时序数据库永远的难关 — 时间线膨胀(高基数 Cardinality)问题的解决方案
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了时序数据库永远的难关 — 时间线膨胀(高基数 Cardinality)问题的解决方案相关的知识,希望对你有一定的参考价值。
简介: 本文主要讨论 influxdb 在遇到写入的数据出现高基数 Cardinality 问题时,一些可行的解决方案。
作者 | 徐建伟 (竹影)
前序
随着移动端发展走向饱和,现在整个 IT 行业都期待着“万物互联”的物联网时代。在物联网场景中,往往有许多各类不同的终端设备,布署在不同的位置,去采集各种数据,比如某一区域有 10万个 loT 设备,每个 loT 设备每 5 秒发送一次数据。那么每年会产生 6307亿 个数据点。而这些数据都是顺序产生的,并且 loT 设备产生数据的格式全部是一致的,并且没有删除和修改的需求。针对这样按时海量写入无更新场景,时序数据库应运而生。
时序数据库在假定没有数据插入和更新需求,数据结构稳定的前提下,极限追求快速写入,高压缩,快速检索数据。时序数据的 Label(tag)会建立索引,以提高查询性能,以便你可以快速找到与所有指定标签匹配的值。如果 Label(tag)值的数量过多时(高基数 Cardinality 问题),索引会出现各种各样的问题, 本文主要讨论 influxdb 在遇到写入的数据出现高基数 Cardinality 问题时,一些可行的解决方案。
高基数Cardinality问题(时间线膨胀)
时序数据库主要存储的是 metric 数据,每一条数据称为一个样本(sample),样本由以下三部分组成:
- 指标(时间线 time-series):metric name 和描述当前样本特征的 labelsets;
- 时间戳(timestamp):一个精确到毫秒的时间戳;
- 样本值(value):表示当前样本的值。
<-------------- time-series="" --------=""><-timestamp -----=""> <-value->
node_cpu{cpu=“cpu0”,mode=“idle”} @1627339366586 70
node_cpu{cpu=“cpu0”,mode=“sys”} @1627339366586 5
node_cpu{cpu=“cpu0”,mode=“user”} @1627339366586 25
通常情况下, time-series 中的 lablelsets 是有限的,可枚举的,比如上面的例子 model 可选值为 idle,sys,user。
prometheus 官方文档中对于 Label 的建议:
