机器学习基石机器学习的种类
Posted 桃陉
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习基石机器学习的种类相关的知识,希望对你有一定的参考价值。
写在前面
主要讲了以下机器学习的不同分类标准,可以根据输出特征的不同、样本标签的不同、样本输入方式的不同以及输入特征的不同进行分类,这一节主要也是理解记忆的内容。
本文整理自台湾大学林轩田的《机器学习基石》
1. 不同的输出y(Out Space)
对于前面提到过的机器学习模型,我们知道它最终的输出就是 y y y,根据不同的输出格式 y y y,我们可以对ML进行分类。
∙
\\bullet
∙ 二元分类(binary classification):
输出结果只有两种,刚好是两个对立面,比如说买或不买、答案正确或错误等等。二元分类有两种模型,分别为线性模型和非线性模型。
∙
\\bullet
∙ 多元分类(Multiclass Classification):
多元分类顾名思义,就是输出 y y y 有多个值,这些值都是确定的分散的值。比如说输出判断手写体0-9一共十个值、判断区分三种不同的硬币等等。
∙
\\bullet
∙ 回归(Regression):
回归问题的输出 y y y 是一个区间范围,输出结果是这个范围内的不确定的数,比如说考试成绩0-100、房价的涨跌(在一个固定范围内)等等,它的输出范围是连续的。其中最简单的回归模型是线性模型。
∙
\\bullet
∙ 结构化学习(Structured Learning):
结构化学习常见于自然语言处理中,比如说我们需要判断一句话里面每个单词的词性,这个时候会把一句话完整的输入,得到的就是整个这句话的词性输出,就类似与一个结构体输出。
再上面提到的不同 y 的划分中,二元分类和回归是最常见的两个类型。
∙ \\bullet ∙ 练习
学校要设置一种门禁系统,对职工、学生、教授和其它人进行区分,应该使用上面提到的哪一种分类模型?
使用多元分类,因为输出是多个并且离散的结果,所以使用多元分类。(只需要掌握每种分类的特点即可。)
2. 不同格式的标签(Data Label)
对于我们常见的标签类型来说,一般都是形如 l a b e l = ( x , y ) label = (x,y) label=(x,y) 这样,带有一个输入 x x x,以及对应的输出 y y y,但是还会有不同的标签格式,它们分别对应这不同的学习模式,下面来具体对每一个模式进行分析。
∙
\\bullet
∙ 监督式学习(Supervised Learning):
▹ \\triangleright ▹ 监督式学习就是使用上面我们所说的最常见标签,所有的数据样本都带有一个输入特征 x x x,以及一个输出特征 y y y。机器可以通过数据样本这种一一对应的关系进行学习,它很容易的就能知道什么样的特征 x x x 对应着什么样的特征 y y y。
▹ \\triangleright ▹ 它的优点在于学习之后的准确率高,学习效果好;但是缺点在于每一个样本数据都需要进行标记对应的输出特征,花费的精力比较多。
▹ \\triangleright ▹ 举例:区分四种硬币,面值分别为1、5、10、25,输入特征为硬币大小以及重量,输出特征为具体是哪一种硬币:
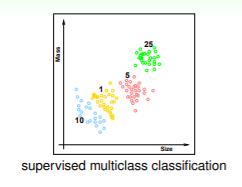
∙
\\bullet
∙ 非监督式学习(Unsupervised Learning):
▹ \\triangleright ▹ 非监督式学习的样本标签只有输入特征 x x x,而没有具体与之对应的输出特征 y y y。而机器面对这些样本需要根据它们的特征自行进行划分,这样就容易出错或者是和我们预期的结果出现偏差,但是它需要进行标记,所以花费精力少。很多情况下,使用非监督学习无法对其分类进行评价,总之这是一句具有挑战性但是非常有用的学习方式。
▹ \\triangleright ▹ 常见应用:对于网络上的文章,机器自行进行分析分类;对于申请信用卡的用户,机器自行对其进行归纳分类。
