selenium+chromedriver操作浏览器获取动态数据python爬虫入门进阶(13)
Posted 码农飞哥
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了selenium+chromedriver操作浏览器获取动态数据python爬虫入门进阶(13)相关的知识,希望对你有一定的参考价值。
您好,我是码农飞哥,感谢您阅读本文,欢迎一键三连哦。
😁 1. 社区逛一逛,周周有福利,周周有惊喜。码农飞哥社区,飞跃计划
💪🏻 2. Python基础专栏,基础知识一网打尽。 Python从入门到精通
❤️ 3. Ceph实战,从原理到实战应有尽有。 Ceph实战
❤️ 4. Java高并发编程入门,打卡学习Java高并发。 Java高并发编程入门
关注下方公众号,众多福利免费嫖;加我VX进群学习,学习的路上不孤单

为啥写这篇文章?
上篇文章我们介绍了如何用多线程的方式来提高爬虫效率。还没看的小伙伴可以补看一波。
用生产者消费者模式爬取斗图吧,一次性收获超多表情包【python爬虫入门进阶】(11)
为了方便大家更好的学习交流,我这边建了个Python学习交流群,一群已满。

文章目录
软件环境
| 软件 | 版本 |
|---|---|
| 电脑系统 | mac |
| Chrome | 96.0.4664.93 |
| chromedriver | 96.0.4664.18 |
selenium是什么
这篇文章我们将介绍Selenium这个技术,该技术可以模拟人类在浏览器上的一些行为,自动处理浏览器上的一些行为,比如点击,填充数据,删除cookie等等。一句话总结Selenium相当于一个机器人。
当然,这个机器人必须要有驱动程序去驱动浏览器,不同浏览器上需要不同的驱动程序,在Chrome浏览器上的驱动程序是Chromedriver,只有使用它才能驱动浏览器。
不同浏览器上的driver下载地址
谷歌浏览器驱动下载地址:https://chromedriver.storage.googleapis.com/index.html
火狐浏览器驱动下载地址:https://github.com/mozilla/geckodriver/releases/
PhantomJS驱动下载地址:http://phantomjs.org/download.html
IE浏览器下载地址:http://selenium-release.storage.googleapis.com/index.html
以Chrome浏览器为例
这里需要特别注意的是:要根据当前你Chrome浏览器的版本下载对应版本的chromedriver
比如:我这里Chrome浏览器的版本是:96.0.4664.93,如下图1所示
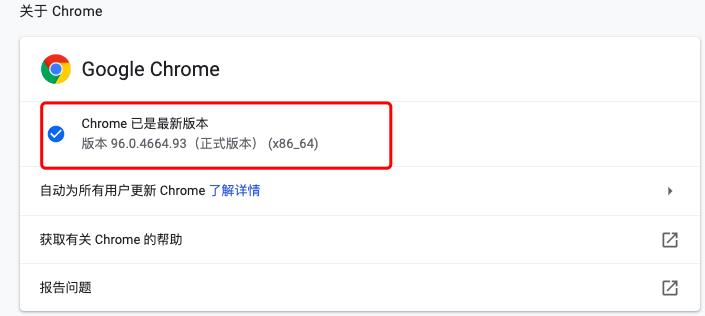
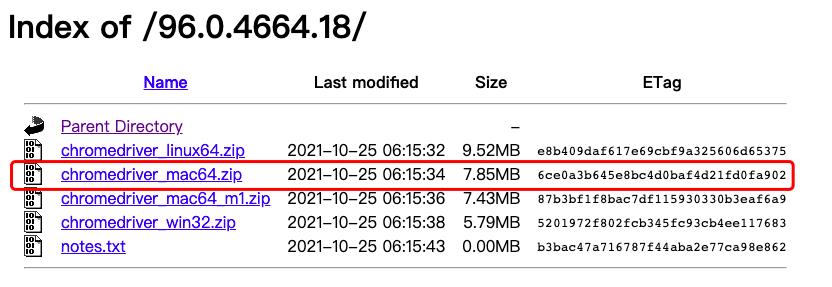
我就需要下载:96.0.4664.18 版本下的chromedriver驱动。如下图2所示:

点进96.0.4664.18 目录里,以看到不同系统对应不同的安装包,这里我的电脑系统是mac系统,所有我选择了chromedriver_mac64.zip 压缩包。如下图3所示:
如果你不按照版本来对应下载的话,就有可能会出现如下图4所示的错误:

给chromedriver配置环境变量
解压之后可以得到chromedriver程序,将该程序放在/usr/local/bin/ 目录下。
这里以Mac系统为例进行说明:
- 打开终端输入:
vim ~/.bash_profile命令,向.bash_profile文件中写入如下配置。按i进入编辑状态,
alias chromedriver='/usr/local/bin/chromedriver'

编辑完成之后按esc 退出编辑。然后,输入:wq! 保存编辑结果。
3. 接着在终端输入 source ~/.bash_profile 使得环境变量生效。

使用selenium
安装selenium
在使用selenium之前还是需要通过pip安装一下selenium包。安装命令如下:
pip install selenium
安装好之后就是导入包进行使用了。
from selenium import webdriver
# 调用环境变量指定的
# driver = webdriver.Chrome()
# 如果没有在环境变量指定Chromedriver的位置
executable_path = '/usr/local/bin/chromedriver'
driver = webdriver.Chrome(executable_path=executable_path)
driver.get("http://www.baidu.com")
# 打印获取到页面源码
print(driver.page_source)
如果没有在环境变量中指定chromedriver的位置,那么在调用webdriver.Chrome 方法时就需要在executable_path参数中传入Chromedriver的位置。
如果在前面给chromedriver配置了环境变量,则直接调用driver = webdriver.Chrome() 方法即可。
这里通过selenium打卡Chrome浏览器,并访问百度首页。运行后的效果如下图5所示:通过selenium打卡的浏览器窗口会有Chrome 正收到自动测试软件的控制 的提示。

selenium的常用操作
更多详细的操作可以看官方文档。
关闭页面
#关闭当前页面
driver.close()
#退出整个浏览器
driver.quit()
定位页面元素
定位页面元素的方法统一调用driver.find_element 方法,其语法结构是:
find_element(self, by=By.ID, value=None)
默认是根据ID查找元素,value 指定的是查找的关键字。
如图6所示,点击查看By类的源代码可以看到

