Flink最后一站___Flink数据写入Kafka+从Kafka存入Mysql
Posted Maynor的大数据奋斗之路
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink最后一站___Flink数据写入Kafka+从Kafka存入Mysql相关的知识,希望对你有一定的参考价值。
前言
大家好,我是ChinaManor,直译过来就是中国码农的意思,我希望自己能成为国家复兴道路的铺路人,大数据领域的耕耘者,平凡但不甘于平庸的人。
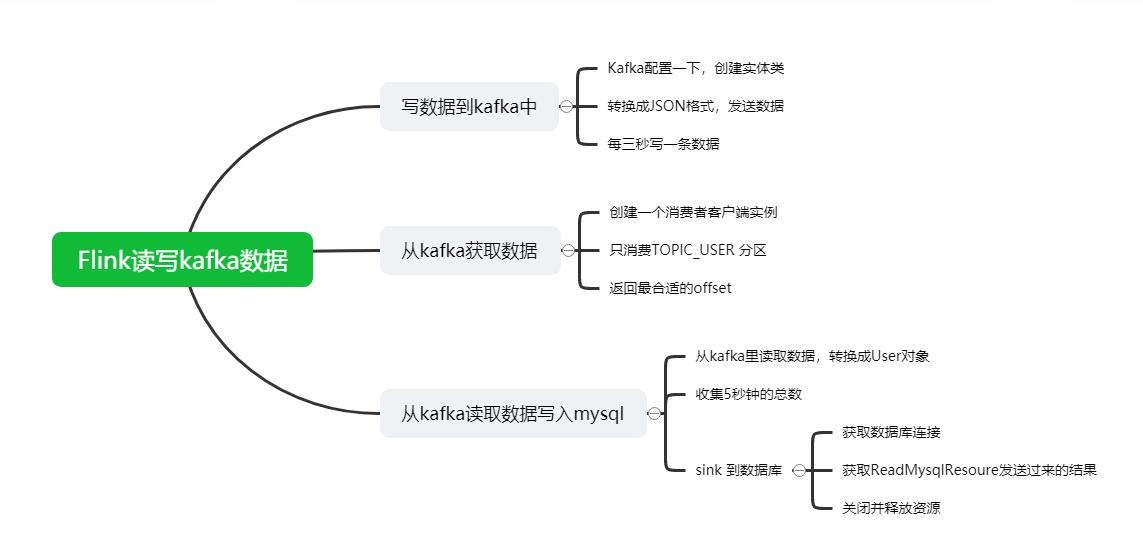
今天为大家带来Flink的一个综合应用案例:Flink数据写入Kafka+从Kafka存入mysql

第一部分:写数据到kafka中
public static void writeToKafka() throws Exception{
Properties props = new Properties();
props.put("bootstrap.servers", BROKER_LIST);
props.put("key.serializer", CONST_SERIALIZER);
props.put("value.serializer", CONST_SERIALIZER);
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
//构建User对象,在name为data后边加个随机数
int randomInt = RandomUtils.nextInt(1, 100000);
User user = new User();
user.setName("data" + randomInt);
user.setId(randomInt);
//转换成JSON
String userJson = JSON.toJSONString(user);
//包装成kafka发送的记录
ProducerRecord<String, String> record = new ProducerRecord<String, String>(TOPIC_USER, partition,
null, userJson);
//发送到缓存
producer.send(record);
System.out.println("向kafka发送数据:" + userJson);
//立即发送
producer.flush();
}
重点:
//发送到缓存
producer.send(record);
为了增强代码的Robust,我们将常量单独拎出来:
//本地的kafka机器列表
public static final String BROKER_LIST = "192.168.88.161:9092";
//kafka的topic
public static final String TOPIC_USER = "USER";
//kafka的partition分区
public static final Integer partition = 0;
//序列化的方式
public static final String CONST_SERIALIZER = "org.apache.kafka.common.serialization.StringSerializer";
//反序列化
public static final String CONST_DESERIALIZER = "org.apache.kafka.common.serialization.StringDeserializer";
main方法如下:
public static void main(String[] args) {
while(true) {
try {
//每三秒写一条数据
TimeUnit.SECONDS.sleep(3);
writeToKafka();
} catch (Exception e) {
e.printStackTrace();
}
}
}
第二部分:从kafka获取数据
KafkaRickSourceFunction.java
import com.hy.flinktest.entity.User;
import lombok.extern.slf4j.Slf4j;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.functions.source.RichSourceFunction;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.TopicPartition;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.ZooKeeper;
import java.io.IOException;
import java.time.Duration;
import java.util.Collections;
import java.util.List;
import java.util.Properties;
@Slf4j
public class KafkaRickSourceFunction extends RichSourceFunction<String>{
//kafka
private static Properties prop = new Properties();
private boolean running = true;
//作静态化处理,增强robust
private static Integer partition = WritedatatoKafka.partition;
static {
prop.put("bootstrap.servers",WritedatatoKafka.BROKER_LIST);
prop.put("zookeeper.connect","192.168.88.161:2181");
prop.put("group.id",WritedatatoKafka.TOPIC_USER);
prop.put("key.deserializer",WritedatatoKafka.CONST_DESERIALIZER);
prop.put("value.deserializer",WritedatatoKafka.CONST_DESERIALIZER);
prop.put("auto.offset.reset","latest");
prop.put("max.poll.records", "500");
prop.put("auto.commit.interval.ms", "1000");
}
@Override
public void run(SourceContext sourceContext) throws Exception {
//创建一个消费者客户端实例
KafkaConsumer<String,String> kafkaConsumer = new KafkaConsumer<String, String>(prop);
//只消费TOPIC_USER 分区
TopicPartition topicPartition = new TopicPartition(WritedatatoKafka.TOPIC_USER,partition);
long offset =0; //这个初始值应该从zk或其他地方获取
offset = placeOffsetToBestPosition(kafkaConsumer, offset, topicPartition);
while (running){
ConsumerRecords<String, String> records = kafkaConsumer.poll(1000);
if(records.isEmpty()){
continue;
}
for (ConsumerRecord<String, String> record : records) {
//record.offset();
//record.key()
String value = record.value();
sourceContext.collect(value);
}
}
}
然后 返回最合适的offset

