Zeppelin可视化数据分析
Posted 赵广陆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Zeppelin可视化数据分析相关的知识,希望对你有一定的参考价值。
目录
1 Zeppelin
1.1. 安装
-
下载 Zeppelin
在
Files/setup中已经准备好了压缩包 -
上传到 master01 中
-
解压缩
zeppelin-0.8.2-bin-all.tgzcd /home/vagrant mkdir /opt/zeppelin tar -xzvf zeppelin-0.8.2-bin-all.tgz -C /opt cd /opt mv zeppelin-0.8.2-bin-all zeppelin -
创建 Zeppelin 的环境配置
cd /opt/zeppelin/conf cp zeppelin-env.sh.template zeppelin-env.sh cp zeppelin-site.xml.template zeppelin-site.xml -
修改 Zeppelin 配置文件, 在
zeppelin/conf/zeppelin-env.sh中加入如下环境变量export JAVA_HOME=/usr/java/jdk1.8.0_181-cloudera export HADOOP_CONF_DIR=/etc/hadoop/conf:/etc/hive/conf export HADOOP_HOME=/opt/cloudera/parcels/CDH/lib/hadoop export SPARK_HOME=/opt/cloudera/parcels/CDH/lib/spark export MASTER=yarn-client export ZEPPELIN_LOG_DIR=/var/log/zeppelin export ZEPPELIN_PID_DIR=/var/run/zeppelin export ZEPPELIN_WAR_TEMPDIR=/var/tmp/zeppelin -
修改 Zeppelin 配置文件, 在
zeppelin/conf/zeppelin-site.xml中修改 IP 和端口<property> <name>zeppelin.server.addr</name> <value>0.0.0.0</value> <description>Server binding address</description> </property> <property> <name>zeppelin.server.port</name> <value>8099</value> <description>Server port.</description> </property> -
启动 Zeppelin
cd /opt/zeppelin/bin ./zeppelin-daemon.sh start
1.2. Zeppelin的作用
-
Zeppelin 是一个多用途笔记本工具, 其每一个笔记可以包含如下的条目
- Markdown
- Spark 程序
- 在某个数据库上执行的 SQL
- Flink 程序
- 等…
-
Zeppelin 可以对数据进行可视化
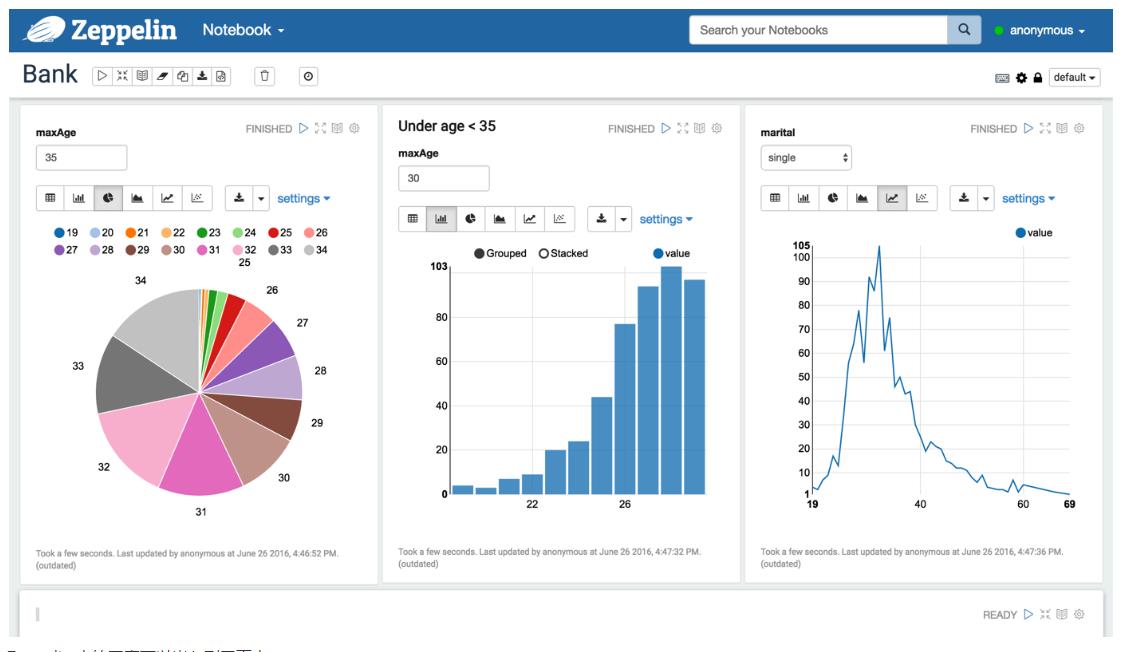
- Zeppelin 中的图表可以嵌入到网页中
- 所以 Zeppelin 可以做这些事
- 数据分析的协作
- 作为 BI 使用
- 机器学习中的数据探索
1.3. Zeppelin 入门使用
使用 Zeppelin 创建一个测试笔记本, 并编写 Spark 程序, 在开始之前, 需要在 HDFS 的目录 /user/admin/dataset/ 中上传我们所需要的数据集 Files/dataset/house_price_train.csv
