性能测试:数据库性能问题实战分析
Posted 七月的小尾巴
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了性能测试:数据库性能问题实战分析相关的知识,希望对你有一定的参考价值。
接口压测分析
现在我们来压测一个获取用户信息接口,这个接口会涉及到数据库的数据查询。我们的项目是部署正在应用服务器上面的,因此我们需要同时监控应用服务器和数据库服务器。
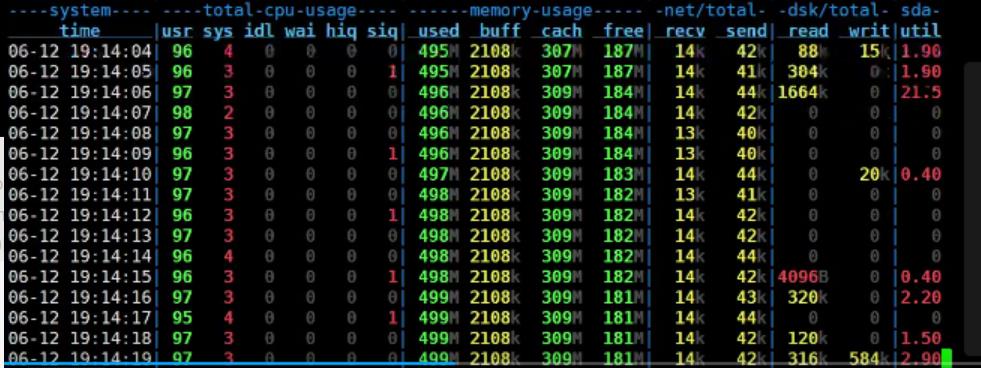
那么我们下面直接压测,来看一下它的性能情况。运行一段时间之后,我们可以看到这个接口的性能非常一般。tps只有40左右,并且响应时间高达200多。

那么下面我们来看一下tomcat的这台服务器,cpu的使用率并不高,包括网络、磁盘IO等都没有什么问题。

下面我们在来看一下数据库的服务器,可以看到cpu已经高达100%了。存在非常明显的性能问题。那么我们可以初步分析,问题可能出现在数据库查询上面,因为我们只用了10个并发,这个并不算多。
数据库性能分析-索引
下面我们来回看一下我们前面压测所出现的现象:
TPS很低,响应时间很长,数据库服务器cpu很高(接近100%),应用服务器负载比较低。
通常我们数据库服务器cpu很高,一般都是因为SQL执行效率低导致的。可能有三方面原因:
1、数据库表中缺少必要的索引;
2、索引不生效;
3、SQL不够优化;
关于索引
索引是对数据库表中一列或多列的值进行排序的一种结构,存储了表中的关键字段,使用索引可快速访问数据库表中的特定信息。
那么我们初步定位是由于SQL导致的性能问题,我们是不是可以对SQL进行监控呢?
下面我们需要对mysql配置慢查询。具体如何配置,可以查看我的这篇博客:《数据库慢查询配置》。
下面我们开始对SQL进行监控,进入到mysql存放的日志路径下(之前慢查询配置中有返回具体的日志路径),因为压测前,我们并不知道里面的数据是不是我们之前压测的数据,所以我们输入 > 文件名称,如 > test-slow.log 来清空里面的数据,然后再进行压测。

压测过程中,我们可以看到日志中出现了大量的SQL日志,那么我们可以确定再压测的过程中,这些SQL的响应时间已经超过了我们原先配置的预期值了。

那么我们已经知道有哪些慢SQL了,接下来应该如何对这些SQL进行分析呢?
在/usr/bin目录下,使用mysql自带命令 mysqldumpslow 。这个工具下面提供了一些参数,关于参数的介绍,可以再我之前的慢sql配置的博客中,有介绍。
那么我们下面用如下命令进行分析:
mysqldumpslow –s at -t 0 test-slow.log
// 显示出耗时最长的5个

