大数据Flink面试考题___Flink高频考点,万字超全整理(建议收藏)
Posted 大数据Manor
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据Flink面试考题___Flink高频考点,万字超全整理(建议收藏)相关的知识,希望对你有一定的参考价值。
引言

大家好,我是ChinaManor,直译过来就是中国码农的意思,我希望自己能成为国家复兴道路的铺路人,大数据领域的耕耘者,平凡但不甘于平庸的人。
Flink知识回顾考卷如下:
选择题
1.下面哪个不是 Dataset的转换算子()
A. readTextFile B reduce distinct D rebalance
A
2.关于状态管理分类,下面哪个是错误的(
A keyed state B operate state
C broadcast state D transform state
D
3.检查点的状态后端( state backend),下面哪个是错误的()
A Mongodb State Backend B MemoryState Backend
A
4.Fink中的时间以下说法正确的是()
A如果以 EventTime为基准来定义时间窗口将形成 ventTimeWindow,要求消息本身就应该
携帝 EventTime
8如果以 ngesingtTime为基准来定义时间窗口将形成 Ingesting Timewindow以 source的
systemTime为准
c如果以 ProcessingTime基准来定义时间窗口将形成 ProcessingTime window,以 opera
的
D以上说法都正确
D
5.fink的适合场景有哪些不适合()
A实时数据 pipeline数据抽取
B实时数据仓库和实时ETL
C事件驱动型场景,如告警、监控
D大批量的数据进行离线(t+1)报表计算
D
多选题
1 fik流处理特性()
A.支持带有事件时间的窗口( Window)操作
B.支持有状态计算的 Exactly-once语义
C.支持基于轻量级分布式快照( Snapshot)实现的容错
D.支持程序自动优化:避免特定情况下shue、排序等昂贵操作,中间结果有必要进行缓存
ABCD
2.以下哪些是fink提供状态存储(
A. lOState Backend
B. Memory Backend
tate Backend
D. Rocks DBState Backend
BCD
3.fink核心组成部分提供了面向哪两种接口()
A.批处理接口
B.流处理接口
C.表处理接口
D.复杂事件处理接口
AB
4. flink on yarn有哪两种提交模式()
A. Yarm-alone
B. yarn-session
C. Yarn-cluste
D. standalone
BC
5.fink实现的重启策略包括()
A故障率重启策略( Failure Rate Restart Strategy)
B.固定延迟重启策略( Fixed Delay Restart strate
C. Fallback重启策( Fallback Restart strategy)
D.没有重启策略
ABCD
判断题:
6 task slot是 taskManager内资源分配的最小载体,代表了可根据资源需求自动调整大小
的资源子集,()
F
7fink的rich函数中的open方法是每来一条数据执行一次。()
F
8.fink的流处理操作底层是批处理,是特殊批处理操作。()
F
9.fink的高可用模式,主要是防止 JobManager出现单点故障,确保集群的高可用。()
T
10 Hlink SoL底层 Runtime本身是一个流与批的统一的引擘, HlinkSQL可以做到AP层的流与
批统一。()
T
下面为模拟面试,假如面试官考你Flink相关,你该如何回答呢?

1.简单介绍一下 Flink
Flink 核心是一个流式的数据流执行引擎,其针对数据流的分布式计算提供了数据分布、数 据通信以及容错机制等功能。 基于流执行引擎,Flink 提供了诸多更高抽象层的 API 以便用户编 写分布式任务:DataSet API, 对静态数据进行批处理操作,将静态数据抽象成分布式的数据集, 用户可以方便地使用 Flink 提供的各种操作符对分布式数据集进行处理,支持 Java、Scala 和 Python。DataStream API,对数据流进行流处理操作,将流式的数据抽象成分布式的数据流,用 户可以方便地对分布式数据流进行各种操作,支持 Java 和 Scala。Table API,对结构化数据进 行查询操作,将结构化数据抽象成关系表,并通过类 SQL 的 DSL 对关系表进行各种查询操作,支 持 Java 和 Scala。此外,Flink 还针对特定的应用领域提供了领域库,例如:Flink ML,Flink 的机器学习库,提供了机器学习 Pipelines API 并实现了多种机器学习算法。Gelly,Flink 的图 计算库,提供了图计算的相关 API 及多种图计算算法实现。
2.Flink 相比 Spark Streaming 有什么区别?
