 | 116 | 9.5 | 美国 |
| 2 | 1997 | 意大利 | 美丽人生 | 327855 | 剧情/喜剧/爱情 | 1997-12-20 00:00:00 | 116 | 9.5 | 意大利 |
| 3 | 1994 | 美国 | 阿甘正传 | 580897 | 剧情/爱情 | 1994-06-23 00:00:00 | 142 | 9.4 | 洛杉矶首映 |
| 4 | 1993 | 中国大陆 | 霸王别姬 | 478523 | 剧情/爱情/同性 | 1993-01-01 00:00:00 | 171 | 9.4 | 香港 |
行列转换.T方法
Data.T
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| 年代 | 1994 | 1957 | 1997 | 1994 | 1993 |
| 产地 | 美国 | 美国 | 意大利 | 美国 | 中国大陆 |
| 名字 | 肖申克的救赎 | 控方证人 | 美丽人生 | 阿甘正传 | 霸王别姬 |
| 投票人数 | 692795 | 42995 | 327855 | 580897 | 478523 |
| 类型 | 剧情/犯罪 | 剧情/悬疑/犯罪 | 剧情/喜剧/爱情 | 剧情/爱情 | 剧情/爱情/同性 |
| 上映时间 | 1994-09-10 00:00:00 | 1957-12-17 00:00:00 | 1997-12-20 00:00:00 | 1994-06-23 00:00:00 | 1993-01-01 00:00:00 |
| 时长 | 142 | 116 | 116 | 142 | 171 |
| 评分 | 9.6 | 9.5 | 9.5 | 9.4 | 9.4 |
| 首映地点 | 多伦多电影节 | 美国 | 意大利 | 洛杉矶首映 | 香港 |
DataFrame也可以用stack和unstack转换为层次化索引的Series
Data.stack()
运行结果:
0 年代 1994
产地 美国
名字 肖申克的救赎
投票人数 692795
类型 剧情/犯罪
上映时间 1994-09-10 00:00:00
时长 142
评分 9.6
首映地点 多伦多电影节
1 年代 1957
产地 美国
名字 控方证人
投票人数 42995
类型 剧情/悬疑/犯罪
上映时间 1957-12-17 00:00:00
时长 116
评分 9.5
首映地点 美国
2 年代 1997
产地 意大利
名字 美丽人生
投票人数 327855
类型 剧情/喜剧/爱情
上映时间 1997-12-20 00:00:00
时长 116
评分 9.5
首映地点 意大利
3 年代 1994
产地 美国
名字 阿甘正传
投票人数 580897
类型 剧情/爱情
上映时间 1994-06-23 00:00:00
时长 142
评分 9.4
首映地点 洛杉矶首映
4 年代 1993
产地 中国大陆
名字 霸王别姬
投票人数 478523
类型 剧情/爱情/同性
上映时间 1993-01-01 00:00:00
时长 171
评分 9.4
首映地点 香港
dtype: object
Data.stack().unstack()
| 年代 | 产地 | 名字 | 投票人数 | 类型 | 上映时间 | 时长 | 评分 | 首映地点 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1994 | 美国 | 肖申克的救赎 | 692795 | 剧情/犯罪 | 1994-09-10 | 142 | 9.6 | 多伦多电影节 |
| 1 | 1957 | 美国 | 控方证人 | 42995 | 剧情/悬疑/犯罪 | 1957-12-17 | 116 | 9.5 | 美国 |
| 2 | 1997 | 意大利 | 美丽人生 | 327855 | 剧情/喜剧/爱情 | 1997-12-20 | 116 | 9.5 | 意大利 |
| 3 | 1994 | 美国 | 阿甘正传 | 580897 | 剧情/爱情 | 1994-06-23 | 142 | 9.4 | 洛杉矶首映 |
| 4 | 1993 | 中国大陆 | 霸王别姬 | 478523 | 剧情/爱情/同性 | 1993-01-01 | 171 | 9.4 | 香港 |
二.数据分组,分组运算
Groupby技术:实现数据的分组和分组运算,作用类似于数据透视表
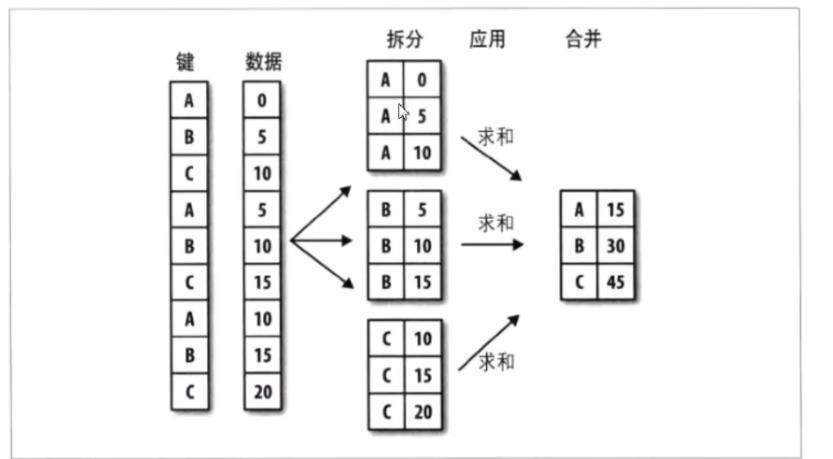