上面我们可以看到返回了一条SQL。我们来具体看看这些返回的数据到底是什么含义:
- Count:顾名思义,就是这条SQL执行的次数
- Time:SQL执行的时间,这里我配置的慢SQL时间是(0.05s),这里0.07s相当于是70ms,可能很多人会觉得70ms算短的,时间确实很短,但是对于一个接口而言,数据库就用到了70ms,那么整个http请求,包含业务逻辑、网络因素、以及前端渲染等时长,最终用户所得到的响应是非常长的。
- 下面显示了超时的SQL
我们可以看到这是一条非常基础的查询SQL,那么我们已经知道SQL非常慢了,具体我们应该怎么去做分析呢?我们mysql提供了这个方法。
打开navicat数据库连接工具,做过测试的朋友,几乎每个人电脑都会安装这个工具。下面我们输入这条SQL语句,再SQL前,加上 EXPLAIN, EXPLAIN指的是执行计划。

我们的SQL为什么执行的慢的,主要查看的就是结果的type。Type指的是我们对索引的使用情况。下面是关于MYSQL执行计划 TYPE值的关系:
| type | 说明 |
|---|---|
| ALL | 全数据表扫描 |
| index | 全索引表扫描 |
| RANGE | 对索引列进行范围查找 |
| INDEX_MERGE | 合并索引,使用多个单列索引搜索 |
| REF | 根据索引查找一个或多个值 |
| EQ_REF | 搜索时使用primary key 或 unique类型 |
| CONST | 常量,表最多有一个匹配行,因为仅有一行,在这行的列值可被优化器剩余部分认为是常数,const表很快,因为它们只读取一次。 |
| SYSTEM | 系统,表仅有一行(=系统表)。这是const联接类型的一个特例 |
性能:all < index < range < index_merge < ref_or_null < ref < eq_ref < system/const 性能在 range 之下基本都可以进行调优
那我们可以看到上面的SQL查询,他返回的type值为all,这个性能是非常差的。通常出现all的情况下,主要是因为该表没有建索引导致的。下面我们打开该表的表设计可以看到果然表中没有建索引。

既然是索引问题,那么我们可以给他加索引,通常索引是加sql where后面的条件。(通常发现是索引问题,可以让开发通知DB去加就行。)
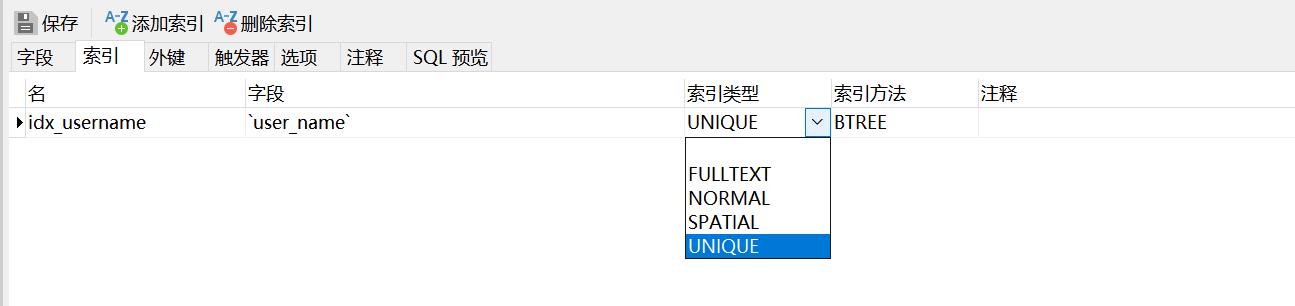
下面我们把这个索引值给加上。上方我们可以看到有个索引类型,通常工作中常用的类型有NORMAL和UNIQUE。选择类型需要根据业务类型也决定,UNIQUE 是唯一值,如果说我们选择了UNIQUE,那么之后user_name就是唯一的,之后插入相同的user_name,数据库就会报错。
这里我们公司的业务是user_name是唯一的。所以选择 UNIQUE 。后方的索引方式,默认都是选择BTREE。
保存之后,我们再来看一下sql的执行计划。我们可以看到直接变成const了。从最差变成了最好。