CAUTION: Remember that every unique combination of key-value label pairs represents a new time series, which can dramatically increase the amount of data stored. Do not use labels to store dimensions with high cardinality (many different label values), such as user IDs, email addresses, or other unbounded sets of values.
时序数据库的设计时,也是假定在时间线低基数的前提下。但是随着 metric 的广泛使用,在很多场景下无法避免出现时间线膨胀。
比如,在云原生场景下 tag 出现 pod/container ID之类,也有些 tag 出现 userId,甚至有些 tag 是 url,而这些 tag 组合时,时间线膨胀得非常厉害。
这个矛盾出现是必然的,怎么解决呢?是写入数据方调整写入数据时,控制写入的 time-series的数量,还是时序数据库去更改设计来适用这种场景?这个问题没有完美的解决方案,我们需要做出平衡。
从实际情况出发,如果时间线膨胀后,时序数据库不会出现不可用,性能也不会出现指数级别下降。也就是说时间线不膨胀时,性能优秀。时间线膨胀后,性能能达到良好或者及格就好。
那怎么让时序数据库在时间线膨胀的情况下性能还能良好呢?接下来我们通过influxdb的源码来讨论这个问题。
时间线的处理逻辑
influxdb 的 tsm 结构,主要的逻辑处理过程类似 lsm。数据上报后,会添加到 cache 和日志文件(wal)。为了加快检索速度或者压缩比例,会对上报的数据进行 compaction(数据文件合并,重新构建索引)。
索引涉及到三个方面:
- TSI(Time Series Index)检索Measurement,tag,tagval,time
- TSM(Time-Structured Merge Tree)用来检索time-series -> value
- Series Segment Index 用来检索 time-series key <–> time-series Id
具体influxdb的索引实现可以参照官方文章。
(https://github.com/influxdata/influxdb/blob/master/tsdb/index/tsi1/doc.go)
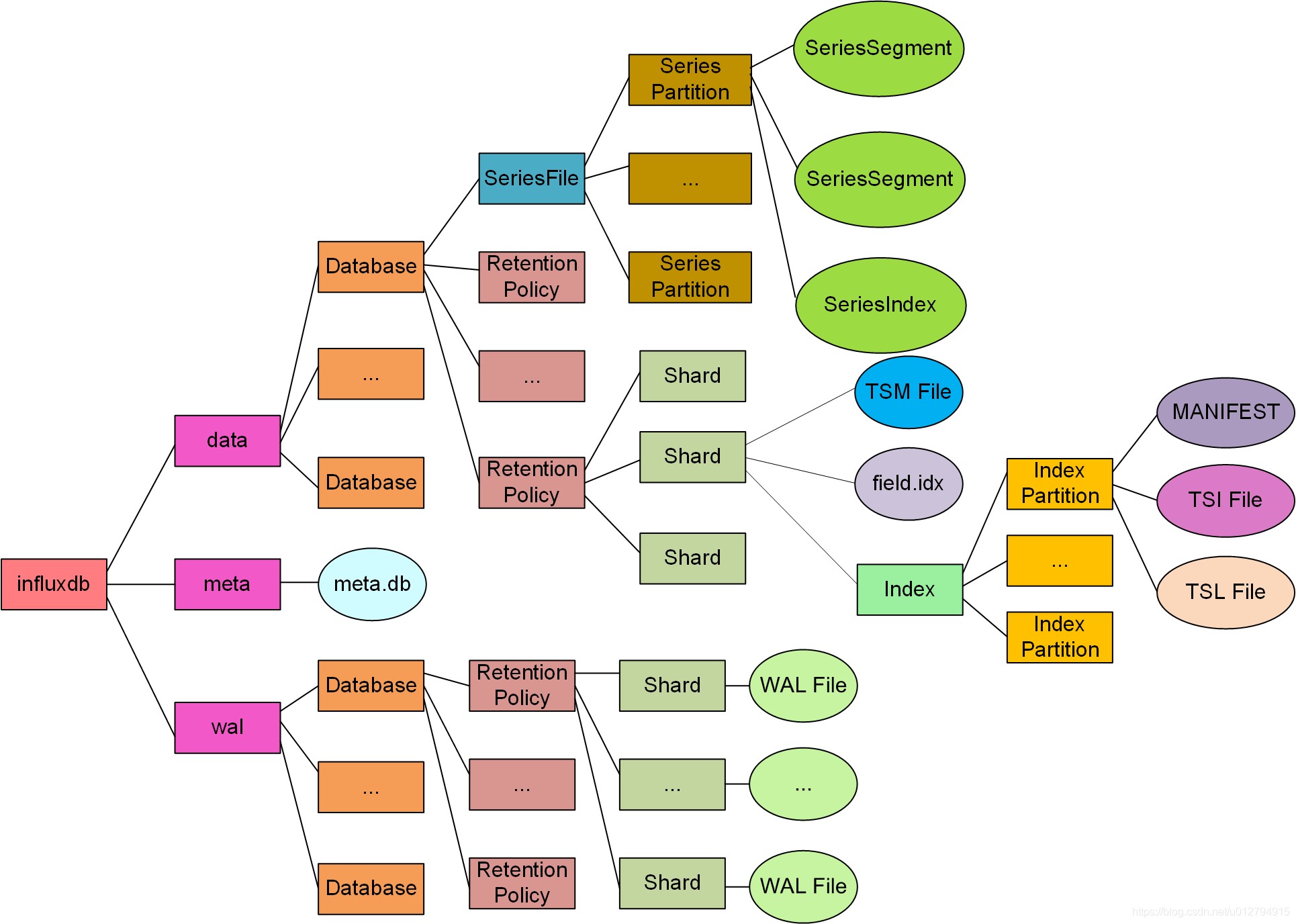
当时间线膨胀后,TSI 和 TSM 的检索性能下降并不严重,问题主要是出现在 Series Segment Index 里。
这节我们会讨论influxdb的时间线文件的正排索引(time-series key ->id, id->time-series key):
