利用Python爬虫获取招聘网站职位信息
Posted 程序员的小傲娇
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了利用Python爬虫获取招聘网站职位信息相关的知识,希望对你有一定的参考价值。
当你学会使用Python爬虫之后就会发现想要得到某些数据再也不用自己费力的去寻找,今天小千就给大家介绍一个很实用的爬虫案例,获取Boss直聘上面的招聘信息,同学们一起来学习一下了。
Boss直聘爬虫案例
这次我们以北京地区的销售岗位为案例,打开Boss直聘搜索【销售】,但是很遗憾boss直聘的反爬措施不能直接使用requests库获取信息,所以采用webdriver自动化方式获取网页源代码。
webdriver的使用需要:pip3 install selenium、配置chrome浏览器的chrome driver。
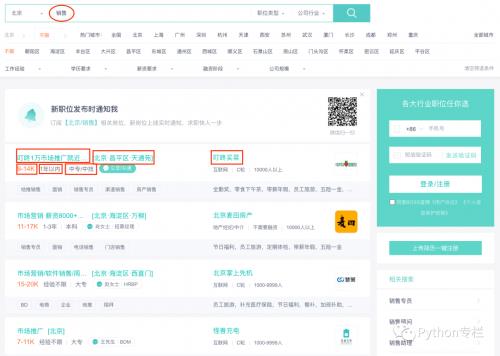
点击了多页之后,发现地址栏的地址变化如下:

所以我们就发现了地址的规律变化,因此代码如下:

此时执行代码,发现htmls_list中有好多的数据。这下也就放心了,说明我们获取到了网页的数据。有了数据我们就开始遍历htmls_list,因为htmls_list存放着多页的数据,我们要一页一页的获取并提取里面的职位、薪资等信息。提取的过程我们使用的是BeautifulSoup,具体的使用说明这里不在赘述。
使用BeautifulSoup提取的数据我们都存放在job_list=[]这个列表中。页面分析如下:
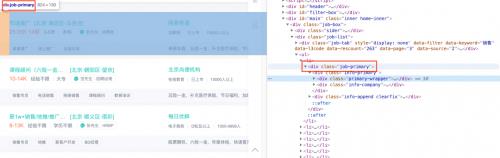
以此类推,我们都可以找到对应的标签。

以上就是Python获取boss直聘上面的岗位信息过程的介绍了,最后欢迎对Python开发感兴趣的小伙伴关注小千,后期分享跟多Python技术知识!
以上是关于利用Python爬虫获取招聘网站职位信息的主要内容,如果未能解决你的问题,请参考以下文章