架构模型上:Spark Streaming 的 task 运行依赖 driver 和 executor 和 worker,当然 driver 和 excutor 还依赖于集群管理器 Standalone 或者 yarn 等。而 Flink 运行时主要是 JobManager、 TaskManage 和 TaskSlot。另外一个最核心的区别是:Spark Streaming 是微批处理,运行的时 候需要指定批处理的时间,每次运行 job 时处理一个批次的数据;Flink 是基于事件驱动的, 事件可以理解为消息。事件驱动的应用程序是一种状态应用程序,它会从一个或者多个流中注入 事件,通过触发计算更新状态,或外部动作对注入的事件作出反应。
任务调度上:Spark Streaming 的调度分为构建 DGA 图,划分 stage,生成 taskset,调度 task 等步骤,而 Flink 首先会生成 StreamGraph,接着生成 JobGraph,然后将 jobGraph 提交 给 Jobmanager 由它完成 jobGraph 到 ExecutionGraph 的转变,最后由 jobManager 调度执行。
时间机制上:flink 支持三种时间机制事件时间,注入时间,处理时间,同时支持 watermark 机制处理滞后数据。Spark Streaming 只支持处理时间,Structured streaming 则支持了事件时 间和 watermark 机制。
容错机制上:二者保证 exactly-once 的方式不同。spark streaming 通过保存 offset 和事 务的方式;Flink 则使用两阶段提交协议来解决这个问题。
3 Flink 中的分区策略有哪几种?
分区策略是用来决定数据如何发送至下游。目前 Flink 支持了8中分区策略的实现。
1)GlobalPartitioner 数据会被分发到下游算子的第一个实例中进行处理。
2)ShufflePartitioner 数据会被随机分发到下游算子的每一个实例中进行处理。
3)RebalancePartitioner 数据会被循环发送到下游的每一个实例中进行处理。
4)RescalePartitioner 这种分区器会根据上下游算子的并行度,循环的方式输出到下游算子的每个实例。这里有点难以理解,假设上游并行度为2,编号为A和B。下游并行度为4,编号为1,2,3,4。那么A则把数据循环发送给1和2,B则把数据循环发送给3和4。假设上游并行度为4,编号为A,B,C,D。下游并行度为2,编号为1,2。那么A和B则把数据发送给1,C和D则把数据发送给2。
5)BroadcastPartitioner 广播分区会将上游数据输出到下游算子的每个实例中。适合于大数据集和小数据集做Jion的场景。
6)ForwardPartitioner ForwardPartitioner 用于将记录输出到下游本地的算子实例。它要求上下游算子并行度一样。简单的说,ForwardPartitioner用来做数据的控制台打印。
7)KeyGroupStreamPartitioner Hash分区器。会将数据按 Key 的 Hash 值输出到下游算子实例中。
8)CustomPartitionerWrapper 用户自定义分区器。需要用户自己实现Partitioner接口,来定义自己的分区逻辑
4 Flink 的并行度有了解吗?Flink 中设置并行度需要注意什么?

Flink 程序由多个任务(Source、Transformation、Sink)组成。任务被分成多个并行实例 来执行,每个并行实例处理任务的输入数据的子集。任务的并行实例的数量称之为并行度。
Flink 中人物的并行度可以从多个不同层面设置:
操作算子层面(Operator Level)、
执行环境层面 (Execution Environment Level)、
客户端层面(Client Level)、
系统层面(System Level)。
Flink 可以设置好几个level的parallelism,
其中包括
Operator Level、
Execution Environment Level、
Client Level、
System Level
在 flink-conf.yaml 中通过 parallelism.default 配置项给所有 execution environments 指定系统级的默认 parallelism;在 ExecutionEnvironment 里头可以 通过 setParallelism 来给 operators、data sources、data sinks 设置默认的 parallelism;如 果 operators 、 data sources 、 data sinks 自 己 有 设 置 parallelism 则 会 覆 盖 ExecutionEnvironment 设置的 parallelism。
需要注意的优先级:算子层面>环境层面>客户端层面>系统层面。
5 Flink 支持哪几种重启策略?分别如何配置? 重启策略种类:
固定延迟重启策略(Fixed Delay Restart Strategy)
故障率重启策略(Failure Rate Restart Strategy)
无重启策略(No Restart Strategy)
Fallback 重启策略(Fallback Restart Strategy)