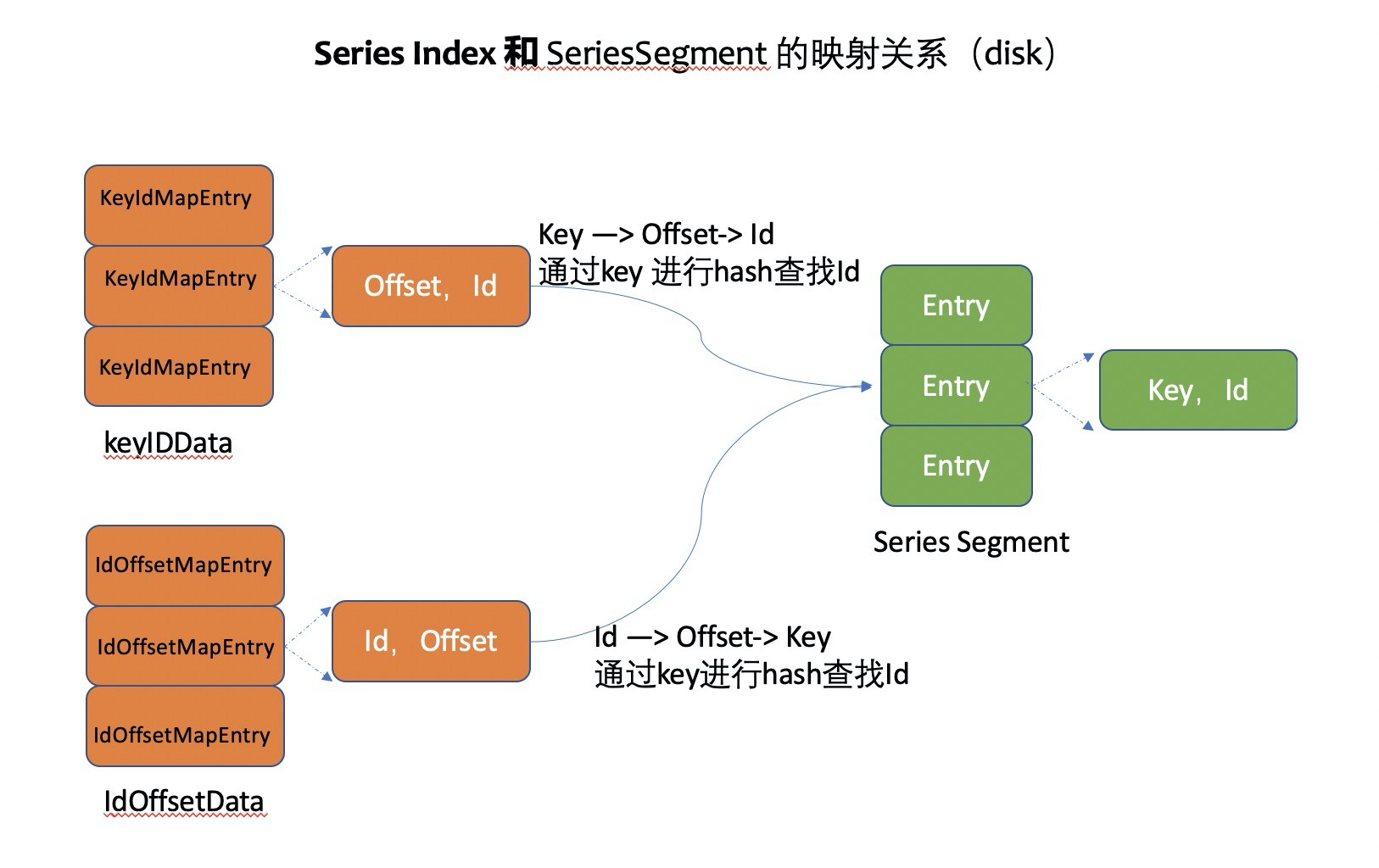
- SeriesFile 是 Database(bucket)级别的。
- SeriesIndex 主要处理 key->Id, key->id 的索引映射。
- SeriesSegment 主要存放的是 Series 的 Id 和 key。
- SeriesIndex 里面是存放 Series 的 Id 和 key 等索引。(可以理解是两个 hashmap)
- keyIDMap 通过 key 来查找对应的 Id。
- idOffsetMap 通过 Id 查到到 offset,通过这个 offset(对应 SeriesSegment 的位置)来查找 SeriesSegment 文件获取 key。
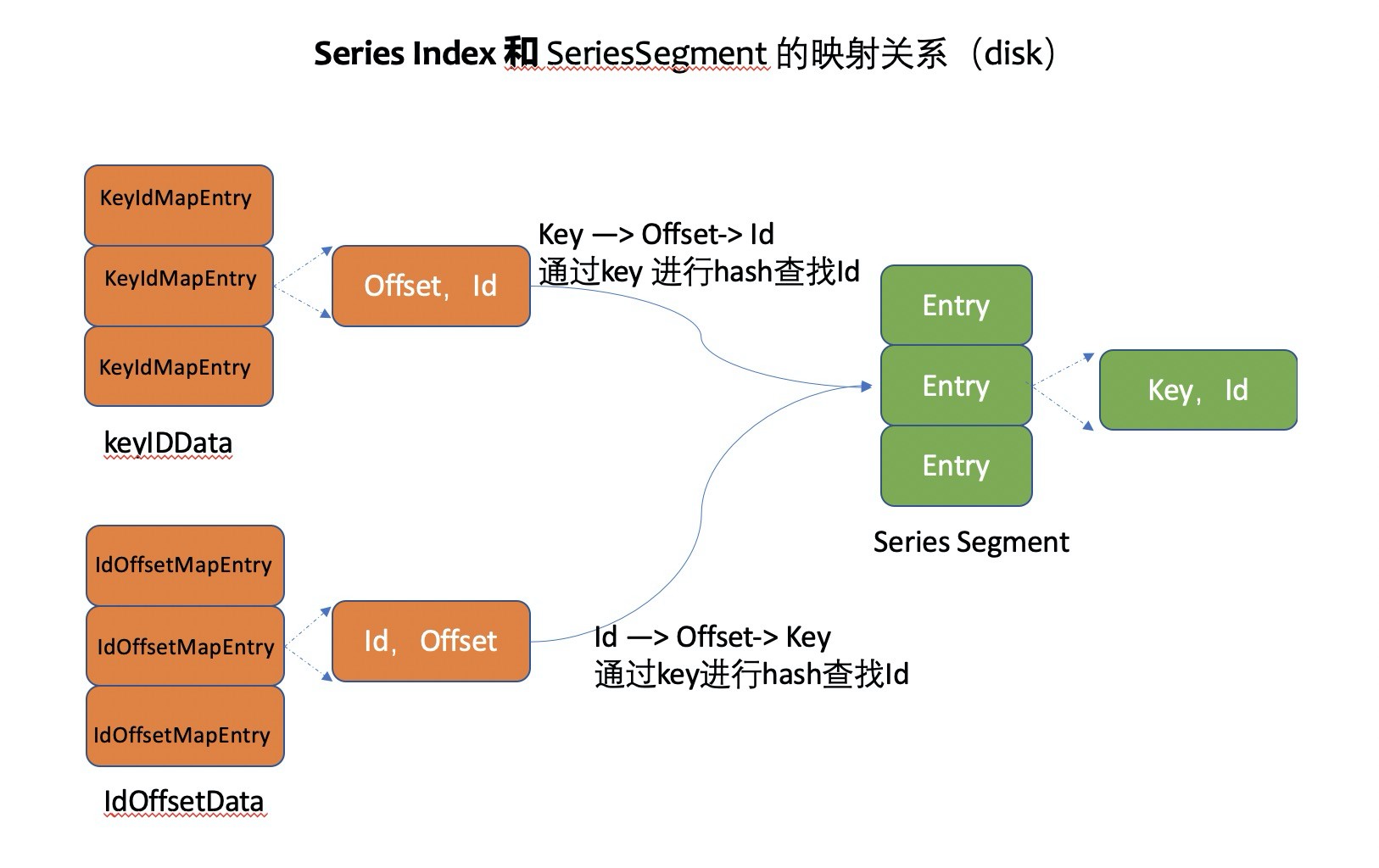
具体的代码(influxdb 2.0.7)如下:
tsdb/series_partition.go:30 // SeriesPartition represents a subset of series file data. type SeriesPartition struct { ... segments []*SeriesSegment index *SeriesIndex seq uint64 // series id sequence .... } tsdb/series_index.go:36 // SeriesIndex represents an index of key-to-id & id-to-offset mappings. type SeriesIndex struct { path string ... data []byte // mmap data keyIDData []byte // key/id mmap data idOffsetData []byte // id/offset mmap data // In-memory data since rebuild. keyIDMap *rhh.HashMap idOffsetMap map[uint64]int64 tombstones map[uint64]struct{} }
对 series key 进行检索时,会先在内存 map 中查找,然后在磁盘的 map 上查找,具体的实现代码如下:
tsdb/series_index.go:185 func (idx *SeriesIndex) FindIDBySeriesKey(segments []*SeriesSegment, key []byte) uint64 { // 内存map查找 if v := idx.keyIDMap.Get(key); v != nil { if id, _ := v.(uint64); id != 0 && !idx.IsDeleted(id) { return id } } if len(idx.data) == 0 { return 0 } hash := rhh.HashKey(key) for d, pos := int64(0), hash&idx.mask; ; d, pos = d+1, (pos+1)&idx.mask { // 磁盘map查找offset elem := idx.keyIDData[(pos * SeriesIndexElemSize):] elemOffset := int64(binary.BigEndian.Uint64(elem[:8])) if elemOffset == 0 { return 0 } // 通过offset获取对于的id elemKey := ReadSeriesKeyFromSegments(segments, elemOffset+SeriesEntryHeaderSize) elemHash := rhh.HashKey(elemKey) if d > rhh.Dist(elemHash, pos, idx.capacity) { return 0 } else if elemHash == hash && bytes.Equal(elemKey, key) { id := binary.BigEndian.Uint64(elem[8:]) if idx.IsDeleted(id) { return 0 } return id } } }
这里补充一个知识点,将内存 hashmap 转成磁盘 hashmap 的实现。我们都知道 hashmap 的存储是数组,influfxdb 中的实现是通过 mmap 方式映射磁盘空间(见 SeriesIndex 的 keyIDData),然后通过 hash 访问数组地址,采用的 Robin Hood Hashing,符合内存局部性原理(查找逻辑的代码如上 series_index.go 中)。将 Robin Hood Hashtable 纯手动移植磁盘 hashtable, 开发人员还是花了不少心思。
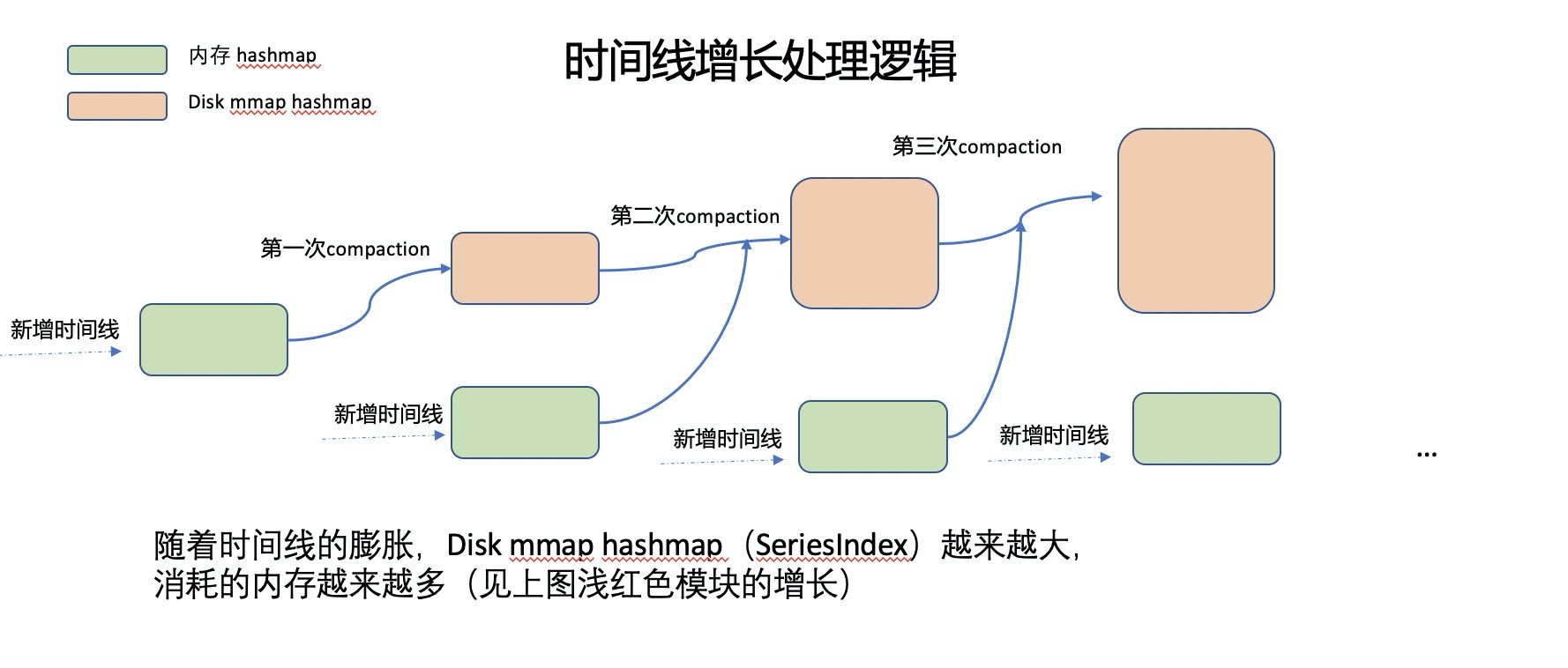
那内存 map 和磁盘 map 是如何生成的,为什么需要两个 map?
influxdb 的做法是将新增的 series key 先放到内存 hashmap 里面,当内存 hashmap 增长大于阈值时,将内存 hashmap 和磁盘 hashmap 进行 merge(遍历所有 SeriesSegment,过滤已经删除的 series key)生成一个新的磁盘 hashmap,这个过程叫做 compaction。compation 结束后内存 hashmap 被清空,然后继续存放新增的 series key。