/**
* 将offset定位到最合适的位置,并返回最合适的offset。
* @param kafkaConsumer consumer
* @param offset offset
* @param topicPartition partition
* @return the best offset
*/
private long placeOffsetToBestPosition(
KafkaConsumer<String, String> kafkaConsumer,
long offset, TopicPartition topicPartition) {
List<TopicPartition> partitions = Collections.singletonList(topicPartition);
kafkaConsumer.assign(partitions);
long bestOffset = offset;
if (offset == 0) {
log.info("由于offset为0,重新定位offset到kafka起始位置.");
kafkaConsumer.seekToBeginning(partitions);
} else if (offset > 0) {
kafkaConsumer.seekToBeginning(partitions);
long startPosition = kafkaConsumer.position(topicPartition);
kafkaConsumer.seekToEnd(partitions);
long endPosition = kafkaConsumer.position(topicPartition);
if (offset < startPosition) {
log.info("由于当前offset({})比kafka的最小offset({})还要小,则定位到kafka的最小offset({})处。",
offset, startPosition, startPosition);
kafkaConsumer.seekToBeginning(partitions);
bestOffset = startPosition;
} else if (offset > endPosition) {
log.info("由于当前offset({})比kafka的最大offset({})还要大,则定位到kafka的最大offset({})处。",
offset, endPosition, endPosition);
kafkaConsumer.seekToEnd(partitions);
bestOffset = endPosition;
} else {
kafkaConsumer.seek(topicPartition, offset);
}
}
return bestOffset;
}
@Override
public void cancel() {
running = false;
}
}
第三部分
主类:从kafka读取数据写入mysql
//1.构建流执行环境 并添加数据源
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> dataStreamSource = env.addSource(new KafkaRickSourceFunction());
//2.从kafka里读取数据,转换成User对象
DataStream<User> dataStream = dataStreamSource.map(lines -> JSONObject.parseObject(lines, User.class));
//3.收集5秒钟的总数
dataStream.timeWindowAll(Time.seconds(5L)).
apply(new AllWindowFunction<User, List<User>, TimeWindow>() {
@Override
public void apply(TimeWindow timeWindow, Iterable<User> iterable, Collector<List<User>> out) throws Exception {
List<User> users = Lists.newArrayList(iterable);
if(users.size() > 0) {
System.out.println("5秒内总共收到的条数:" + users.size());
out.collect(users);
}
}
})
//sink 到数据库
.addSink(new MysqlRichSinkFunction());
//打印到控制台
//.print();
第四部分:
写入到目标数据库sink
MysqlRichSinkFunction.java
@Slf4j
public class MysqlRichSinkFunction extends RichSinkFunction<List<User>> {
private Connection connection = null;
private PreparedStatement ps = null;
@Override
public void open(Configuration parameters) throws Exception {
// super.open(parameters);
log.info("获取数据库连接");
connection = DbUtil.getConnection();
String sql = "insert into user1(id,name) values (?,?)";
ps = connection.prepareStatement(sql);
}
public void invoke(List<User> users, Context ctx) throws Exception {
//获取ReadMysqlResoure发送过来的结果
for(User user : users) {
ps.setLong(1, user.getId());
ps.setString(2, user.getName());
ps.addBatch();
}
//一次性写入
int[] count = ps.executeBatch();
log.info("成功写入Mysql数量:" + count.length);
}
@Override
public void close() throws Exception {
//关闭并释放资源
if(connection != null) {
connection.close();
}
if(ps != null) {
ps.close();
}
}
}
总结
以上便是Flink数据写入Kafka+从Kafka存入Mysql
如果有帮助,给manor一键三连吧~~

以上是关于Flink最后一站___Flink数据写入Kafka+从Kafka存入Mysql的主要内容,如果未能解决你的问题,请参考以下文章