Elasticsearch:处理 Elasticsearch 中数据更新的并发
Posted Elastic 中国社区官方博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch:处理 Elasticsearch 中数据更新的并发相关的知识,希望对你有一定的参考价值。
在我之前的我文章 “Elasticsearch:深刻理解文档中的 verision 及乐观并发控制” 我详细地描述了 Elasticsearch 中的乐观并发控制。在今天的文章中,我将来详述如何来处理这类并发。
问题
假如说有两个客户端同时读取一个页面的阅读数,并把当前的阅读数增加一。
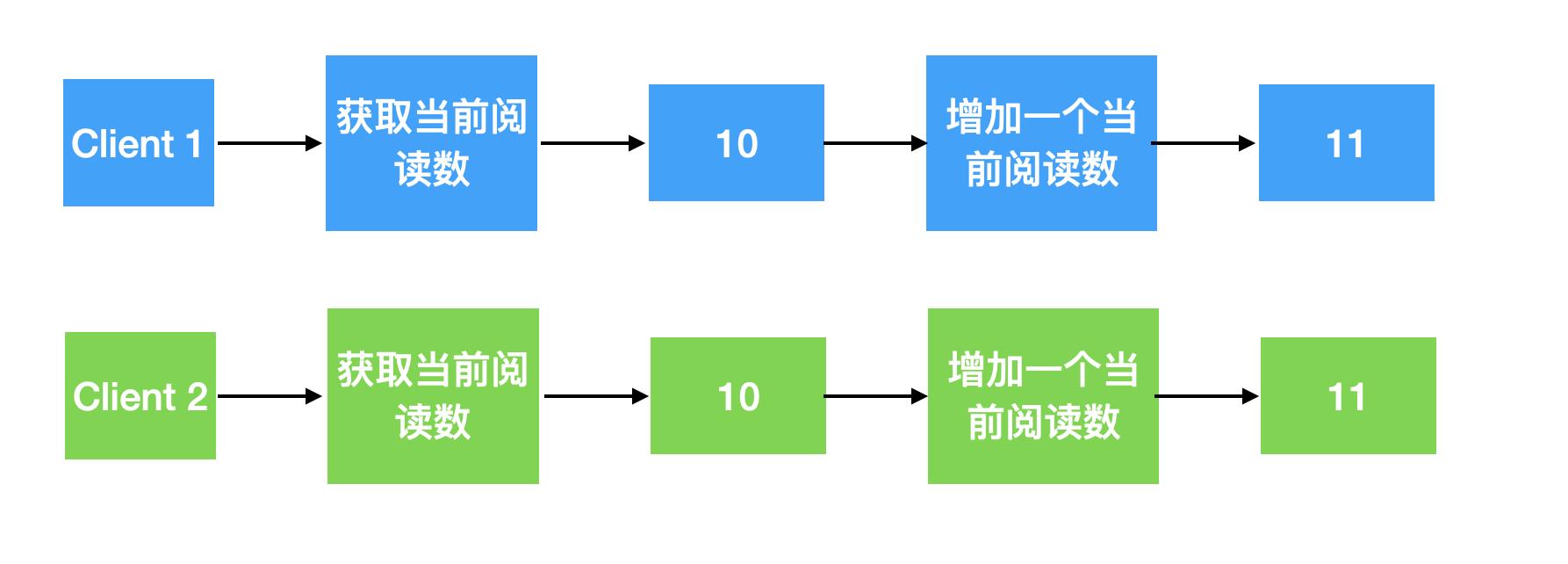 从上面可以看出来,由于更新一个数据它不是原子操作(原子是最小的,不能再分的操作)。通常更新一个数值需要分为三个步骤: 读取 -> 修改 -> 更新 。假如 Client 1 和 Client 2 几乎是在同一的时间读取的,那么从上面可以看出来最终的结果会是 11 而不是我们之前想到的 12。
从上面可以看出来,由于更新一个数据它不是原子操作(原子是最小的,不能再分的操作)。通常更新一个数值需要分为三个步骤: 读取 -> 修改 -> 更新 。假如 Client 1 和 Client 2 几乎是在同一的时间读取的,那么从上面可以看出来最终的结果会是 11 而不是我们之前想到的 12。
Elasticsearch 为了解决这个问题推出了 Optimistic concurrency control (乐观并发控制)。
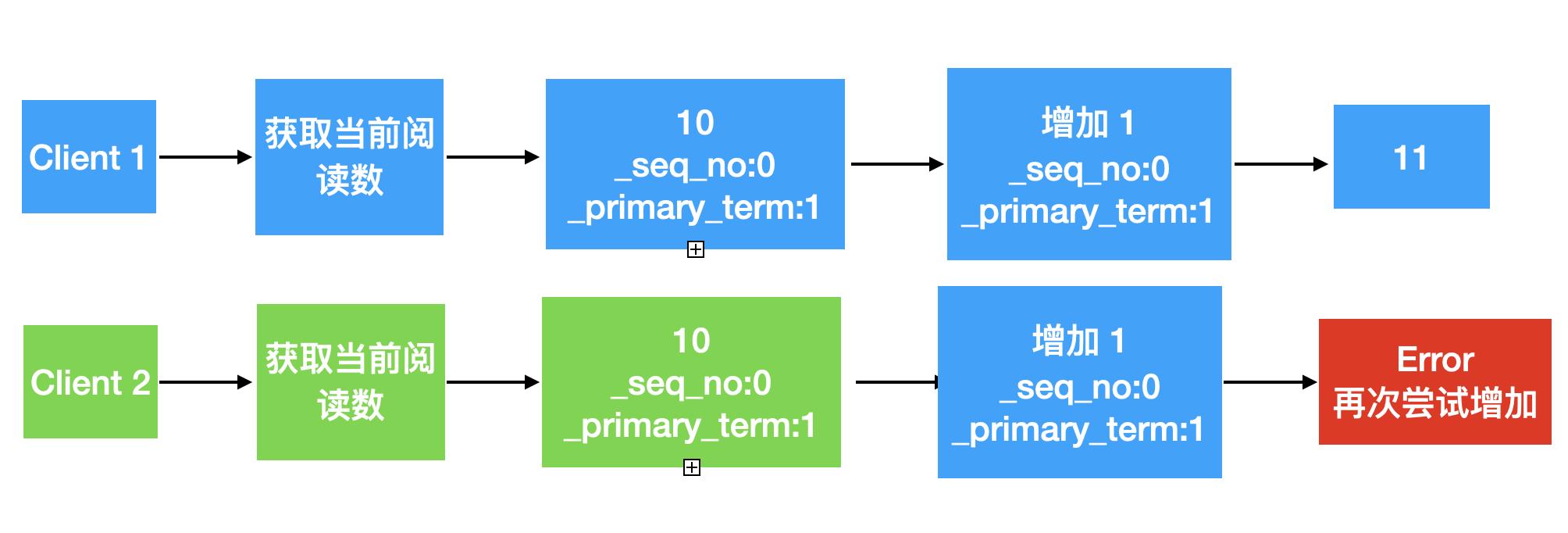
从之前的文章 “Elasticsearch:深刻理解文档中的 verision 及乐观并发控制”,我们可以看出来,当我们每次更新一个文档时,_version 会自动增加 1,同时它的 _seq_no 及 _primary_term 也会随着变化。每当我们更新一个文档时,我们可以添加 _seq_no 及 _primary_term 参数作为请求的一部分。当两个客户端同时更新一个文档并带有同样的 _seq_no 及 _primary_term 参数,只有其中的一个会成功,而另外一个会失败。
在实际的使用中,当冲突发生时,我们可以使用 retry_on_conflicts=N 来尝试 N 次更新。具体说明可以参考官方文档。
下面我们使用一个具体的例子来进行展示。我们首先来创建一个如下的文档:
PUT twitter/_doc/1
{
"content": "This is cool"
}我们可以通过如下的命令来查看这个文档的信息:
GET twitter/_doc/1上面的命令显示:
{
"_index" : "twitter",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"_seq_no" : 0,
"_primary_term" : 1,
"found" : true,
"_source" : {
"content" : "This is cool"
}
}当前的文档的 _version 为 1。
接下来,我们使用如下的命令来进行更新:
PUT twitter/_doc/1?if_seq_no=0&if_primary_term=1
{
"content": "This is not cool"