tsdb/series_partition.go:200 // Check if we've crossed the compaction threshold. if p.compactionsEnabled() && !p.compacting && p.CompactThreshold != 0 && p.index.InMemCount() >= uint64(p.CompactThreshold) && p.compactionLimiter.TryTake() { p.compacting = true log, logEnd := logger.NewOperation(context.TODO(), p.Logger, "Series partition compaction", "series_partition_compaction", zap.String("path", p.path)) p.wg.Add(1) go func() { defer p.wg.Done() defer p.compactionLimiter.Release() compactor := NewSeriesPartitionCompactor() compactor.cancel = p.closing if err := compactor.Compact(p); err != nil { log.Error("series partition compaction failed", zap.Error(err)) } logEnd() // Clear compaction flag. p.mu.Lock() p.compacting = false p.mu.Unlock() }() }
tsdb/series_partition.go:569 func (c *SeriesPartitionCompactor) compactIndexTo(index *SeriesIndex, seriesN uint64, segments []*SeriesSegment, path string) error { hdr := NewSeriesIndexHeader() hdr.Count = seriesN hdr.Capacity = pow2((int64(hdr.Count) * 100) / SeriesIndexLoadFactor) // Allocate space for maps. keyIDMap := make([]byte, (hdr.Capacity * SeriesIndexElemSize)) idOffsetMap := make([]byte, (hdr.Capacity * SeriesIndexElemSize)) // Reindex