一、介绍
本例子用Selenium +phantomjs爬取智能电视网站(http://www.tvhome.com/news/)的资讯信息,输入给定关键字抓取图片信息。
给定关键字:数字;融合;电视
二、网站信息
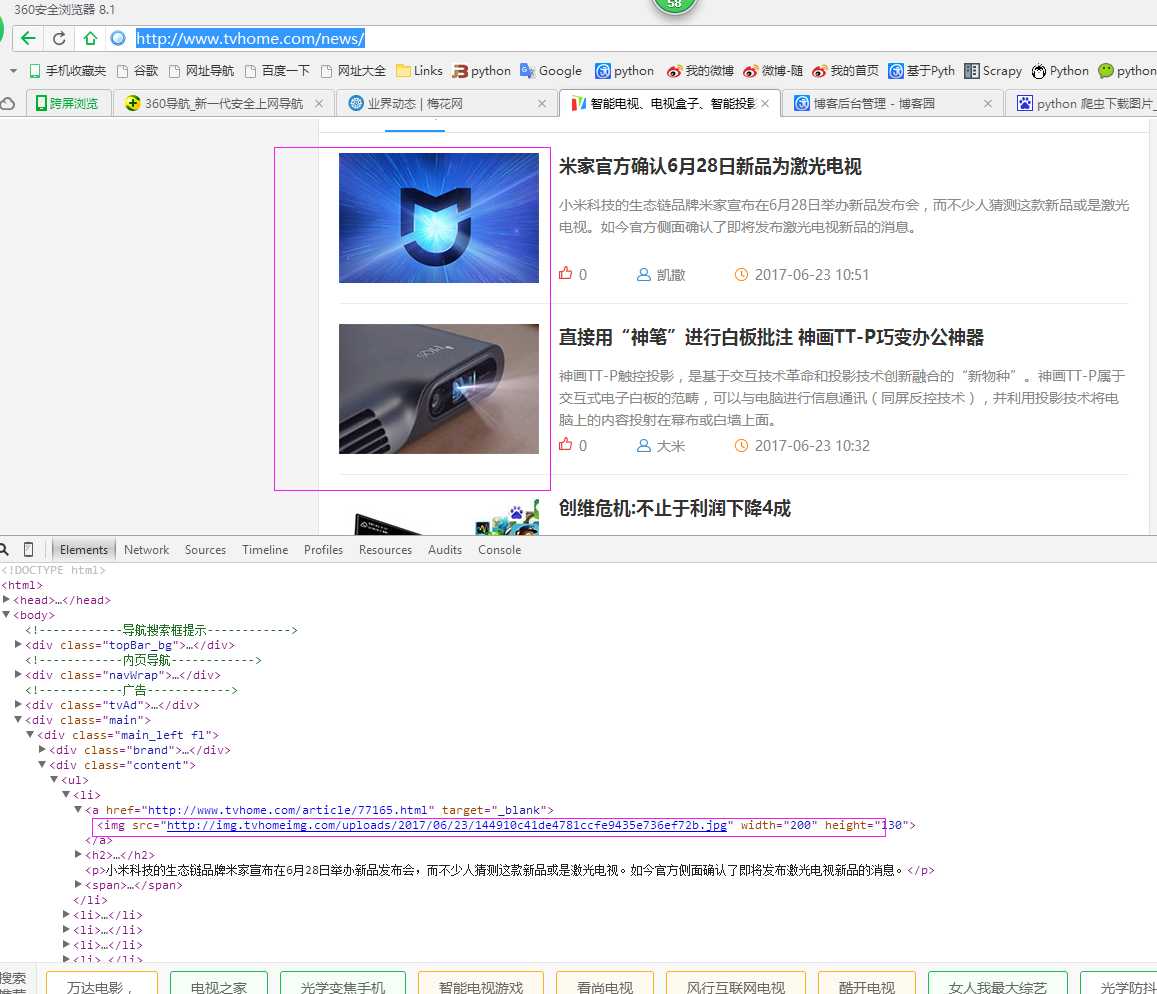
三、数据抓取
针对上面的网站信息,来进行抓取
1、首先抓取信息列表
抓取代码:Elements = doc(‘div[class="main_left fl"]‘).find(‘div[class="content"]‘).find(‘ul‘).find(‘li‘)
2、抓取图片
抓取代码:imgurl = element(‘a‘).find(‘img‘).attr(‘src‘);
self.down_picture(imgurl)
四、完整代码
def down_picture(self, imgurl): """ 下载图片到本地 :param imgurl: 图片url """ # http://img.tvhomeimg.com/uploads/2017/06/23/144910c41de4781ccfe9435e736ef72b.jpg if len(imgurl)>0: fileName = ‘‘ if imgurl.rfind(‘/‘)>0: fileName = imgurl[imgurl.rfind(‘/‘) + 1:] u = urllib.urlopen(imgurl) data = u.read() strpath = os.path.dirname(os.getcwd())+‘\\picture‘ with open(os.path.join(strpath, fileName), ‘wb‘) as f: f.write(data)