Python scrapy 实现网页爬虫
Posted 走自己的路-让别人也有路走
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python scrapy 实现网页爬虫相关的知识,希望对你有一定的参考价值。
Python scrapy 安装和网页爬虫功能实现
现在组内有个工作就是维护恶意URL库,然后这个维护工作,主要是通过从几个会发布恶意URL地址的网站获取恶意网址,每次都得花费半天,很乏味的事情。所以就想到能否用个爬虫搞定。
这两天研究了下python scrapy,发现利用scrapy的确很容易实现网址爬取功能。
一、scrapy安装
简单的说明一下scrapy的安装过程
- window安装
先安装python,要提醒一下是环境变量的配置,只有环境变量配置对了,才能在命令行执行窗口找到python相关的命令。
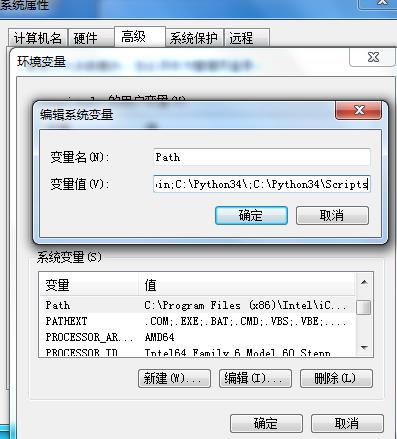
我这里安装的是3.4.3版本,可以看到,pip自动安装好了。
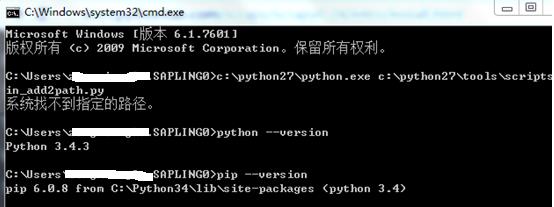
通过pip安装scrapy
- Ubuntu下安装
(1) 安装python,Ubuntu一般都是自带python的。只要python版本是2.7以上就可以
****@****-Vostro-270s:/home/saplingcode$ python --version
Python 2.7.6(2) 安装python-pip,安装这个的目的是通过pip来安装scrapy。

