如何在scrapy框架下,用python实现爬虫自动跳转页面来抓去网页内容??
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何在scrapy框架下,用python实现爬虫自动跳转页面来抓去网页内容??相关的知识,希望对你有一定的参考价值。
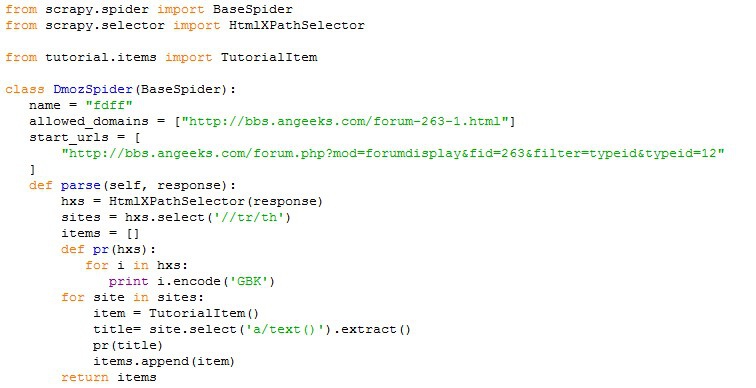
我现在想爬取http://bbs.angeeks.com/forum.php?mod=forumdisplay&fid=263&filter=typeid&typeid=12这个网站,在“软件分析”类别下的所有帖子的标题。由于帖子较多,所以分了很多页。但我设置的爬虫,只能爬取某一页的标题内容,这样太慢了。我想问一下,要如何修改我的爬虫代码,就可以实现爬虫的自动跳转呢???我用python编写的爬虫代码如下:
根据架构图介绍一下Scrapy中的各大组件及其功能:
Scrapy引擎(Engine):负责控制数据流在系统的所有组建中流动,并在相应动作发生触发事件。
调度器(Scheduler):从引擎接收Request并将它们入队,以便之后引擎请求request时提供给引擎。
下载器(Downloader):负责获取页面数据并提供给引擎,而后提供给Spider。
Spider:Scrapy用户编写用于分析Response并提取Item(即获取到的Item)或额外跟进的URL的类。每个Spider负责处理一个特定(或一些网站)。
Item Pipeline:负责处理被Spider提取出来的Item。典型的处理有清理验证及持久化(例如存储到数据库中,这部分后面会介绍存储到MySQL中,其他的数据库类似)。
下载器中间件(Downloader middlewares):是在引擎即下载器之间的特定钩子(special hook),处理Downloader传递给引擎的Response。其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能(后面会介绍配置一些中间并激活,用以应对反爬虫)。
Spider中间件(Spider middlewares):是在引擎及Spider之间的特定钩子(special hook),处理Spider的输入(response)和输出(Items即Requests)。其提供了一个简便的机制,通过插入自定义的代码来扩展Scrapy功能。 参考技术A
爬虫跟踪下一页的方法是自己模拟点击下一页连接,然后发出新的请求。请看:
item1 = Item()yield item1
item2 = Item()
yield item2
req = Request(url='下一页的链接', callback=self.parse)
yield req
注意使用yield时不要用return语句。
有两点疑问:
1、按照大牛您的方法,我是不是要把每一页的链接都填到url里??
2、这一段代码应该插入到上述我写好的代码中的哪个具体位置呢??
谢谢!!!
下一页的链接可以直接用xpath来取。
这是一个类似递归的过程,爬完当前页,只请求下一页,在回调函数中处理并继续请求,直到到达最后一页。
将你的return换成yield,从return数组变成yield Item,然后在最后yield Request。
注意import类定义:
from scrapy.http import Request追问啊~~
还是不明白!
要不麻烦大牛留个QQ,我们Q聊!!
以上是关于如何在scrapy框架下,用python实现爬虫自动跳转页面来抓去网页内容??的主要内容,如果未能解决你的问题,请参考以下文章