1. 根据id来查找某个元素
根据id来查找某个元素只需要将by的值传入为By.ID。这里的id指的是标签的id属性。
from selenium.webdriver.common.by import By
# 根据ID查找某个元素
driver.get("https://so.csdn.net/so/search")
input_tag = driver.find_element(by=By.ID, value='keyword')
input_tag.send_keys('码农飞哥,爬虫')
这里以CSDN的搜索框为例,找到搜索框元素的id是keyword。send_keys 方法用于向匹配到的元素输入关键字。运行之后得到的效果如下图7

2.根据类名查找元素
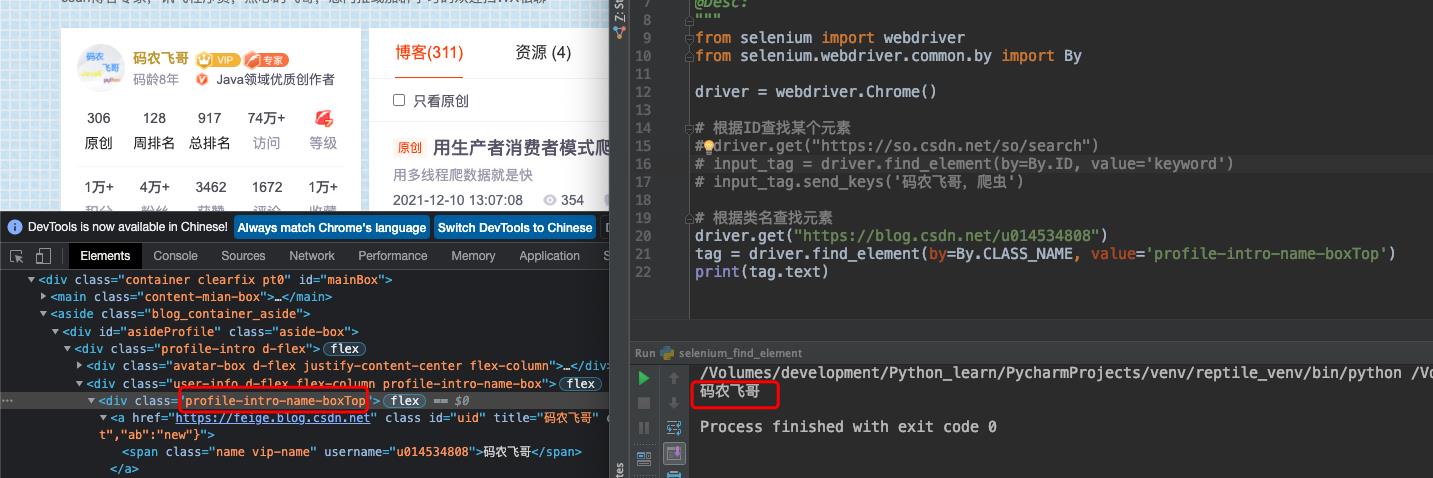
这里的类名指的是标签的class属性。如下图8所示现有标签元素<div class="profile-intro-name-boxTop"> ,我们就可以通过类名来找到这个标签元素。传入的by参数是By.CLASS_NAME。
driver.get("https://blog.csdn.net/u014534808")
tag = driver.find_element(by=By.CLASS_NAME, value='profile-intro-name-boxTop')
print(tag.text)
运行结果如下图8所示:
3. 根据name属性的值来查找元素
driver.get("https://blog.csdn.net/u014534808")
tag = driver.find_element(by=By.NAME, value='report')
print(tag)

4. 根据标签名来查找元素
5. 根据xpath语法来获取元素
driver.get("https://blog.csdn.net/u014534808")
feige_tag = driver.find_element(by=By.XPATH,
value='//div[@class="profile-intro-name-boxFooter"]//a')
print(feige_tag.text)
driver.close()
运行结果是:

这里需要注意的是不能提取到标签的某个属性。比如://div[@class="profile-intro-name-boxFooter"]//a/@href 这样会报错的。因为这个方法选择的是元素。
6. 根据css选择器选择元素
需要注意的是,find_element 是获取第一个满足条件的元素,find_elements 是获取所有满足条件的元素。
driver.get("https://blog.csdn.net/u014534808")
class_tags = driver.find_element(by=By.CSS_SELECTOR, value='.article-list .article-item-box')
print(class_tags)
总结
本文简单介绍了selenium的使用
粉丝专属福利
软考资料:实用软考资料
面试题:5G 的Java高频面试题
学习资料:50G的各类学习资料
脱单秘籍:回复【脱单】
并发编程:回复【并发编程】
👇🏻 验证码 可通过搜索下方 公众号 获取👇🏻
以上是关于selenium+chromedriver操作浏览器获取动态数据python爬虫入门进阶(13)的主要内容,如果未能解决你的问题,请参考以下文章
谷歌浏览器加载驱动(chromedriver)——selenium