6 Flink 的分布式缓存有什么作用?如何使用?
Flink 提供了一个分布式缓存,类似于 hadoop,可以使用户在并行函数中很方便的读取本地 文件,并把它放在 taskmanager 节点中,防止 task 重复拉取。
此缓存的工作机制如下:程序注册一个文件或者目录(本地或者远程文件系统,例如 hdfs 或 者 s3),通过 ExecutionEnvironment 注册缓存文件并为它起一个名称。 当程序执行,Flink 自动将文件或者目录复制到所有 taskmanager 节点的本地文件系统,仅 会执行一次。用户可以通过这个指定的名称查找文件或者目录,然后从 taskmanager 节点的本地 文件系统访问它。
7 Flink 中的广播变量,使用广播变量需要注意什么事项?
在 Flink 中,同一个算子可能存在若干个不同的并行实例,计算过程可能不在同一个 Slot 中进行,不同算子之间更是如此,因此不同算子的计算数据之间不能像 Java 数组之间一样互相 访问,而广播变量 Broadcast 便是解决这种情况的。我们可以把广播变量理解为是一个公共的共 享变量,我们可以把一个 dataset 数据集广播出去,然后不同的 task 在节点上都能够获取到, 这个数据在每个节点上只会存在一份。
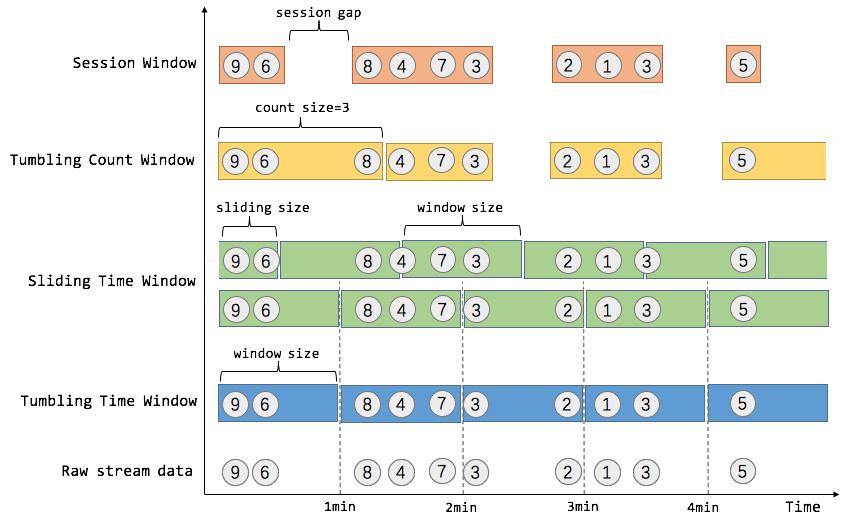
8.Flink 中对窗口的支持包括哪几种?说说他们的使用场景
- Tumbling Time Window 假如我们需要统计每一分钟中用户购买的商品的总数,需要将用户的行为事件按每一分钟进 行切分,这种切分被成为翻滚时间窗口(Tumbling Time Window)。翻滚窗口能将数据流切分成 不重叠的窗口,每一个事件只能属于一个窗口。
- Sliding Time Window 我们可以每 30 秒计算一次最近一分钟用户购买的商品总数。这种窗口我们称为滑动时间窗 口(Sliding Time Window)。在滑窗中,一个元素可以对应多个窗口。
- Tumbling Count Window 当我们想要每 100 个用户购买行为事件统计购买总数,那么每当窗口中填满 100 个元素了, 就会对窗口进行计算,这种窗口我们称之为翻滚计数窗口(Tumbling Count Window),上图所 示窗口大小为 3 个。
- Session Window 在这种用户交互事件流中,我们首先想到的是将事件聚合到会话窗口中(一段用户持续活跃 的周期),由非活跃的间隙分隔开。如上图所示,就是需要计算每个用户在活跃期间总共购买的 商品数量,如果用户 30 秒没有活动则视为会话断开(假设 raw data stream 是单个用户的购买 行为流)。一般而言,window 是在无限的流上定义了一个有限的元素集合。这个集合可以是基 于时间的,元素个数的,时间和个数结合的,会话间隙的,或者是自定义的。Flink 的 DataStream API 提供了简洁的算子来满足常用的窗口操作,同时提供了通用的窗口机制来允许用户自己定义 窗口分配逻辑。
