爬虫进阶Selenium入门好文,强烈推荐 ! ! !
Posted ZSYL
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫进阶Selenium入门好文,强烈推荐 ! ! !相关的知识,希望对你有一定的参考价值。
爬虫进阶:Selenium入门
前言:selenium的介绍
selenium自动化测试框架在爬虫中的应用,selenium能够大幅降低爬虫的编写难度,但是也同样会大幅降低爬虫的爬取速度。在逼不得已的情况下我们可以使用selenium进行爬虫的编写。
- 了解 selenium的工作原理
- 了解 selenium以及chromedriver的安装
- 掌握 标签对象click点击以及send_keys输入
1. selenium运行效果展示
Selenium是一个Web的自动化测试工具,最初是为网站自动化测试而开发的,Selenium 可以直接调用浏览器,它支持所有主流的浏览器(包括PhantomJS这些无界面的浏览器),可以接收指令,让浏览器自动加载页面,获取需要的数据,甚至页面截屏等。我们可以使用selenium很容易完成之前编写的爬虫,接下来我们就来看一下selenium的运行效果
1.1 chrome浏览器的运行效果
在下载好chromedriver以及安装好selenium模块后,执行下列代码并观察运行的过程
from selenium import webdriver
# 如果driver没有添加到了环境变量,则需要将driver的绝对路径赋值给executable_path参数
# driver = webdriver.Chrome(executable_path='/home/worker/Desktop/driver/chromedriver')
# 如果driver添加了环境变量则不需要设置executable_path
driver = webdriver.Chrome()
# 向一个url发起请求
driver.get("http://www.itcast.cn/")
# 把网页保存为图片,69版本以上的谷歌浏览器将无法使用截图功能
# driver.save_screenshot("itcast.png")
print(driver.title) # 打印页面的标题
# 退出模拟浏览器
driver.quit() # 一定要退出!不退出会有残留进程!
1.2 phantomjs无界面浏览器的运行效果
PhantomJS 是一个基于Webkit的“无界面”(headless)浏览器,它会把网站加载到内存并执行页面上的 javascript。下载地址:http://phantomjs.org/download.html
from selenium import webdriver
# 指定driver的绝对路径
driver = webdriver.PhantomJS(executable_path='/home/worker/Desktop/driver/phantomjs')
# driver = webdriver.Chrome(executable_path='/home/worker/Desktop/driver/chromedriver')
# 向一个url发起请求
driver.get("http://www.itcast.cn/")
# 把网页保存为图片
driver.save_screenshot("itcast.png")
# 退出模拟浏览器
driver.quit() # 一定要退出!不退出会有残留进程!
1.3 观察运行效果
- python代码能够自动的调用谷歌浏览或phantomjs无界面浏览器,控制其自动访问网站
1.4 无头浏览器与有头浏览器的使用场景
- 通常在开发过程中我们需要查看运行过程中的各种情况所以通常使用有头浏览器
- 在项目完成进行部署的时候,通常平台采用的系统都是服务器版的操作系统,服务器版的操作系统必须使用无头浏览器才能正常运行
2. selenium的作用和工作原理
利用浏览器原生的API,封装成一套更加面向对象的Selenium WebDriver API,直接操作浏览器页面里的元素,甚至操作浏览器本身(截屏,窗口大小,启动,关闭,安装插件,配置证书之类的)

- webdriver本质是一个web-server,对外提供webapi,其中封装了浏览器的各种功能
- 不同的浏览器使用各自不同的webdriver
知识点:了解 selenium的工作原理
3. selenium的安装以及简单使用
我们以谷歌浏览器的chromedriver为例
3.1 在python虚拟环境中安装selenium模块
pip/pip3 install selenium
3.2 下载版本符合的webdriver
以chrome谷歌浏览器为例
- 查看谷歌浏览器的版本


- 访问https://npm.taobao.org/mirrors/chromedriver,点击进入不同版本的chromedriver下载页面

- 点击notes.txt进入版本说明页面

- 查看chrome和chromedriver匹配的版本

- 根据操作系统下载正确版本的chromedriver
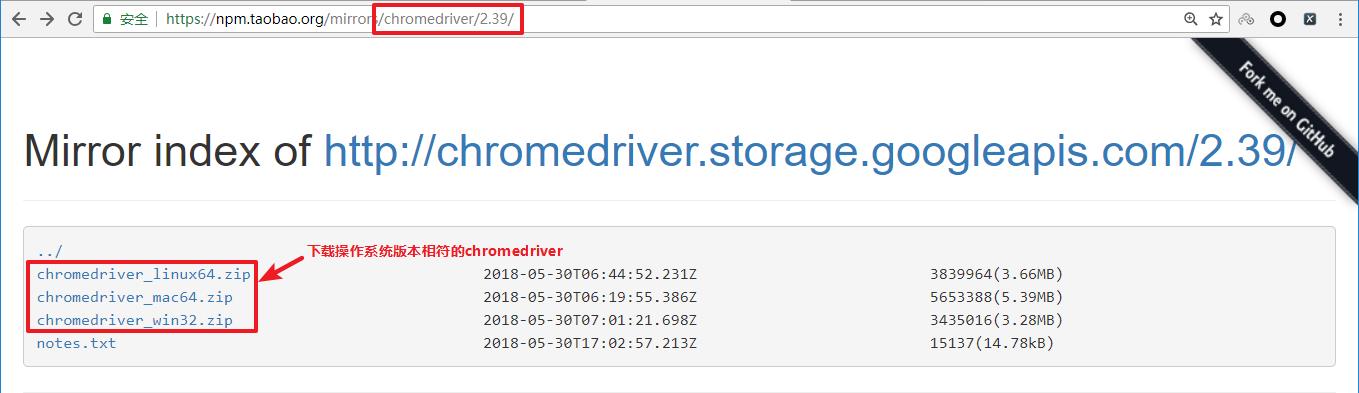
-
解压压缩包后获取python代码可以调用的谷歌浏览器的webdriver可执行文件
-
windows为
chromedriver.exe -
linux和macos为
chromedriver
-
-
chromedriver环境的配置
- windows环境下需要将 chromedriver.exe 所在的目录设置为path环境变量中的路径
- linux/mac环境下,将 chromedriver 所在的目录设置到系统的PATH环境值中
知识点:了解 selenium以及chromedriver的安装
4. selenium的简单使用
接下来我们就通过代码来模拟百度搜索
import time
from selenium import webdriver
# 通过指定chromedriver的路径来实例化driver对象,chromedriver放在当前目录。
# driver = webdriver.Chrome(executable_path='./chromedriver')
# chromedriver已经添加环境变量
driver = webdriver.Chrome()
# 控制浏览器访问url地址
driver.get("https://www.baidu.com/")
# 在百度搜索框中搜索'python'
driver.find_element_by_id('kw').send_keys('python')
# 点击'百度搜索'
driver.find_element_by_id('su').click()
time.sleep(6)
# 退出浏览器
driver.quit()
webdriver.Chrome(executable_path='./chromedriver')中executable参数指定的是下载好的chromedriver文件的路径driver.find_element_by_id('kw').send_keys('python')定位id属性值是’kw’的标签,并向其中输入字符串’python’driver.find_element_by_id('su').click()定位id属性值是su的标签,并点击- click函数作用是:触发标签的js的click事件
知识点:掌握 标签对象click点击以及send_keys输入
加油!
感谢!
努力!
以上是关于爬虫进阶Selenium入门好文,强烈推荐 ! ! !的主要内容,如果未能解决你的问题,请参考以下文章