现在我们加了索引,再重新做一下压测。我们来看一下压测的数据。性能明显提升上去了,由原先的40个tps直接到了将近1000,响应时间也从原来的200ms变成了十几毫秒。

下面我们再来看一下数据库服务器,cpu的空闲率现在也变成了70%左右了。

我们再来看一下应用服务器,但是现在压力到了应用服务器上面。通常情况下应用服务器如果性能不好我们可以进行扩容,但是如果是数据库服务器性能问题,会比较麻烦,这个涉及到了架构问题。

因此我们可以得到总结,如果我们的SQL是全表扫描会非常影响服务器的性能,直接导致数据库服务器的cpu飙升。因此可以得出索引的设置,直接影响到了我们的性能,索引的选择相差也是非常大的。
联合索引
我们有了前面的经验,下面再来拓展另外一个关于索引的知识:联合索引。那么什么是联合索引呢?
一个项目不可能只有一个user_name的字段去查询SQL,有个业务比如回去查询email,或者查询age。考虑到我们业务的复杂性,我们需要添加联合索引。
索引的误区
这里有些朋友可能会有一个误区,就是索引这么好,可以极快的提升数据库的性能,那么我是否可以把每个字段都加上索引呢?
其实并不是的,一般来说像阿里巴巴,他们的开发手册就是有个规范是,索引最多只能添加4个,这个并不是一个强制要求,只是一个业界的规范。如果说我们添加的索引过多,会影响到更新和删除的性能。
那么既然我们有那么多个字段,可以把这些字段全部放到一个索引中,这种就叫做 联合索引。
下面我们添加user_name、age、eamil。

下面我们压测的脚本中,查询user_name 和 eamil两个信息,我们再来看一下压测的数据。
我们可以看到tps就降下来了,并且响应时间也变得非常长。

我们再来看一下应用服务器的性能,cpu的空闲率变成90%左右。

数据库服务器,cpu的使用率又变成100%了。
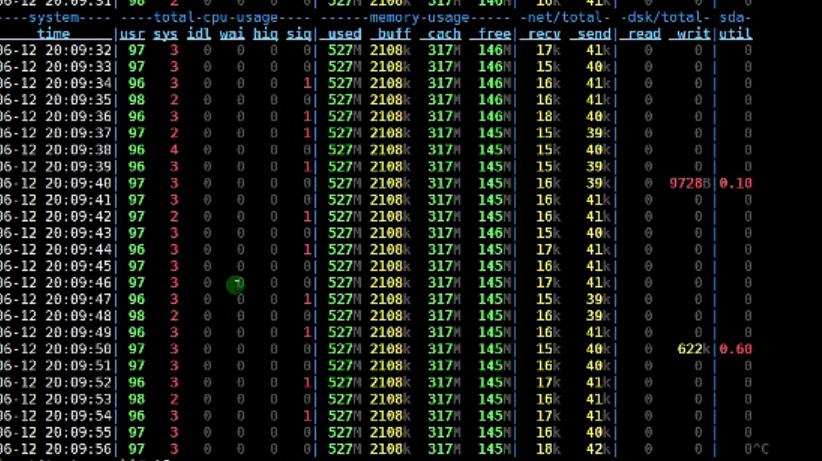
下面我们来看一下慢SQL的日志,我们可以看到还是这条SQL,那么我们来看一下这条SQL的执行计划。

我们可以看到执行计划又变成 ALL;

联合索引的最左前缀
上面的问题,主要是因为联合索引失效导致的。可以看到我们设置的索引排序是 age、email、user_name。但是我们执行的sql,是优先查询user_name的。
联合索引检索数据时,会从最左边开始匹配(忽略sql字段顺序),如果匹配不到,就不会使用索引。
因此我们可以看到,开头的是age,user_name 在后面,所有联合索引没有失效。
下面我们调整一下MYSQL的联合索引顺序,可以看到type又变成ref:

以上是关于性能测试:数据库性能问题实战分析的主要内容,如果未能解决你的问题,请参考以下文章
在 VS2010 中使用 Nvidia NSight 进行 CUDA 性能分析 - 时间线上的片段