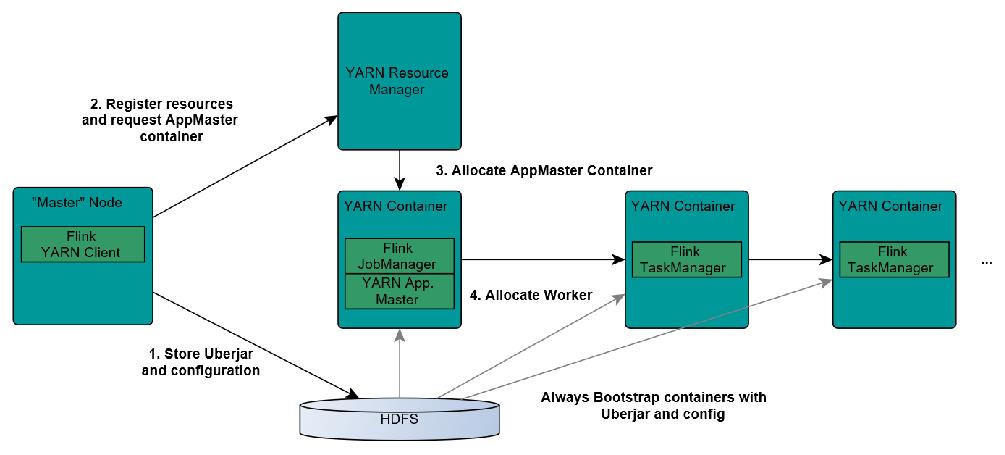
9 请简单描述一下Flink On Yarn模式
1.Client上传jar包和配置文件到HDFS集群上
2.Client向Yarn ResourceManager提交任务并申请资源
3.ResourceManager分配Container资源并启动ApplicationMaster,然后AppMaster加载Flink的Jar包和配置构建环境,启动JobManager
JobManager和ApplicationMaster运行在同一个container上。
一旦他们被成功启动,AppMaster就知道JobManager的地址(AM它自己所在的机器)。
它就会为TaskManager生成一个新的Flink配置文件(他们就可以连接到JobManager)。
这个配置文件也被上传到HDFS上。
此外,AppMaster容器也提供了Flink的web服务接口。
YARN所分配的所有端口都是临时端口,这允许用户并行执行多个Flink
4.ApplicationMaster向ResourceManager申请工作资源,NodeManager加载Flink的Jar包和配置构建环境并启动TaskManager
5.TaskManager启动后向JobManager发送心跳包,并等待JobManager向其分配任务
10. Flink 中的时间种类有哪些?各自介绍一下?

Flink 中的时间与现实世界中的时间是不一致的,在 flink 中被划分为事件时间,摄入时间, 处理时间三种。
如果以 EventTime 为基准来定义时间窗口将形成 EventTimeWindow,要求消息本身 就 应 该 携 带 EventTime
如 果 以 IngesingtTime 为 基 准 来 定 义 时 间 窗 口 将 形 成 IngestingTimeWindow,以 source 的 systemTime 为准。
如果以 ProcessingTime 基准来定义时间窗口将形成 ProcessingTimeWindow,以 operator 的 systemTime 为准。
面到这里,面试官已经很满意你对Flink的掌握,那么更近一步让面试官折服:***
11.WaterMark 是什么?是用来解决什么问题?如何生成水 印?水印的原理是什么?
