深度学习——计算机视觉
Posted 追光者_GY(*>.<*)
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习——计算机视觉相关的知识,希望对你有一定的参考价值。
提高模型泛化能力的方法——图像增广和微调
图像增广
图像增广(image augmentation)技术通过对训练图像做一系列随机改变,来产生相似但又不同的训练样本,从而扩大训练数据集的规模。
图像增广的另一种解释是,随机改变训练样本可以降低模型对某些属性的依赖,从而提高模型的泛化能力。
例如,我们可以对图像进行不同方式的裁剪,使感兴趣的物体出现在不同位置,从而减轻模型对物体出现位置的依赖性。我们也可以调整亮度、色彩等因素来降低模型对色彩的敏感度。可以说,在当年AlexNet的成功中,图像增广技术功不可没。
为了在预测时得到确定的结果,我们通常只将图像增广应用在训练样本上,而不在预测时使用含随机操作的图像增广。
微调
问题:假设我们想从图像中识别出不同种类的椅子,然后将购买链接推荐给用户。一种可能的方法是先找出100种常见的椅子,为每种椅子拍摄1,000张不同角度的图像,然后在收集到的图像数据集上训练一个分类模型。这个椅子数据集虽然可能比Fashion-MNIST数据集要庞大,但样本数仍然不及ImageNet数据集中样本数的十分之一。这可能会导致适用于ImageNet数据集的复杂模型在这个椅子数据集上过拟合。同时,因为数据量有限,最终训练得到的模型的精度也可能达不到实用的要求。
解决方法:
1.收集更多的数据。然而,收集和标注数据会花费大量的时间和资金。
2.应用迁移学习(transfer learning),将从源数据集学到的知识迁移到目标数据集上。例如,虽然ImageNet数据集的图像大多跟椅子无关,但在该数据集上训练的模型可以抽取较通用的图像特征,从而能够帮助识别边缘、纹理、形状和物体组成等。这些类似的特征对于识别椅子也可能同样有效。
接下来介绍迁移学习中的一种常用技术:微调
微调由以下4步构成:
- 在源数据集(如ImageNet数据集)上预训练一个神经网络模型,即源模型。
- 创建一个新的神经网络模型,即目标模型。它复制了源模型上除了输出层外的所有模型设计及其参数。我们假设这些模型参数包含了源数据集上学习到的知识,且这些知识同样适用于目标数据集。我们还假设源模型的输出层跟源数据集的标签紧密相关,因此在目标模型中不予采用。
- 为目标模型添加一个输出大小为目标数据集类别个数的输出层,并随机初始化该层的模型参数。
- 在目标数据集(如椅子数据集)上训练目标模型。我们将从头训练输出层,而其余层的参数都是基于源模型的参数微调得到的。
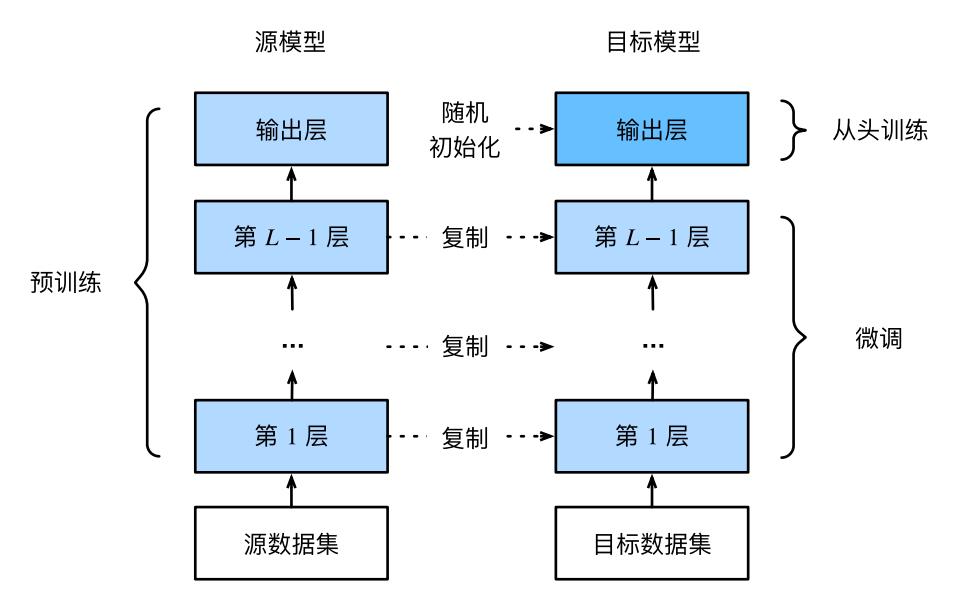
当目标数据集远小于源数据集时,微调有助于提升模型的泛化能力。
目标检测和边界框
很多时候图像里有多个我们感兴趣的目标,我们不仅想知道它们的类别,还想得到它们在图像中的具体位置。在计算机视觉里,我们将这类任务称为目标检测(object detection)或物体检测。
在目标检测里不仅需要找出图像里面所有感兴趣的目标,而且要知道它们的位置。位置一般由矩形边界框来表示。
锚框
目标检测算法通常会在输入图像中采样大量的区域,然后判断这些区域中是否包含我们感兴趣的目标,并调整区域边缘从而更准确地预测目标的真实边界框(ground-truth bounding box)。
不同的
模型使用的区域采样方法可能不同。这里我们介绍其中的一种方法:
它以每个像素为中心生成多个大小和宽高比(aspect ratio)不同的边界框。这些边界框被称为锚框(anchor box)。
写到这里下不下去了,后续需要补充,敬请期待。。。。
以上是关于深度学习——计算机视觉的主要内容,如果未能解决你的问题,请参考以下文章