python爬虫:利用pdfkitimgkit这两个模块下载CSDN上的博客
Posted il_持之以恒_li
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python爬虫:利用pdfkitimgkit这两个模块下载CSDN上的博客相关的知识,希望对你有一定的参考价值。
python爬虫:利用pdfkit、imgkit这两个模块下载CSDN上的博客
小编过去一直想把自己收藏的CSDN博客下载下来,这样即使没有网络也能阅读,但是一直苦于一篇博客内容种类繁多,比如除了文字外,还有图片,网址链接等,如果一种一种的爬取,除了效率低之外,代码量也比较多,而且内容还会出现不完整的现象,后来想到直接把整个文章内容保存到一个html标签内,那么就可以实现了,但是觉得这样的话发表博客出来,那样也没有什么吸引读者的地方,因为大家都会,于是近段时间随便百度了一下,没想到python竟然还有这样的模块,可以将字符串转换成pdf和图片。觉得在python面前,只要你想不到,没有它做不到!
1.前期准备
除了爬虫常用的模块之外,还需要的模块有pdfkit、imgkit,安装这两个模块的命令分别为 pip install pdfkit、pip install imgkit
2.怎样实现
首先,需要一篇csdn博客的链接,我们点击进入这个链接,点击键盘的F12键,
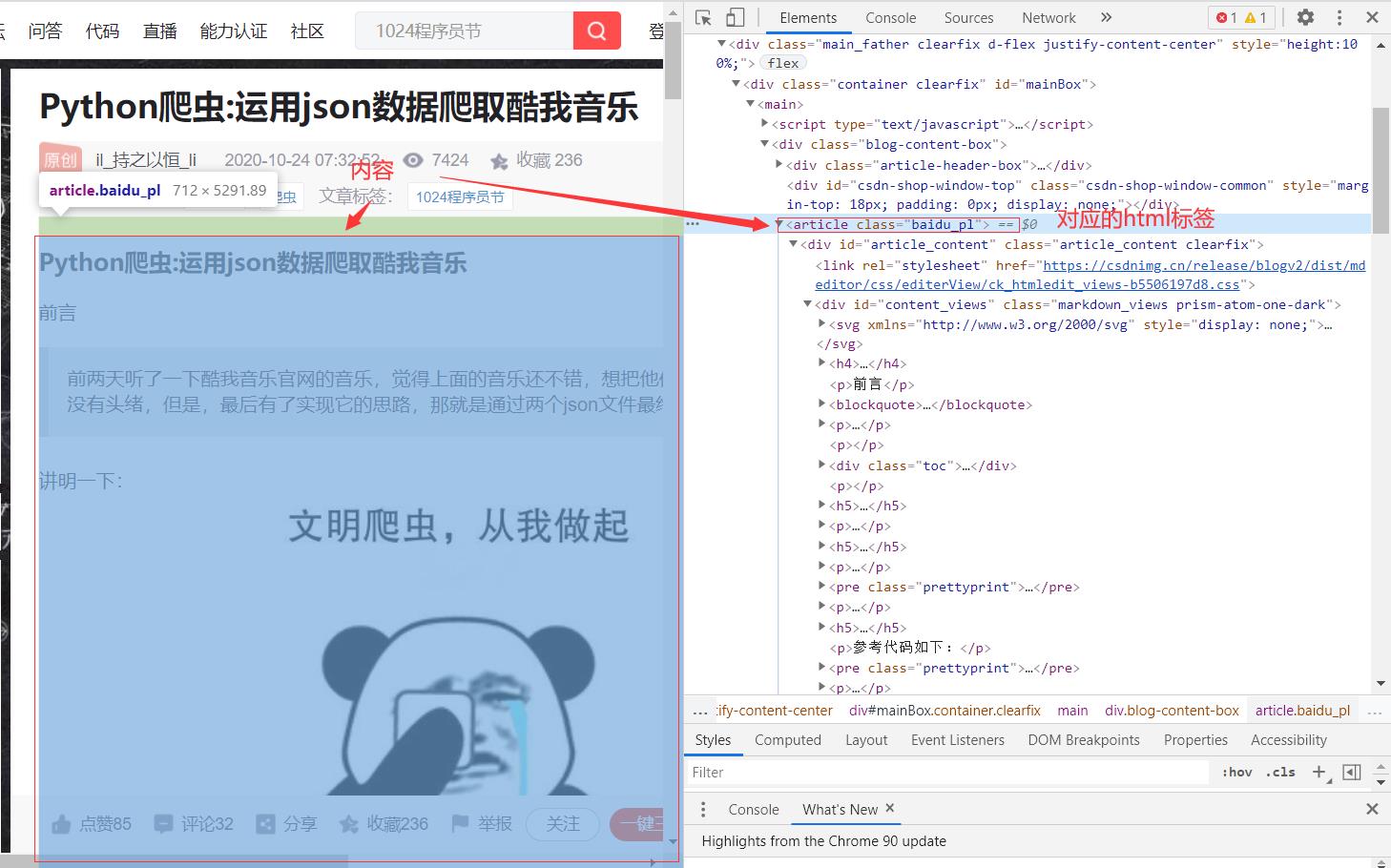
可以发现博客内容在article标签下面,我们只需爬取这个内容即可。爬取的内容是一字符串,我们通过字符串拼接,把它拼接成一个html字符串,最后就是转换成pdf和图片了,这里参考这两篇博客:使用python把html网页转成pdf文件 ,【Python】Python将HTML转成图片、PDF,参考了这两篇读者可以知道,除了需要安装上述那两个python模块外,还需要安装这个软件,wkhtmltopdf,下载地址为:https://wkhtmltopdf.org/downloads.html,这里需要安装自己电脑合适的版本和位数,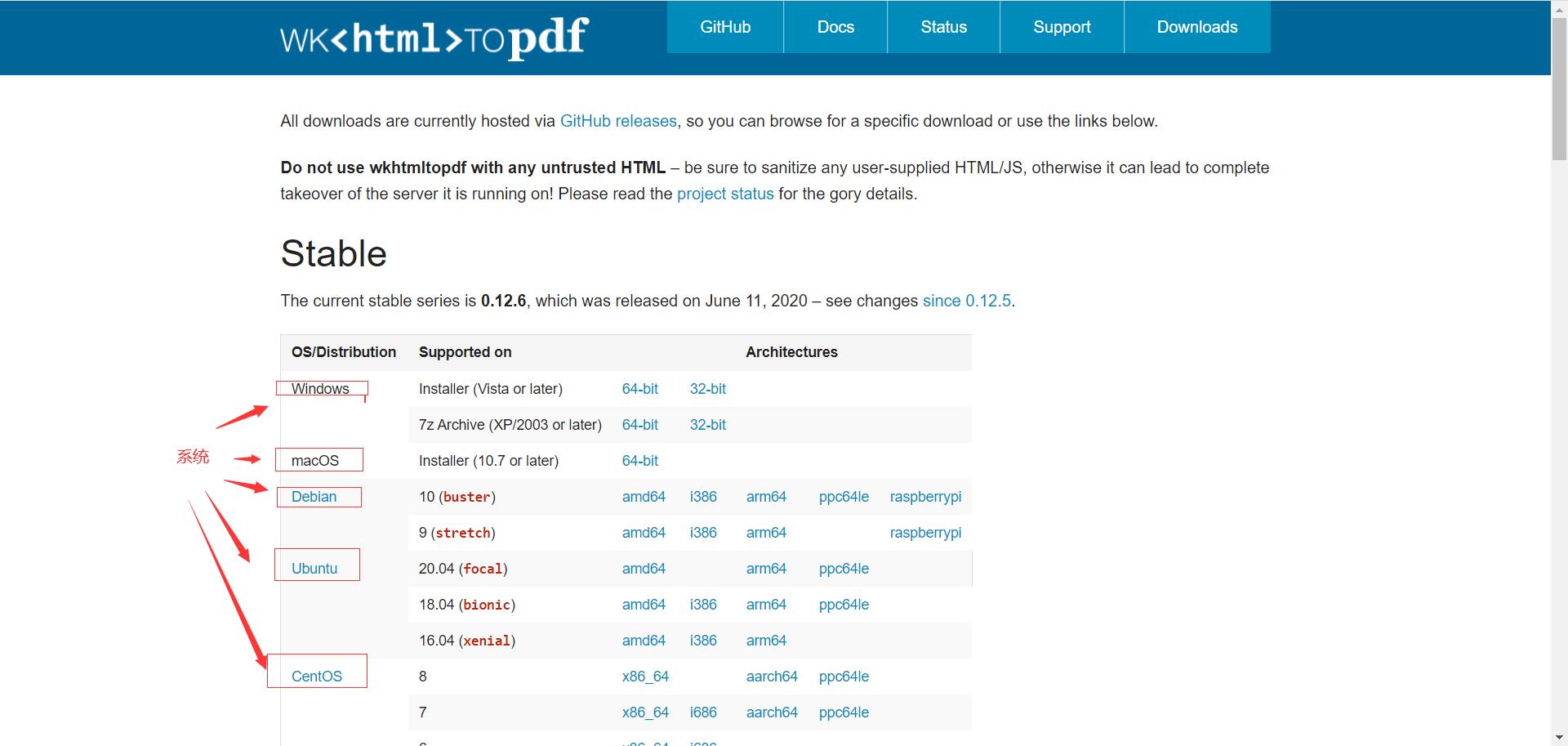
