Spark SQL大数据处理并写入Elasticsearch
Posted HarvardFly
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark SQL大数据处理并写入Elasticsearch相关的知识,希望对你有一定的参考价值。
SparkSQL(Spark用于处理结构化数据的模块)
通过SparkSQL导入的数据可以来自mysql数据库、Json数据、Csv数据等,通过load这些数据可以对其做一系列计算
下面通过程序代码来详细查看SparkSQL导入数据并写入到ES中:
数据集:北京市PM2.5数据
Spark版本:2.3.2
Python版本:3.5.2
mysql-connector-java-8.0.11 下载
ElasticSearch:6.4.1
Kibana:6.4.1
elasticsearch-spark-20_2.11-6.4.1.jar 下载
具体代码:


1 # coding: utf-8 2 import sys 3 import os 4 5 pre_current_dir = os.path.dirname(os.getcwd()) 6 sys.path.append(pre_current_dir) 7 from pyspark.sql import SparkSession 8 from pyspark.sql.types import * 9 from pyspark.sql.functions import udf 10 from settings import ES_CONF 11 12 current_dir = os.path.dirname(os.path.realpath(__file__)) 13 14 spark = SparkSession.builder.appName("weather_result").getOrCreate() 15 16 17 def get_health_level(value): 18 """ 19 PM2.5对应健康级别 20 :param value: 21 :return: 22 """ 23 if 0 <= value <= 50: 24 return "Very Good" 25 elif 50 < value <= 100: 26 return "Good" 27 elif 100 < value <= 150: 28 return "Unhealthy for Sensi" 29 elif value <= 200: 30 return "Unhealthy" 31 elif 200 < value <= 300: 32 return "Very Unhealthy" 33 elif 300 < value <= 500: 34 return "Hazardous" 35 elif value > 500: 36 return "Extreme danger" 37 else: 38 return None 39 40 41 def get_weather_result(): 42 """ 43 获取Spark SQL分析后的数据 44 :return: 45 """ 46 # load所需字段的数据到DF 47 df_2017 = spark.read.format("csv") \\ 48 .option("header", "true") \\ 49 .option("inferSchema", "true") \\ 50 .load("file://{}/data/Beijing2017_PM25.csv".format(current_dir)) \\ 51 .select("Year", "Month", "Day", "Hour", "Value", "QC Name") 52 53 # 查看Schema 54 df_2017.printSchema() 55 56 # 通过udf将字符型health_level转换为column 57 level_function_udf = udf(get_health_level, StringType()) 58 59 # 新建列healthy_level 并healthy_level分组 60 group_2017 = df_2017.withColumn( 61 "healthy_level", level_function_udf(df_2017[\'Value\']) 62 ).groupBy("healthy_level").count() 63 64 # 新建列days和percentage 并计算它们对应的值 65 result_2017 = group_2017.select("healthy_level", "count") \\ 66 .withColumn("days", group_2017[\'count\'] / 24) \\ 67 .withColumn("percentage", group_2017[\'count\'] / df_2017.count()) 68 result_2017.show() 69 70 return result_2017 71 72 73 def write_result_es(): 74 """ 75 将SparkSQL计算结果写入到ES 76 :return: 77 """ 78 result_2017 = get_weather_result() 79 # ES_CONF配置 ES的node和index 80 result_2017.write.format("org.elasticsearch.spark.sql") \\ 81 .option("es.nodes", "{}".format(ES_CONF[\'ELASTIC_HOST\'])) \\ 82 .mode("overwrite") \\ 83 .save("{}/pm_value".format(ES_CONF[\'WEATHER_INDEX_NAME\'])) 84 85 86 write_result_es() 87 spark.stop()
将mysql-connector-java-8.0.11和elasticsearch-spark-20_2.11-6.4.1.jar放到Spark的jars目录下,提交spark任务即可。
注意:
(1) 如果提示:ClassNotFoundException Failed to find data source: org.elasticsearch.spark.sql.,则表示spark没有发现jar包,此时需重新编译pyspark:
cd /opt/spark-2.3.2-bin-hadoop2.7/python
python3 setup.py sdist
pip install dist/*.tar.gz
(2) 如果提示:Multiple ES-Hadoop versions detected in the classpath; please use only one ,
则表示ES-Hadoop jar包有多余的,可能既有elasticsearch-hadoop,又有elasticsearch-spark,此时删除多余的jar包,重新编译pyspark 即可
执行效果:
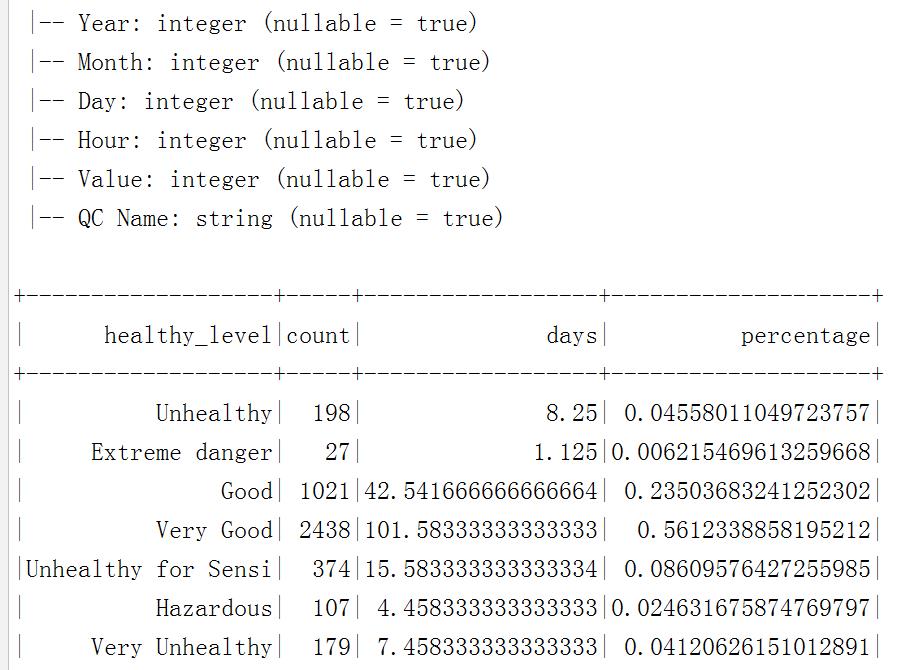
更多源码请关注我的github, https://github.com/a342058040/Spark-for-Python ,Spark相关技术全程用python实现,持续更新
以上是关于Spark SQL大数据处理并写入Elasticsearch的主要内容,如果未能解决你的问题,请参考以下文章