按照电影产地进行分组
先定义一个分组变量
group=df.groupby(df['产地'])
#GroupBy对象
print(group)
print(type(group))
运行结果:
<pandas.core.groupby.generic.DataFrameGroupBy object at 0x00000214044DE2E0>
<class 'pandas.core.groupby.generic.DataFrameGroupBy'>
计算分组后的各个统计量
#计算各个组别的数值型数据的平均值
group.mean()
| 投票人数 | 时长 | 年代 | 评分 | |
|---|---|---|---|---|
| 产地 | ||||
| 中国台湾 | 8474.864078 | 87.257282 | 1999.009709 | 7.066667 |
| 中国大陆 | 10898.293793 | 81.432930 | 2004.599684 | 6.064703 |
| 中国香港 | 8167.446159 | 88.541214 | 1991.100316 | 6.474114 |
| 丹麦 | 1993.858586 | 88.101010 | 1999.090909 | 7.245960 |
| 俄罗斯 | 1019.134172 | 95.918239 | 1984.899371 | 7.554507 |
| 其他 | 1591.494007 | 87.100573 | 1998.761334 | 7.237467 |
| 加拿大 | 1915.304288 | 80.109267 | 2002.461964 | 6.733610 |
| 印度 | 3210.843137 | 121.016807 | 2005.974790 | 6.872269 |
| 墨西哥 | 1173.218487 | 91.840336 | 1992.815126 | 7.087395 |
| 巴西 | 3536.000000 | 87.811881 | 1999.871287 | 7.262376 |
| 德国 | 2597.851744 | 92.062016 | 1996.062984 | 7.198062 |
| 意大利 | 3340.740988 | 104.008011 | 1985.503338 | 7.179306 |
| 日本 | 3565.876585 | 84.705428 | 1999.907092 | 7.194572 |
| 比利时 | 1230.122302 | 82.352518 | 1999.496403 | 7.217986 |
| 法国 | 3628.402842 | 89.901599 | 1991.757016 | 7.239432 |
| 波兰 | 881.640884 | 80.734807 | 1987.027624 | 7.441989 |
| 泰国 | 5322.724490 | 88.442177 | 2009.129252 | 6.109184 |
| 澳大利亚 | 4719.043333 | 85.163333 | 2002.986667 | 6.978000 |
| 瑞典 | 1510.817708 | 93.218750 | 1986.932292 | 7.413021 |
| 美国 | 8500.825234 | 89.347111 | 1994.573313 | 6.946685 |
| 英国 | 4797.089790 | 88.343592 | 1996.726647 | 7.526937 |
| 荷兰 | 934.425806 | 75.387097 | 2001.283871 | 7.190323 |
| 西班牙 | 3326.024609 | 90.503356 | 2001.588367 | 7.024385 |
| 阿根廷 | 2226.474138 | 91.706897 | 2004.034483 | 7.273276 |
| 韩国 | 6484.885270 | 99.729090 | 2008.119171 | 6.362990 |
计算每年的平均评分
df['评分'].groupby(df['年代']).mean()
运行结果:
年代
1888 7.950000
1890 4.800000
1892 7.500000
1894 6.633333
1895 7.575000
...