Watermark 是 Apache Flink 为了处理 EventTime 窗口计算提出的一种机制,本质上也是一种 时间戳。watermark 是用于处理乱序事件的,处理乱序事件通常用 watermark 机制结合 window 来实现。
12 Flink 的容错机制
Flink 基于分布式快照与可部分重发的数据源实现了容错。用户可自定义对整个 Job 进行快 照的时间间隔,当任务失败时,Flink 会将整个 Job 恢复到最近一次快照,并从数据源重发快照 之后的数据。

13 Flink 在使用 Window 时出现数据倾斜,你有什么解决办法?
注意:这里 window 产生的数据倾斜指的是不同的窗口内积攒的数据量不同,主要是由源头 数据的产生速度导致的差异。核心思路:1.重新设计 key 2.在窗口计算前做预聚合
14 Flink 任务,delay 极高,请问你有什么调优策略?
flink没学过调优,被问到了,我们总不能说俺不知道,洒家不会之类的吧٩(๑❛ᴗ❛๑)۶下面展示一种回答

首先要确定问题产生的原因,找到最耗时的点,确定性能瓶颈点。比如任务频繁反压,找到 反压点。主要通过:资源调优、作业参数调优。资源调优即是对作业中的 Operator 的并发数 (parallelism)、CPU(core)、堆内存(heap_memory)等参数进行调优。作业参数调优包括:并行度的设置,State 的设置,checkpoint 的设置。
15 Flink 的内存管理是如何做的
Flink 并不是将大量对象存在堆上,而是将对象都序列化到一个预分配的内存块 上。此外,Flink 大量的使用了堆外内存。如果需要处理的数据超出了内存限制, 则会将部分数据存储到硬盘上。Flink 为了直接操作二进制数据实现了自己的序 列化框架。
16 Flink 是如何支持批流一体的
这道题问的比较开阔,如果知道 Flink 底层原理,可以详细说说,如果不是很了 解,就直接简单一句话:Flink 的开发者认为批处理是流处理的一种特殊情况。 批处理是有限的流处理。Flink 使用一个引擎支持了 DataSet API 和 DataStream API。
17 Flink 中的状态存储
Flink 在做计算的过程中经常需要存储中间状态,来避免数据丢失和状态恢复。 选择的状态存储策略不同,会影响状态持久化如何和 checkpoint 交互。Flink 提 供了三种状态存储方式:MemoryStateBackend、FsStateBackend、 RocksDBStateBackend。
18. Flink 是如何保证 Exactly-once 语义的
Flink 通过实现两阶段提交和状态保存来实现端到端的一致性语义。分为以下几 个步骤: 开始事务(beginTransaction)创建一个临时文件夹,来写把数据写入到这个文件 夹里面 预提交(preCommit)将内存中缓存的数据写入文件并关闭 正式提交(commit)将之前写完的临时文件放入目标目录下。这代表着最终的 数据会有一些延迟 丢弃(abort)丢弃临时文件 若失败发生在预提交成功后,正式提交前。可以根据状态来提交预提交的数据, 也可删除预提交的数据。
19. Flink 是如何处理反压的

Flink 内部是基于 producer-consumer 模型来进行消息传递的,Flink 的反压设计 也是基于这个模型。Flink 使用了高效有界的分布式阻塞队列,就像 Java 通用 的阻塞队列(BlockingQueue)一样。下游消费者消费变慢,上游就会受到阻塞。
虽迟但到,面试总不能少了代码题:
使用JAVA或 Scala语言编程实现fink的 Word Count单词统计。
非常经典的wordcount题,类似的用scala,spark,MapReduce手写wc你能写出来吗?
新建文件为 words. txt,文件路径在/ export/ server/data下面,内容如下
Spark Flink flume hadoop
Flink spark flume hadoop
以下使用Flink 计算引擎实现流式数据处理:从Socket接收数据,实时进行词频统计WordCount
Java版:
// 1.准备环境-env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2.准备数据-source
// DataStreamSource<String> inputDataStream = env.socketTextStream("node1.itcast.cn", 9999);
DataStreamSource<String> inputDataStream = env.readTextFile("D:\\\\0615\\\\bigdata-flink\\\\datas\\\\wordcount.data");
// 3.处理数据-transformation
// TODO: 流计算词频统计WordCount与处理思路基本一致
SingleOutputStreamOperator<Tuple2<String, Integer>> resultDataStream = inputDataStream
// 分割单词
.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String line, Collector<String> out) throws Exception {
for (String word : line.trim().split("\\\\s+")) {
out.collect(word);
}
}
})
// 转换二元组
.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String word) throws Exception {
return new Tuple2<>(word, 1);
}
})
// 分组聚合
.keyBy(0).sum(1);
// 4.输出结果-sink
resultDataStream.print();
// 5.触发执行-execute
env.execute(_02StreamWordCount.class.getSimpleName());
思考一下Scala版,Python版该怎么写??