(3) 安装scrapy

二、爬虫代码实现
先用scrapy 创建一个工程

工程的目录结构如下,后面再详细讲解一下,每个文件作用。

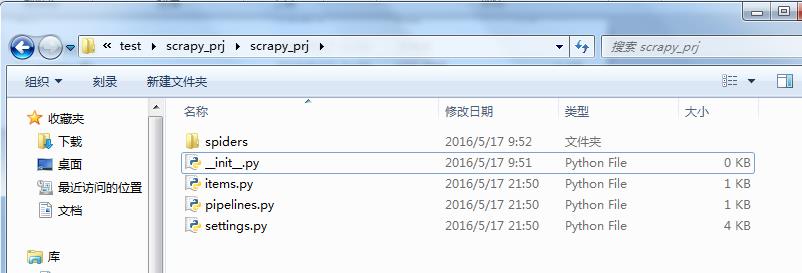
scrapy 中的item、spider、pipeline
从上面创建项目产生的文件中可以看到,项目中主要包括三类功能模块item、spider、pipeline,下面先对着三个文件的作用简要说明一下。
Item
Item 主要用来定义是保存爬取到的数据的容器;定义要保存数据的字段,该类必须继承scrapy.Item 类, 并且用 scrapy.Field 的类属性来定义一个Item。 如果还不清楚下面会用具体的例子说明。
Spider
Spider 是用于实现爬取页面主要功能,在该类中确定爬取哪些页面,页面爬取下来后,怎样获取需要爬取的内容。把爬取的内容保存到前面写的Item中。
首先该类必须继承 scrapy.Spider 类, 且需要定义以下三个属性:
name: 用于区别Spider。 该名字必须是唯一的,您不可以为不同的Spider设定相同的名字。Scrapy 通过该名字区分不同的爬虫。
start_urls: 包含了Spider在启动时进行爬取的url列表。 因此,第一个被获取到的页面将是其中之一。 后续的URL则从初始的URL获取到的数据中提取。
parse():必须重载spider的这个方法。 被调用时,每个初始URL完成下载后生成的 Response 对象将会作为唯一的参数传递给该函数。 该方法负责解析返回的数据(response data),提取数据(生成item)以及生成需要进一步处理的URL的 Request 对象。
pipeline
通过该模块可以实现一些过来功能,通过该模块可以实现对提取的数据(生成的Item)进一步处理,如过滤某些满足特定条件的item,改变生成数据的字符编码等。
下面以实现爬取www.sogou321.com所有导航链接为例子演示一下
item实现
这里只爬取各个导航的链接和对应的网站名称,所以item中只需要定义两个字段来保存对应的内容,这里分别为url、site_name,名字可以随便取。
# -*- coding: utf-8 -*-
#define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class ScrapyPrjItem(scrapy.Item):
# define the fields for your item here like:
site_name = scrapy.Field()
url = scrapy.Field()
spider实现
在上面创建的项目中,进入spiders目录可以看到除了init.py文件,就没其它文件了,这就需要我们自己创建spider文件了,可以通过如下命令创建,执行该命令后会再spider下自动生成 sogou321.py,可能有人会问能自己手动添加吗,答案是可以的。
/home/scrapy_prj$ scrapy genspider sogou321 sogou321.com自动生成的代码如下,可以看到该模块是继承scrapy.Spider ,重载了parse()函数
# -*- coding: utf-8 -*-
import scrapy
class Sogou321Spider(scrapy.Spider):
name = "sogou321"
allowed_domains = ["sogou321.com"]
start_urls = (
'http://www.sogou321.com/',
)
def parse(self, response):
pass自己重写parse()函数,我这里把name改成了”sogou”,这不是必须的,只是执行的时候要用修改后的名字。
import scrapy
from scrapy.selector import Selector
from scrapy_prj.items import ScrapyPrjItem
class Sogou321Spider(scrapy.Spider):
name = "sogou" #指定爬虫的名称,必须要唯一
allowed_domains = ["www.sogou321.com"]
start_urls = ["http://www.sogou321.com/"] #爬虫爬的网址,可以是多个网址
#每爬一个网址,都会回调该函数,response为响应数据
def parse(self, response):
sel = Selector(response)
sites = sel.xpath('//ul[@class="sortSite"]/li/em')
items=[]
for site in sites :
item = ScrapyPrjItem()
url_local = site.xpath('a/@href').extract()
site_name_local = site.xpath('a/text()').extract()
item['url'] = [u.encode('utf-8') for u in url_local]
item['site_name'] = [site_name_local] #s.encode('utf-8') for s in site_name_local
items.append(item)
return items这里重点讲解一下parse函数
1、在该函数中,我们必须分析页面返回数据的html格式,只有分析清楚了我们才知道页面什么地方的数据,下面数据是我从响应数据中摘录的一部分。可以看出我们要抓取的数据在标签嵌套关系是ul->li->em->a。
<em><a href="http://tieba.baidu.com/" >百度贴吧</a></em> 标签中的url和站名是需要抓取的信息。