- 创建笔记本
- 编写一行 Markdown, 使用
shift + enter运行显示

- 编写一个 Spark 程序并运行
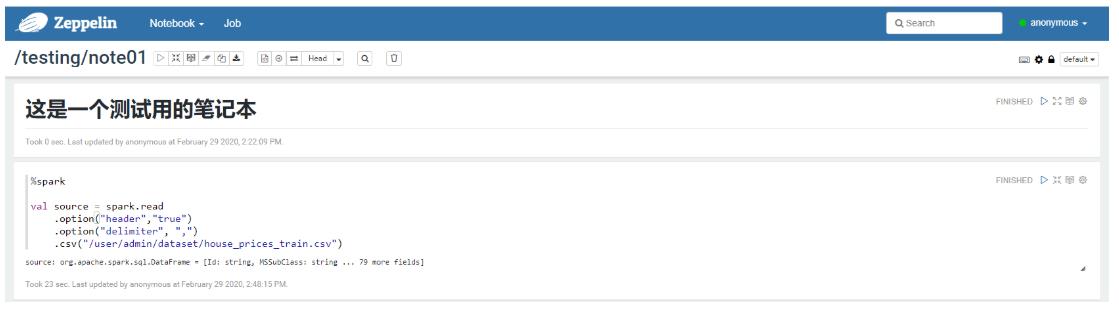
- 注册为临表并使用 SQL 可视化
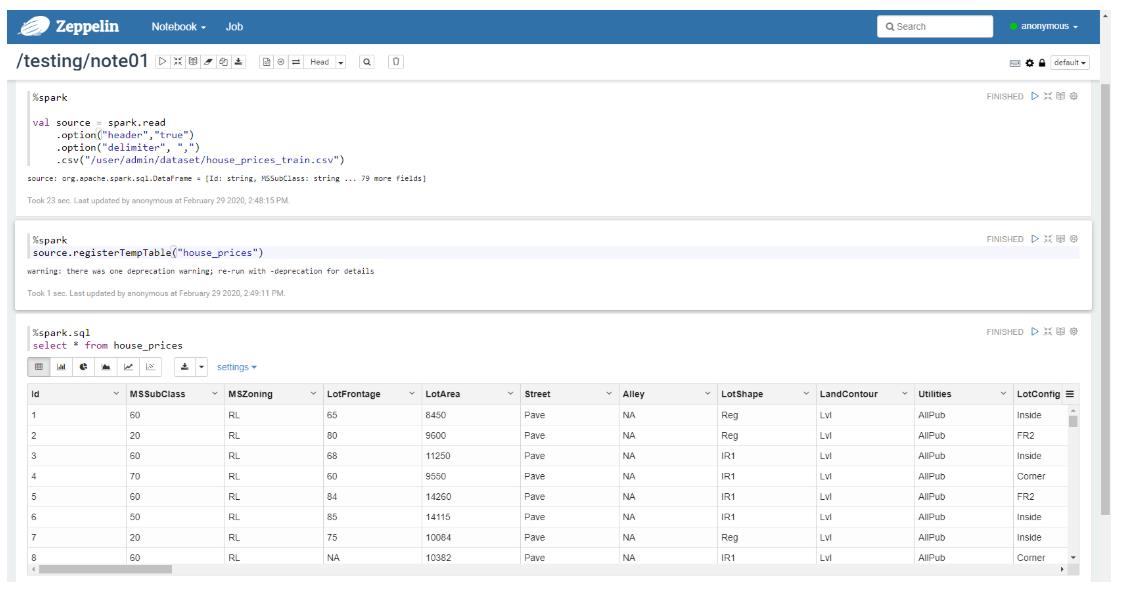
2. 房价预测详细思路
- 目标
- 能够完成简单的机器学习任务
- 步骤
- 绘制房价直方图, 审视数据分布
- 绘制散点图, 审视数据和结果之间的关系
- 选择模型
- 特征处理之空值处理
- 特征处理之组合特征
- 特征处理之特征编码
- 简要实现模型
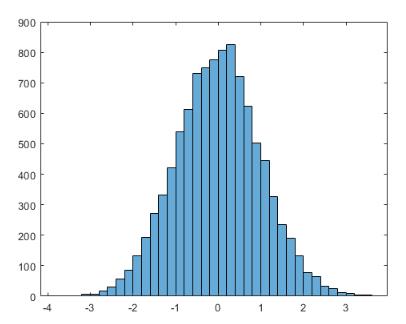
2.1. 绘制房价直方图
通过绘制房价的直方图, 就可以了解 我们要预测的值的分布情况
通过了解目标的分布情况, 有助于我们理解我们要做的事情, 为算法选择和结果验证提供支撑
- 需求
- 根据数据集, 预测房价
-
读取数据
%spark val source = spark.read .option("header", "true") .option("delimiter", ",") .csv("/user/admin/dataset/house_prices_train.csv") -
查看元数据
%spark source.printSchema -
查看房价概况
%spark import spark.implicits._ source.describe("SalePrice").show -
为房价直方图准备数据
-
简单来说, 直方图就是二维坐标系中, x 轴为房价, y 轴为某一个房价出现的次数

-
直方图一般把数据分组放置于 x 轴, 组中数据的个数映射到 y 轴, 数据准备如下
%spark import org.apache.spark.ml.feature.QuantileDiscretizer import spark.implicits._ import org.apache.spark.sql.types.LongType import org.apache.spark.sql.functions._ val salePrice = source.select('SalePrice cast(LongType)) val qd = new QuantileDiscretizer() .setInputCol("SalePrice") .setOutputCol("Bin") .setNumBuckets(60) qd.fit(salePrice) .transform(salePrice) .groupBy('Bin) .agg(avg('SalePrice) as "avg_price", count('Bin) as "count") .registerTempTable("sale_price_hist")
-
-
绘图
%spark.sql select * from sale_price_hist
通过这张图, 我们可以总结出来数据的大致情况
- 呈偏态分布
- 有明显尖峰
2.2. 绘制数据和房价之间的散点图
绘制散点图有助于我们理解 标签(要预测的值)和某一维度数据之间的关系
如果连哪一列数据更重要, 就谈不上模型
-
注册 Source 为临时表
%spark source.registerTempTable("house_price") -
绘制房屋质量和房价之间的关系
%spark.sql select YearBuilt, SalePrice from house_price -