安装完成之后,可以发现在bin文件夹下面有两个.exe程序,如下,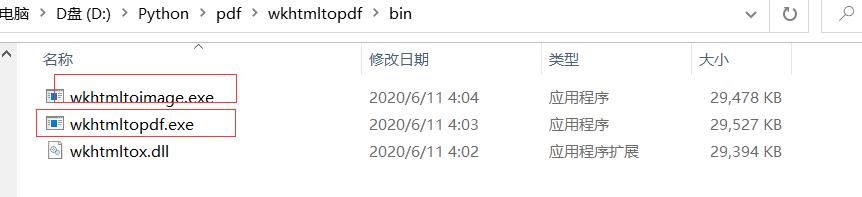
查看文件名称可以知道其中一个是转换成pdf的程序,另一个是转换成image的程序
3.代码和实现效果
import requests
import pdfkit
import imgkit
from lxml import etree
from Craw_2.spiders.userAgent import useragent # 这句代码可以注销
# 网址
#url='https://blog.csdn.net/qq_45404396/article/details/105965562'
url=input('请输入网址:') # 使用时请注意,输入网址后,删除最后一个字符,然后再加上;否则直接会在浏览器中打开这个网址
# 请求头
headers={
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36',
}
htmlStr='''
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
{}
</body>
</html>'''
# 得到随机模拟浏览器
# 这句代码可以注销
headers['user-agent']=useragent().getUserAgent()
rsp=requests.get(url=url,headers=headers)
HTML=etree.HTML(rsp.text)
content=HTML.xpath("//article[@class='baidu_pl']")[0]
html=etree.tostring(content,encoding='utf-8').decode('utf-8')
htmlStr=htmlStr.format(html)
path=input('请输入存储路径:')
# 这个博客名称就不爬取了,如果有一些博客名称违反了文件命名规范,
# 反而会报错,所以这里最好自己写入博客名称
fileName=input('请输入博客名称:')
print('正在转换成pdf!')
file='{}\\{}.pdf'.format(path,fileName)
config=pdfkit.configuration(wkhtmltopdf='D:\\Python\\pdf\\wkhtmltopdf\\\\bin\\wkhtmltopdf.exe')
pdfkit.from_string(htmlStr,file,configuration=config)
# 下面的方法是转换成图片的方法
print('正在转换成图片!')
file='{}\\{}.png'.format(path,fileName)
config2=imgkit.config(wkhtmltoimage='D:\\Python\\pdf\\wkhtmltopdf\\\\bin\\wkhtmltoimage.exe')
imgkit.from_string(htmlStr,file,config=config2)
读者记得看代码的注释,否则运行起来会报错,有两个地方可以注释掉,也不会报错,记得看,类useragent是小编自定义的一个类,代码如下:
import random
class useragent(object):
def getUserAgent(self):
useragents=[
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 2.0.50727; SLCC2; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.3; .NET4.0C; Tablet PC 2.0; .NET4.0E)',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0)',
]
return random.choice(useragents)
运行效果:
运用python爬虫爬取CSDN博客
以上是关于python爬虫:利用pdfkitimgkit这两个模块下载CSDN上的博客的主要内容,如果未能解决你的问题,请参考以下文章