}上面的命令显示的结果为:
{
"_index" : "twitter",
"_type" : "_doc",
"_id" : "1",
"_version" : 2,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1
}上面显示 _seq_no 为 1,_primary_term 为 1。更新是成功的。
现在假如另外一个客户端,还是使用 _seq_no 为 0 及 _primary_term 为 1 来更新:
PUT twitter/_doc/1?if_seq_no=0&if_primary_term=1
{
"content": "This is not cool"
}那么我可以看到如下的信息:
{
"error" : {
"root_cause" : [
{
"type" : "version_conflict_engine_exception",
"reason" : "[1]: version conflict, required seqNo [0], primary term [1]. current document has seqNo [1] and primary term [1]",
"index_uuid" : "HrN8iWR6QL6q2NeLPbDVoQ",
"shard" : "0",
"index" : "twitter"
}
],
"type" : "version_conflict_engine_exception",
"reason" : "[1]: version conflict, required seqNo [0], primary term [1]. current document has seqNo [1] and primary term [1]",
"index_uuid" : "HrN8iWR6QL6q2NeLPbDVoQ",
"shard" : "0",
"index" : "twitter"
},
"status" : 409
}上面显示当前的 _seq_no 已经是 1 了,所以更新是不成功的。
但是我们可以使用如下的命令来进行尝试:
POST twitter/_doc/1/_update?retry_on_conflict=5
{
"doc": {
"content": "This is excellent"
}
}上面的命令和我们通常的命令并没有多少区别。在请求中我们使用了 retry_on_conflict 参数作为请求的一部分。在 Elasticsearch 的实现中,它实际上是读取当前的版本信息,_seq_no 及 _primary_term 信息。如果存在冲突,那么它将尝试 5 次更新文档的操作。如果超过 5 次不成功,那么就返回错误信息。
上面命令的返回信息为:
{
"_index" : "twitter",
"_type" : "_doc",
"_id" : "1",
"_version" : 3,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 2,
"_primary_term" : 1
}以上是关于Elasticsearch:处理 Elasticsearch 中数据更新的并发的主要内容,如果未能解决你的问题,请参考以下文章
Spark SQL大数据处理并写入Elasticsearch