2012 6.457717
2013 6.392604
2014 6.259777
2015 6.142238
2016 5.868217
Name: 评分, Length: 126, dtype: float64
计算每个产地的电影的平均得分
df['评分'].groupby(df['产地']).mean()
运行结果:
产地
中国台湾 7.066667
中国大陆 6.064703
中国香港 6.474114
丹麦 7.245960
俄罗斯 7.554507
其他 7.237467
加拿大 6.733610
印度 6.872269
墨西哥 7.087395
巴西 7.262376
德国 7.198062
意大利 7.179306
日本 7.194572
比利时 7.217986
法国 7.239432
波兰 7.441989
泰国 6.109184
澳大利亚 6.978000
瑞典 7.413021
美国 6.946685
英国 7.526937
荷兰 7.190323
西班牙 7.024385
阿根廷 7.273276
韩国 6.362990
Name: 评分, dtype: float64
前面的对各个数值型变量求均值,但其实对年代求平均值没啥意义,可以先将年代转为字符串
df['年代']=df['年代'].astype('str')
df.groupby(df['产地']).mean()
| 投票人数 | 时长 | 评分 | |
|---|---|---|---|
| 产地 | |||
| 中国台湾 | 8474.864078 | 87.257282 | 7.066667 |
| 中国大陆 | 10898.293793 | 81.432930 | 6.064703 |
| 中国香港 | 8167.446159 | 88.541214 | 6.474114 |
| 丹麦 | 1993.858586 | 88.101010 | 7.245960 |
| 俄罗斯 | 1019.134172 | 95.918239 | 7.554507 |
| 其他 | 1591.494007 | 87.100573 | 7.237467 |
| 加拿大 | 1915.304288 | 80.109267 | 6.733610 |
| 印度 | 3210.843137 | 121.016807 | 6.872269 |
| 墨西哥 | 1173.218487 | 91.840336 | 7.087395 |
| 巴西 | 3536.000000 | 87.811881 | 7.262376 |
| 德国 | 2597.851744 | 92.062016 | 7.198062 |
| 意大利 | 3340.740988 | 104.008011 | 7.179306 |
| 日本 | 3565.876585 | 84.705428 | 7.194572 |
| 比利时 | 1230.122302 | 82.352518 | 7.217986 |
| 法国 | 3628.402842 | 89.901599 | 7.239432 |
| 波兰 | 881.640884 | 80.734807 | 7.441989 |
| 泰国 | 5322.724490 | 88.442177 | 6.109184 |
| 澳大利亚 | 4719.043333 | 85.163333 | 6.978000 |
| 瑞典 | 1510.817708 | 93.218750 | 7.413021 |
| 美国 | 8500.825234 | 89.347111 | 6.946685 |
| 英国 | 4797.089790 | 88.343592 | 7.526937 |
| 荷兰 | 934.425806 | 75.387097 | 7.190323 |
| 西班牙 | 3326.024609 | 90.503356 | 7.024385 |
| 阿根廷 | 2226.474138 | 91.706897 | 7.273276 |
| 韩国 | 6484.885270 | 99.729090 | 6.362990 |
这时候就不会对年代求平均了
#求中位数
df.groupby(df.产地).median()
| 投票人数 | 时长 | 评分 | |
|---|---|---|---|
| 产地 | |||
| 中国台湾 | 487.0 | 92.0 | 7.1 |
| 中国大陆 | 501.5 | 90.0 | 6.4 |
| 中国香港 | 637.0 | 92.0 | 6.5 |
| 丹麦 | 181.5 | 93.5 | 7.3 |
| 俄罗斯 | 132.0 | 93.0 | 7.7 |
| 其他 | 154.0 | 90.0 | 7.4 |
| 加拿大 | 251.0 | 89.0 | 6.9 |
| 印度 | 138.0 | 131.0 | 7.0 |
| 墨西哥 | 174.0 | 93.0 | 7.2 |
| 巴西 | 126.0 | 96.0 | 7.3 |
| 德国 | 208.5 | 94.0 | 7.3 |
| 意大利 | 181.0 | 101.0 | 7.3 |
| 日本 | 355.5 | 89.0 | 7.3 |
| 比利时 | 226.0 | 90.0 | 7.3 |
| 法国 | 240.0 | 95.0 | 7.3 |
| 波兰 | 174.0 | 87.0 | 7.5 |
| 泰国 | 542.5 | 92.5 | 6.2 |
| 澳大利亚 | 303.5 | 94.0 | 7.0 |
| 瑞典 | 186.0 | 95.5 | 7.6 |
| 美国 | 392.0 | 93.0 | 7.1 |
| 英国 | 316.5 | 91.0 | 7.6 |
| 荷兰 | 175.0 | 84.0 | 7.3 |
| 西班牙 | 254.0 | 97.0 | 7.1 |
| 阿根廷 | 140.0 | 95.5 | 7.3 |
| 韩国 | 998.0 | 104.0 | 6.5 |
传入多个分组变量
df.groupby([df['产地'],df["年代"]]).mean()
| 投票人数 | 时长 | 评分 | ||
|---|---|---|---|---|
| 产地 | 年代 | |||
| 中国台湾 | 1963 | 121.000000 | 113.000000 | 6.400000 |
| 1965 | 153.666667 | 105.000000 | 6.800000 | |
| 1966 | 51.000000 | 60.000000 | 7.900000 | |
| 1967 | 4444.000000 | 112.000000 | 8.000000 | |
| 1968 | 89.000000 | 83.000000 | 7.400000 | |
| ... | ... | ... | ... | ... |
| 韩国 | 2012 | 5762.537736 | 100.669811 | 6.064151 |
| 2013 | 10189.036036 | 96.504505 | 6.098198 | |
| 2014 | 3776.266667 | 98.666667 | 5.650833 | |
| 2015 | 3209.247706 | 100.266055 | 5.423853 | |
| 2016 | 1739.850000 | 106.100000 | 5.730000 |
1584 rows × 3 columns
获得每个地区,每一年电影的评分的均值
means=df['评分'].groupby([df['产地'],df['年代']]).mean()
means
运行结果:
产地 年代
中国台湾 1963 6.400000
1965 6.800000
1966 7.900000
1967 8.000000
1968 7.400000
...