all partitions. var entryN int for _, segment := range segments { errDone := errors.New("done") if err := segment.ForEachEntry(func(flag uint8, id uint64, offset int64, key []byte) error { ... // Save max series identifier processed. hdr.MaxSeriesID, hdr.MaxOffset = id, offset // Ignore entry if tombstoned. if index.IsDeleted(id) { return nil } // Insert into maps. c.insertIDOffsetMap(idOffsetMap, hdr.Capacity, id, offset) return c.insertKeyIDMap(keyIDMap, hdr.Capacity, segments, key, offset, id) }); err == errDone { break } else if err != nil { return err } }
这样设计有两个缺陷:
- 做 compaction 时,当 io 访问 SeriesSegments 文件, 内存加载所有的 series key,会构建一个新的 hashtable,然后将这个 hashtable mmap 存储到磁盘,当 series key 超过几千万或者更多时,会出现内存不够,oom 问题。
- 做 compaction 时, 对于已经删除的 series key(tombstone 标记)做了过滤,不生成 series index,但是 SeriesSegment 中已经删除 series key 只有做了 tombstone 标记,不会做物理删除,这样会导致 SeriesSegment 一直膨胀,在实际生产环境一个 partition 下的所有 segmeng 文件超过几十 G,做 compaction 时,会产生大量 io 访问。
可行的解决方案
1、增加partition或者database
influxdb 的正排索引是 database 级别的,有两个方式可以减少 compaction 时的内存,一个是增加 partition 数量或者将多个 Measurement 划到不同的 database 里面。
但这样做的问题是,已经存在数据的 influxdb 不好调整两个数据。
2、修改时间线存储策略
我们知道 hash 索引是 O1 的查询,效率非常高,但是对于增长性的数据,存在扩容问题。那我们做个折中的选择。当 partition 大于某个阈值时,将 hash 索引变成 b+tree 索引。b+tree 对于数据膨胀性能下降有限,更适合高基数问题,而且不再需要全局的 compaction。