<ul class="sortSite" id="qingtiancms_middle_ul_2">
<li><h4 class="tit fl"><a href="/htmls/luntan/">社 区</a></h4><span class="more fr"><a href="/htmls/luntan/" target="_blank">更多>></a></span>
<em><a href="http://tieba.baidu.com/" >百度贴吧</a></em>
<em><a href="http://www.tianya.cn/" >天涯社区</a></em>
<em><a href="http://www.mop.com/" >猫 扑</a></em>
<em><a href="http://qzone.qq.com/" >QQ空间</a></em>
<em><a href="http://www.weibo.com/" style="background: url(template/skin19_4_20100527_1/images/ico/weibo.gif) no-repeat 0;padding-left: 20px;margin-right: -20px;" >新浪微博</a></em>
<em><a href="http://www.renren.com/" >人人网</a></em>
</li>
</ul>2、知道了要抓取的内容在什么地方之后,就需要通过手段提取出需要的内容,这就需要用xpath了。xpath具体的不在详解,自己看看XPath教材,挺简单的。
sites = sel.xpath(‘//ul[@class=”sortSite”]/li/em’), 表示提取ul标签并且标签class属性为sortSite,改标签包含li标签,并且li包含em标签,提取em标签中的内容保存在列表sites中。如下
<ul class="sortSite">
<li>
<em>
提取这里的内容
</em>
</li>
</ul>提取后sites 中的数据如下,下面的数据每一行作为sites list表中的一项。
<a href="http://tieba.baidu.com/" >百度贴吧</a>
<a href="http://www.tianya.cn/" >天涯社区</a>
<a href="http://www.mop.com/" >猫 扑</a>
<a href="http://qzone.qq.com/" >QQ空间</a>
下面这部分代码是处理上面提取出来保存在sites 列表中的数据,从中提取出链接url和站名(链接文本),保存在item中,最后都会append到items列表中返回。
for site in sites :
item = ScrapyPrjItem()
#提取链接url
url_local = site.xpath('a/@href').extract()
#提取<a>标签中的文本
site_name_local = site.xpath('a/text()').extract()
item['url'] = [u.encode('utf-8') for u in url_local]
item['site_name'] = [site_name_local] #s.encode('utf-8') for s in site_name_local
items.append(item)执行结果
item 和spider都写完了,最基本的爬虫就写完了,执行一下。
执行命令scrapy crawl sogou -o sogou.json,爬虫名字必须是在spider模块中定义的那个name,这例子中是sogou 。爬取结果保存到json文件中
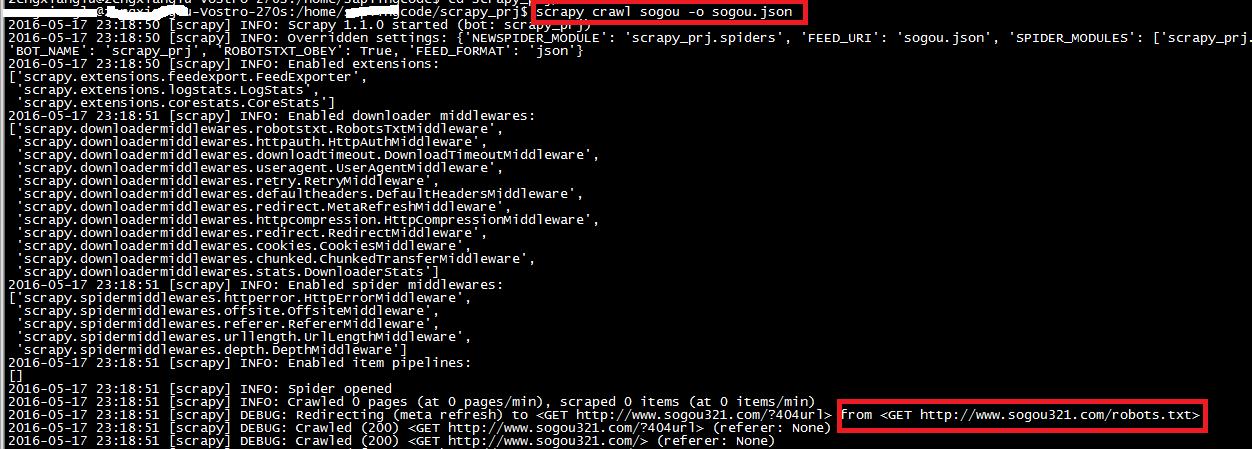
爬取结果如下:
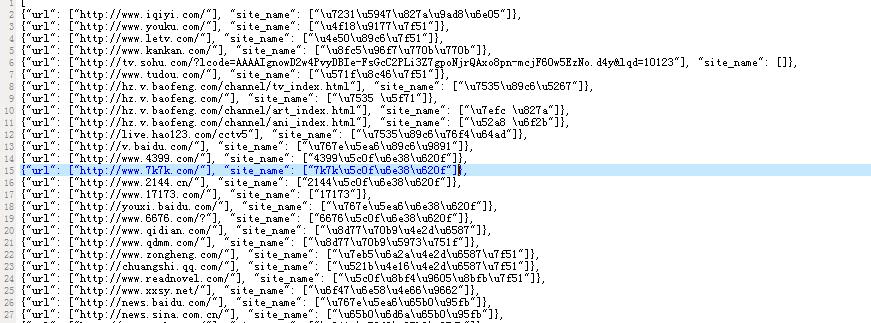
pipeline实现
看一下上面的执行结果,大家可以发现,中文看起来都是乱码,其实是Unicode编码,很难看懂。前面已经讲到,在pipeline模块可以实现对提取到的数据(items数据)进行处理。所以只要保证写文件的时候用utf-8编码,应该就不会出现“乱码”问题了。
要注意,该模块的功能在配置文件中默认是没打开的,需要在配置文件settings.py中加入 ITEM_PIPELINES = ‘scrapy_prj.pipelines.ScrapyPrjPipeline’: 1 ,需要指定到pipelines模块中具体的类。
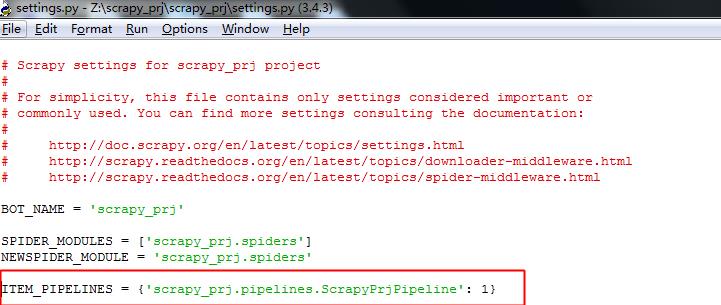
# -*- coding: utf-8 -*- pipelines.py
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
import json
import codecs
class ScrapyPrjPipeline(object):
def __init__(self):
self.file = codecs.open('sogou321.json', 'wb', encoding='utf-8')
def process_item(self, item, spider):
line = json.dumps(dict(item)) + '\\n'
self.file.write(line.decode("unicode_escape"))
return item
加入pipelines的执行结果

以上是关于Python scrapy 实现网页爬虫的主要内容,如果未能解决你的问题,请参考以下文章
如何在scrapy框架下,用python实现爬虫自动跳转页面来抓去网页内容??