当你用Python爬取网站遇到反爬,你应该这样做,轻松解决反爬问题
Posted 梦子mengy7762
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了当你用Python爬取网站遇到反爬,你应该这样做,轻松解决反爬问题相关的知识,希望对你有一定的参考价值。

爬虫和反爬虫就想矛与盾,一直在不停的碰撞!最后,如果你的时间不是很紧张,并且又想快速的提高,最重要的是不怕吃苦,建议你可以联系维:762459510 ,那个真的很不错,很多人进步都很快,需要你不怕吃苦哦!大家可以去添加上看一下~
参数加密
参数加密指的是在请求中需要加上类似token、uuid 字段,例如在某个请求中query string parameters中有_token和uuid、customerKey等字段

解决方法
刚开始遇到这个是一脸懵逼的,验证发现有些参数不是必须的,比如uuid,uuid在维基百科上是:通用唯一识别码,估计没啥作用,python也有内置的uuid生成库

登录问题
很多网站数据是登录可见,那么就必须要开发该网站的登录系统了。
登录可能会遇到的一些问题:
登录过程中遇到的验证码(下面会说)
cookies持久化问题
账号被封禁问题
解决方法
登录账号获得cookies后,经过一段时间,cookies就可能会失效,具体网站情况不同,这时候就必须有个脚本,来保证cookies有效
账号做出一些跟正常用户不同的操作就会产生异常,别人很容易就发现。所以就让你的账号像正常人一样。最后,如果你的时间不是很紧张,并且又想快速的提高,最重要的是不怕吃苦,建议你可以联系维:762459510 ,那个真的很不错,很多人进步都很快,需要你不怕吃苦哦!大家可以去添加上看一下~
最近看到有人再问豆瓣登录采集影评导致被封号的事情,豆瓣我以前也被封过,到现在也没有解封
依据用户管理细则,此帐号已被永久停用。停用时间:2017-09-29
如有疑问,请发送邮件到help@douban.com
我的建议是:
- 有能力的多注册账号,账号被封了就再去注册呗
- 手机app抓包,app不需要登录,而且可以持续抓最新评论

图形验证码
验证码一直是反爬虫利器,从简单的数字识别,到复杂的滑动拼图、图片点选等等。有兴趣的来试试破解 ,感觉很头疼。
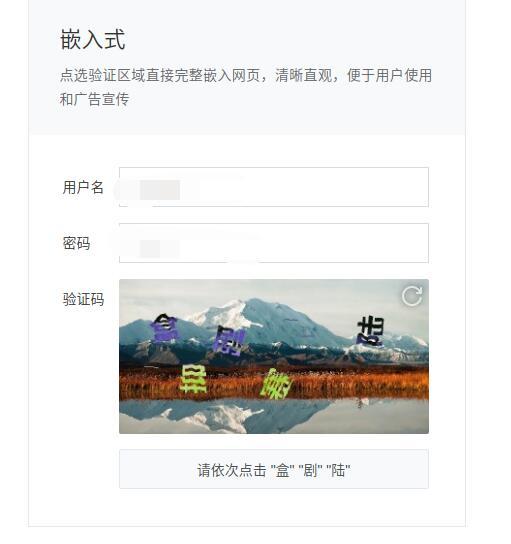
解决方法
例如上图,这是我现在遇到的一种验证码情况,依次点击几个文字。
如果是自己来做的话,会考虑这样:
将验证码图片部分截图或下载回来
对图片进行OCR,提取文字
文字识别,获取坐标
使用selenium根据坐标点击
这只是初步思路,但想法很容易,做起来却没那么简单。
在Github上找到大佬写的方法 ,知乎上也有
那么如果直接接入第三方打码平台来,那就会简单很多,在实际开发中为了提高准确性,更多会使用打码平台。

以上是关于当你用Python爬取网站遇到反爬,你应该这样做,轻松解决反爬问题的主要内容,如果未能解决你的问题,请参考以下文章