韩国 2012 6.064151
2013 6.098198
2014 5.650833
2015 5.423853
2016 5.730000
Name: 评分, Length: 1584, dtype: float64
series通过unstack方法转化为dataframe,会产生缺失值
means.unstack().T
运行结果:
| 产地 | 中国台湾 | 中国大陆 | 中国香港 | 丹麦 | 俄罗斯 | 其他 | 加拿大 | 印度 | 墨西哥 | 巴西 | ... | 波兰 | 泰国 | 澳大利亚 | 瑞典 | 美国 | 英国 | 荷兰 | 西班牙 | 阿根廷 | 韩国 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 年代 | |||||||||||||||||||||
| 1888 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | 7.950000 | NaN | NaN | NaN | NaN |
| 1890 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | 4.800000 | NaN | NaN | NaN | NaN | NaN |
| 1892 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 1894 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | 6.450000 | NaN | NaN | NaN | NaN | NaN |
| 1895 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 2012 | 6.556098 | 5.727187 | 6.110526 | 7.418750 | 6.572727 | 6.591743 | 6.425000 | 6.502632 | 7.100000 | 7.32 | ... | 7.066667 | 5.962963 | 6.614286 | 5.9625 | 6.437622 | 7.293103 | 6.766667 | 6.595238 | 6.483333 | 6.064151 |
| 2013 | 7.076471 | 5.316667 | 6.105714 | 6.555556 | 6.875000 | 6.853571 | 6.018182 | 6.400000 | 6.983333 | 8.00 | ... | 6.966667 | 5.568000 | 6.760000 | 7.1000 | 6.339668 | 7.448322 | 6.563636 | 6.358333 | 6.616667 | 6.098198 |
| 2014 | 6.522222 | 4.963757 | 5.616667 | 7.120000 | 7.175000 | 6.596250 | 5.921739 | 6.374194 | 7.250000 | 6.86 | ... | 7.060000 | 5.653571 | 6.568750 | 6.9600 | 6.415922 | 7.275000 | 7.300000 | 6.868750 | 7.150000 | 5.650833 |
| 2015 | 6.576000 | 4.969189 | 5.589189 | 7.166667 | 7.342857 | 6.735714 | 6.018750 | 6.736364 | 6.500000 | 6.76 | ... | 6.300000 | 5.846667 | 6.880000 | 7.6250 | 6.278641 | 7.155056 | 6.700000 | 6.514286 | 7.233333 | 5.423853 |
| 2016 | NaN | 4.712000 | 5.390909 | 7.000000 | NaN | 7.225000 | 6.200000 | 6.900000 | NaN | NaN | ... | NaN | NaN | NaN | NaN | 6.540909 | 7.200000 | NaN | NaN | NaN | 5.730000 |
126 rows × 25 columns
三.离散化处理
在实际的数据分析项目中,对有的数据属性,我们往往并不关注数据的绝对取值,只关注它所处的区间或者等级
1.cut函数进行离散化
离散化也可称为分组、区间化
pd.cut(x, bins, right=True, labels=None, retbins=False, plecision=3, include_lowest=False)
参数解释︰×∶需要离散化的数组、Series、DataFrame对象
bins :分组的依据
right=True 默认包括右端点(默认左开右闭区间)
比如,我们可以把评分9分及以上的电影定义为A,7到9分定义为B,5到7分定义为c,3到5分定义为D,小于3分定义为E
#x:需要离散化的数组:评分 bins:分组的依据[0,3,5,7,9] 默认左开右闭区间
pd.cut(df以上是关于pandas入门的主要内容,如果未能解决你的问题,请参考以下文章
pandas GroupBy上的方法apply:一般性的“拆分-应用-合并”