如何从Kafka中消费数据并过滤出状态为success的数据再写入到Kafka
{“user_id”: “1”, “page_id”:“1”, “status”: “success”}
{“user_id”: “1”, “page_id”:“1”, “status”: “success”}
{“user_id”: “1”, “page_id”:“1”, “status”: “success”}
{“user_id”: “1”, “page_id”:“1”, “status”: “success”}
{“user_id”: “1”, “page_id”:“1”, “status”: “fail”}
官方文档:
https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/table/connectors/kafka.html
代码实现:
//1.准备环境 流执行环境和流表
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
//2.执行SQL,创建 input_kafka 表
TableResult inputTable = tEnv.executeSql(
"CREATE TABLE input_kafka (\\n" +
" `user_id` BIGINT,\\n" +
" `page_id` BIGINT,\\n" +
" `status` STRING\\n" +
") WITH (\\n" +
" 'connector' = 'kafka',\\n" +
" 'topic' = 'input_kafka',\\n" +
" 'properties.bootstrap.servers' = 'node1:9092',\\n" +
" 'properties.group.id' = 'testGroup',\\n" +
" 'scan.startup.mode' = 'latest-offset',\\n" +
" 'format' = 'json'\\n" +
")"
);
// 创建 output_kafka
TableResult outputTable = tEnv.executeSql(
"CREATE TABLE output_kafka (\\n" +
" `user_id` BIGINT,\\n" +
" `page_id` BIGINT,\\n" +
" `status` STRING\\n" +
") WITH (\\n" +
" 'connector' = 'kafka',\\n" +
" 'topic' = 'output_kafka',\\n" +
" 'properties.bootstrap.servers' = 'node1:9092',\\n" +
" 'format' = 'json',\\n" +
" 'sink.partitioner' = 'round-robin'\\n" +
")"
);
// 根据 status 是否为 success 条件筛选出来值
String sql = "select " +
"user_id," +
"page_id," +
"status " +
"from input_kafka " +
"where status = 'success'";
Table ResultTable = tEnv.sqlQuery(sql);
//3.toRetractStream
DataStream<Tuple2<Boolean, Row>> resultDS = tEnv.toRetractStream(ResultTable, Row.class);
//4.打印输出
resultDS.print();
//5.执行sql 将筛选出来success的数据表插入到 output_kafka
tEnv.executeSql("insert into output_kafka select * from "+ResultTable);
//6.excute
env.execute();
再来一题,小试牛刀:
使用java或 scala语言编程实现消费 kafka中的数据并在数据处理阶段过滤掉
country Code不为cN的内容并打印输出
假设:集群主机 hostname为 node
Kafka的 topic为data
Kafka的消费组为 default Group
示例数据
{dt";“2020-08-05
10: 11: 09”,“country Code”: “CN”,“data”: [{“type” s1,score":0.8),“type”: 52,score": 0. 3}}}
{“dt”:“202008-05
10: 13: 12”,“country Code”: KW",“data”: [{“type”: “s2”,“score”: 0. 41.“type”: “s1”,“score”: 0.3}}}
{“dt”:“202008-05
10: 12: 15”, “country Code”: “US”, “data” [{“type”: “s4”,“score”: 0.3).“type”: 52","score: 0.5}}}
总结
以上便是大数据Flink面试考题——Flink高频考点,万字超全整理,
题目部分整理自网络
主要是为了准备不久后的考试,及为同笔者一样的萌新复习Flink
看完是不是觉得Flink跟没学的一样,笔者已贴心的为您准备好2021最新的Flink系列教程:
2021年最新最全Flink系列教程笔记_Flink
还有初学Flink必看的Flink思维导图
2021最新Flink思维导图__萌新制作(钜详细
愿你读过之后有自己的收获,如果有收获不妨一键三连一下~

以上是关于大数据Flink面试考题___Flink高频考点,万字超全整理(建议收藏)的主要内容,如果未能解决你的问题,请参考以下文章
Flink最后一站___Flink数据写入Kafka+从Kafka存入Mysql