绘制居住面积和房价之间的关系
%spark.sql select GrLivArea, SalePrice from house_price -
绘制地下室面积和房价之间的关系
%spark.sql select TotalBsmtSF, SalePrice from house_price
通过这些图, 我们可以确定一些事情
- 这三个属性和结果之间都是正相关的
- 这三个属性和结果之间并非简单的线性关系
- 通过散点图, 还可以观察到一些异常值, 考虑去掉无关模型的异常值有助于提高模型准确率
2.3. 选择模型
- 学习特征中的规律, 使用算法生成模型
- 把新的输入模型, 产生预测结果
- 其实很难通过经验和特征准确的预知哪个模型效果更好
2.4. 空值处理
当我们使用算法 “学习” 数据中的规律时, 无意义的值会影响学习效果
- 决定模型优劣的主因还是特征的处理
- 大致超过八成的时间是处理数据的
- 空值类型
- null
- NaN
- “NA”
- 异常值
-
识别缺失值
- 缺失值有三种, 一种是
null, 一种是NaN, 一种是NA这样的字符串 - 前两种比较好处理, Spark 提供有
dropNa和dropNaN之类的方法可以处理 - 第三种缺失值处理的第一步要先识别缺失值
- 极端情况下, 可以如下做法, 收集数据集中可能的缺失值
%spark import org.apache.spark.sql.functions._ source.columns.map(c => { source.groupBy(col(c)).agg(first(col(c)) as "first").show() }) // 有缺失值的列为 Alley(小路), MasVnrType(表层砌体), BsmtQual(地下室高度) 等... // 而且整个数据集字符串的缺失值类型都是 NA - 缺失值有三种, 一种是
-
过滤缺失值的方式
- 如果一列数据有太多缺失值, 删除此列
- 使用均值, 中值, 众数, 随机数等替代缺失值, 但是不推荐, 因为这就等于认为添加噪声, 降低数据质量
- 拆值, 比如说性别有男, 女, 缺失, 三种状态, 拆成三列, 是否男, 是否女, 是否缺失, 这样最为精确
%spark import spark.implicits._ import org.apache.spark.sql.functions._ import org.apache.spark.sql.types.IntegerType source.agg(sum(('Alley === "NA").cast(IntegerType)) / count('Alley)).show // 发现 Alley 这一列的 NA 数量高达 93%
2.5. 顺序特征编码
人类可以理解装修质量的低中高是有顺序的, 但是以文字形式出现的话, 计算机是无法理解的
有一些特征, 存在明显的顺序性, 比如说身高分三档, 矮, 中, 高, 就明显具备这种顺序性, 如果将文字形式的特征表示为具备顺序性的 123 时, 会提升 “学习” 效果, 让计算机也可以识别我们所理解的顺序
ExterQual 的含义是 外部质量, 取值由低到高为 (Ex, Gd, TA, Fa), 我们选择这一列, 示例如何顺序编码
%spark
import spark.implicits._
import org.apache.spark.sql.functions._
def to_level(q: String): Int = {
q match {
case "Ex" => 1
case "Gd" => 2
case "TA" => 3
case "Fa" => 4
case _ => 0
}
}
val to_level_udf = udf(to_level _)