3、将series key的正排索引下沉到shard级别
influxdb 里面每个 shard 都是有时间区间的,某个时间区间内的时间线数据并不大。比如 database 里面保存的是 180天 的 series key,而 shard 一般只有一天甚至 1 个小时的跨度,两者存放的 series key 存在 1~ 2 个数量级的差距。另外将 series key 正排索引下沉到 shard 级别对删除操作更友好,当 shard 过期删除时,会将当前 shard 的所有 series key 和其他 shard 做 diff,当 series key 不存在时再去删除 series key。
4、根据Measurement修改时间线存储策略
在实际生产环境中,时间线膨胀和 Measurement 有很大关系,一般是少数的 Measurement 存在时间线膨胀问题,但是绝大部分的 Measurement 不存在时间线爆炸的问题。
我们可以对做 series key 的正排索引的 compaction 时,可以添加 Measurement 时间线统计,如果某个 Measurement 的时间线膨胀时,可以将这个 Measurement 的所有 series key 切换到 B+ tree。而不膨胀的 series key 继续保留走 hash 索引。这样方案性能比第二个方案更好,开发成本会更高一些。
目前高基数问题主要体现在 series key 正排索引。个人觉得短期先做第二个方案过度到第四个方案的方式。这样可以比较好的解决时间线增长的问题,性能下降不多,成本不高。第三个方案改动比较大,设计更合理,可以作为一个长期修复方案。
总结
本文主要通过 influxdb 来讲解时序数据库的高基数 Cardinality 问题,以及可行的方案。metric 的维度爆炸导致数据线膨胀问题,很多同学都认为这是对时序数据库的误用或者是滥用。但是信息数据爆炸的今天,让数据维度收敛,不发散成本非常高,甚至远高于数据存储成本。
个人觉得需要对这个问题进行分而治之的方式,提升时序数据库对维度爆炸的容忍度。换句话说,出现时间线膨胀后,时序数据库不会出现崩溃情况,对时间线未膨胀的 metric 继续高效运行,而出现时间线膨胀的 metic 可以出现性能下降,单不会线性下降。提升对时间线膨胀的容忍度,控制时间线膨胀的爆炸半径,将会成为时序数据库的核心能力。
原文链接
本文为阿里云原创内容,未经允许不得转载。
以上是关于时序数据库永远的难关 — 时间线膨胀(高基数 Cardinality)问题的解决方案的主要内容,如果未能解决你的问题,请参考以下文章
onCreateOptionsMenu 永远不会被调用(工具栏膨胀)