▹ \\triangleright ▹ 举例:区分四种硬币,面值分别为1、5、10、25,输入特征为硬币大小以及重量,机器自行对其分类,可能会出错,如下:

∙
\\bullet
∙ 半监督式学习(Semi-supervised Learning):
▹ \\triangleright ▹ 半监督式学习就是结合监督学习与非监督学习的特点,它会挑选一部分的数据样本进行标记输出特征 y y y ,而剩下的数据样本则只有输入特征,这样既花费的精力少,又协助机器进行分类。
▹
\\triangleright
▹ 举例:区分四种硬币,面值分别为1、5、10、25,输入特征为硬币大小以及重量,挑选一部分样本标记输出特征如下:

∙
\\bullet
∙ 增强学习(Reinforcement Learning):
▹ \\triangleright ▹ 增强学习与上面三种学习模式都不相同,我们给模型体重输入特征 x x x,但是给不了对应的输出特征 y y y,当模型运行以后得到输出,如果接近目标输出时,我们对其进行正向激励,远离目标输出时,我们对其进行反向激励。通过一步步的增强使其逐渐接近目标输出。
▹ \\triangleright ▹ 比如说我们训练狗子时,训练其坐下这一动作,如果狗子做出其他动作时,就对其进行小小的惩罚,使其认识到这样做是错误的,如果做出坐下或者接近坐下时,我们就对其进行奖励,通过引导使其逐渐学会这一动作。
上述四种学习模式中,监督式学习应用最为广泛。
3.不同的数据样本获取方式(Protocol)
数据样本就是机器进行学习的数据,而不同的获取方式同样也对应着不同的学习模式。
∙
\\bullet
∙ Batch Learning:
▹ \\triangleright ▹ 一次性将一批数据样本送给机器让其进行学习,数据样本可以是标记过的或者没有标记的,学习完以后会生成一个固定的处理函数 g g g。Batch Learning 是一种非常常见的模式。
▹ \\triangleright ▹ 比如说自动贩卖机想要区别不同硬币,我们一次性传入一批数据样本使其进行学习,学习完成以后处理函数 g g g 就不发生改变了。
∙
\\bullet
∙ Online:
▹ \\triangleright ▹ 每次传递一个数据样本样本进行学习,类似与在线更新的模式,一个一个进行学习,同时不断更新完善自己的处理函数 g g g。
▹ \\triangleright ▹ 与前面学习内容的联系:前面所学过的PLA 算法以及增强学习(Reinforcement Learning)都相当于这样的模式,每次改变一点不断优化。
∙
\\bullet
∙ Active Learning:
▹ \\triangleright ▹ 前面两种方式都是被动的学习方式,需要传入数据以后再进行学习。而Active Learning 是主动的学习方式,机器发现自己对于哪个输入特征 x x x 对应的输出特征 y y y 不了解时,主要询问结果进行学习,这样效率更高。并且当获取标签困难时(数据量过大,标记价格昂贵),这是一种较好的选择。
4. 不同的输入x(Input Space)
根据不同的输入特征也可以对模型进行分类,一般分为下面三种类型:
∙
\\bullet
∙ concrete features:
指具体的输入特征,比如说银行收集顾客信息里面的年龄、年收入和负债等等,对于机器来说,具体的特征更容易理解。
∙
\\bullet
∙ raw features:
这种类型一遍比较抽象,需要进行转换以后才可以使用,比如说识别手写体数字0-9,输入就是图面每个像素点,对于语音信号来说就是频谱等。
∙
\\bullet
∙ abstract features:
这个是最抽象的,完全就看不出有什么意义,比如说为歌曲打分时,输入歌曲的编号等,对于机器来说,需要对特征进行提取和转换。
以上是关于机器学习基石机器学习的种类的主要内容,如果未能解决你的问题,请参考以下文章