source.select(to_level_udf('ExterQual)).show
2.6. 组合新特征
房屋面积对房价的影响不可谓不大, 如果能增加一个关于房屋面积的列, 会对模型有正面的影响
数据集中关于房屋面积的列有三个, 地下室面积 TotalBsmtSF, 一楼面积 1stFlrSF, 二楼面积 2ndFlrSF
可以增加一个地下地上总面积的列
import spark.implicits._
source.select(('TotalBsmtSF + source.col("1stFlrSF") + source.col("2ndFlrSF")) as "TotalSF").show
2.7. 特征编码
很多算法无法对枚举类型的字符串进行处理, 需要对其转为可以处理的数值类型
-
在数据集中有很多列的数据是字符串枚举, 算法无法直接处理
%spark val cols = Array( "BsmtFinType1", "MasVnrType", "Foundation", "HouseStyle", "Functional", "BsmtExposure", "GarageFinish", "Street", "ExterQual", "PavedDrive", "ExterCond", "KitchenQual", "HeatingQC", "BsmtQual", "FireplaceQu", "GarageQual", "PoolQC" ) source.select("BsmtFinType1", cols:_*).show -
可以将这些文本数据转为算法可以理解的数值型, 就可以看到这些字符串的数据已经是数值的形式了
%spark import org.apache.spark.ml.feature.StringIndexer import org.apache.spark.sql.DataFrame val cols = Array( "BsmtFinType1", "MasVnrType", "Foundation", "HouseStyle", "Functional", "BsmtExposure", "GarageFinish", "Street", "ExterQual", "PavedDrive", "ExterCond", "KitchenQual", "HeatingQC", "BsmtQual", "FireplaceQu", "GarageQual", "PoolQC" ) var indexerDF: DataFrame = null for (col <- cols) { val stringIndexer = new StringIndexer() .setInputCol(col) .setOutputCol(s"${col}_index") if (indexerDF == null) { indexerDF = stringIndexer.fit(source).transform(source) } else { indexerDF = stringIndexer.fit(indexerDF).transform(indexerDF) } } val indexCols = cols.map(col => s"${col}_index") indexerDF.select(indexCols.head, indexCols:_*).show() -
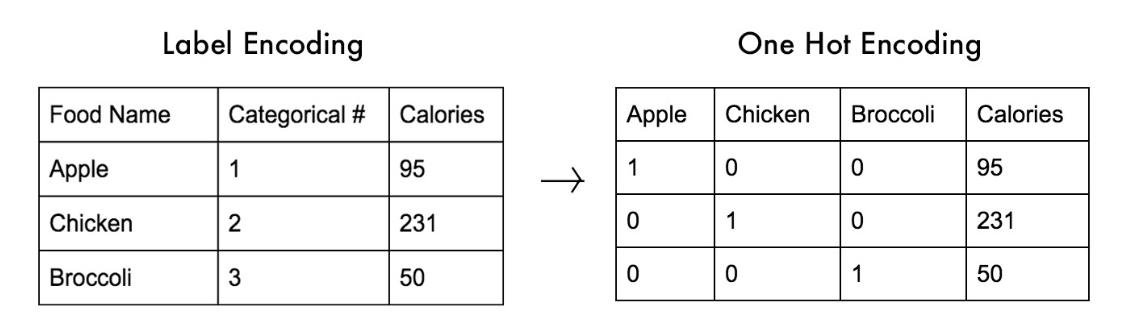
通过这些数值型的数据, 可以将这些数据进行 OneHot 编码
- 为了提高算法能力, 只是转成数值还不行, 因为数值之间是有大小的
- 举个例子, 如果红转成1, 黄转成2, 蓝转成3, 那么黄就变成红和蓝的中位数了, 这在很多算法的计算里是不合适的
%spark
import org.apache.spark.ml.feature.OneHotEncoderEstimator
val oneHotCols = cols.map(col => s"${col}_onehot")
val oneHotEncoderEstimator = new OneHotEncoderEstimator()
.setInputCols(indexCols)
.setOutputCols(oneHotCols)
val oneHotDF = oneHotEncoderEstimator.fit(indexerDF).transform(indexerDF)
oneHotDF.select(oneHotCols.head, oneHotCols:_*)
.show()
-
对于很多算法而言, 需要将所有的特征集合起来, 放入一个列中
- 需要注意的是, 在这一步骤中, 需要加入所有传入算法的特征
%spark import org.apache.spark.ml.feature.VectorAssembler val vectorAssembler = new VectorAssembler() //.setInputCols(oneHotCols :+ "TotalBsmtSF" :+ "1stFlrSF" :+ "2ndFlrSF") .setInputCols(oneHotCols) .setOutputCol("features") val vectorDF = vectorAssembler.transform(oneHotDF) vectorDF.select("features") .show()
2.8. 简要实现模型
为了实现一个机器学习算法, 一般会遵循如下步骤
- 数据分析, 查看数据的情况, 例如分布情况, 组成情况等, 从而为后面的特征处理和模型训练奠定基础
- 数据处理, 空值处理, 顺序编码, 组合特征等
- 特征提取, 例如一些文本列, 要通过一些特定的方式, 抽取出来特征
- 特征合并, 某些算法需要我们把特征合并起来
- 特征转换, 特征中有一部分是非数字形式的, 要通过一些方式转为数字形式, 例如独热或者编码
- 模型训练, 训练模型
- 交叉验证, 验证模型指标
- 新数据预测
接下来用户画像标签的实现中, 直接选择特征, 进行合并转换, 训练模型
在工作中, 如果模型不够好, 要优化模型, 要从特征的角度着手, 认真梳理和处理特征
%spark
import org.apache.spark.ml.regression.RandomForestRegressor
import org.apache.spark.sql.types.DoubleType
import spark.implicits._
val regressor = new RandomForestRegressor()
.setMaxDepth(5)
.setImpurity("variance")
.setFeaturesCol("features")
.setLabelCol("SalePrice")
.setPredictionCol("prediction")
regressor.fit(vectorDF.select('features, 'SalePrice cast DoubleType))
.transform(vectorDF)
.select('SalePrice, 'prediction)
.show()
以上是关于Zeppelin可视化数据分析的主要内容,如果未能解决你的问题,请参考以下文章
Apache Zeppelin 如何可视化来自 Hbase 的数据?