「深度学习一遍过」必修11:优化器的高级使用+学习率迭代策略+分类优化目标定义
Posted 荣仔!最靓的仔!
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了「深度学习一遍过」必修11:优化器的高级使用+学习率迭代策略+分类优化目标定义相关的知识,希望对你有一定的参考价值。
本专栏用于记录关于深度学习的笔记,不光方便自己复习与查阅,同时也希望能给您解决一些关于深度学习的相关问题,并提供一些微不足道的人工神经网络模型设计思路。
专栏地址:「深度学习一遍过」必修篇
目录
1.1.3 Nesterov accelerated gradient 法
1 优化器的高级使用
为每个参数单独设置选项:
optim.SGD([
{'params': model.base.parameters()},
{'params': model.classifier.parameters(), 'lr': 1e-3}
], lr=1e-2, momentum=0.9)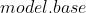 的参数将会使用
的参数将会使用 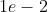 的学习率,
的学习率,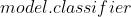 的参数将会使用
的参数将会使用 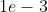 的学习率,并且
的学习率,并且 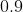 的
的 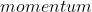 将会被用于所有的参数。
将会被用于所有的参数。
梯度下降算法中,学习率太大,函数无法收敛,甚至发散,如下图。学习率足够小,理论上是可以达到局部最优值的(非凸函数不能保证达到全局最优),但学习率太小却使得学习过程过于缓慢,合适的学习率应该是能在保证收敛的前提下,能尽快收敛。对于深度网络中,参数众多,参数值初始位置随机,同样大小的学习率,对于某些参数可能合适,对另外一些参数可能偏小(学习过程缓慢),对另外一些参数可能太大(无法收敛,甚至发散),而学习率一般而言对所有参数都是固定的,所以无法同时满足所有参数的要求。通过引入
可以让那些因学习率太大而来回摆动的参数,梯度能前后抵消,从而阻止发散。
1.1 基于更新方向
1.1.1 随机梯度下降 SGD 优化算法
torch.optim.SGD(params, lr=0.1, momentum=0, dampening=0, weight_decay=0, nesterov=False)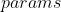 (
(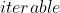 ) – 待优化参数的 或者是定义了参数组的
) – 待优化参数的 或者是定义了参数组的 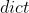
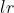 (
( ) – 学习率
) – 学习率 - (, 可选) – 动量因子(默认:
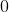 )
) 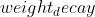 (, 可选) – 权重衰减(
(, 可选) – 权重衰减(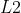 惩罚)(默认:)
惩罚)(默认:) 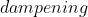 (, 可选) – 动量的抑制因子(默认:)
(, 可选) – 动量的抑制因子(默认:) 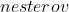 (
(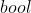 , 可选) – 使用
, 可选) – 使用 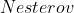 动量(默认:
动量(默认: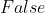 )
)
在某多分类任务中,设置其损失函数、优化器、学习率:
criterion = nn.CrossEntropyLoss()
optimizer_ft = optim.SGD(modelclc.parameters(), lr=0.1, momentum=0.9)
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=100, gamma=0.1)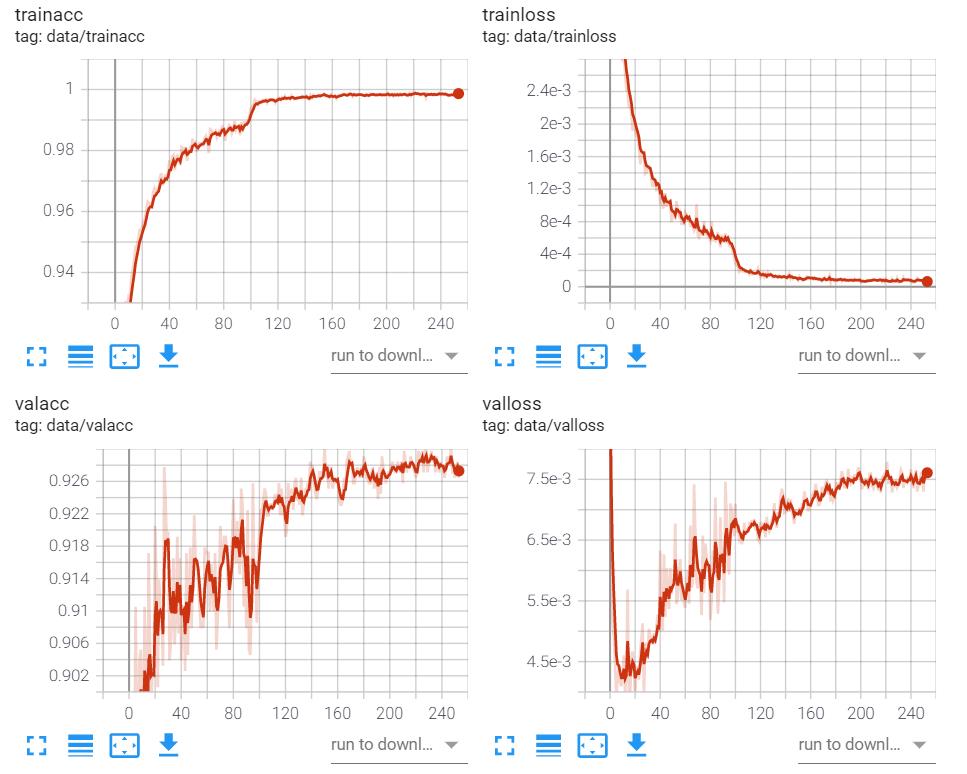
我们可视化后发现,训练集和测试集整体的正确率是呈现上升趋势,训练集的 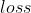 呈现下降趋势也没问题,但测试集的 呈现突然地暴涨而无法收敛,于是我们断定选用
呈现下降趋势也没问题,但测试集的 呈现突然地暴涨而无法收敛,于是我们断定选用 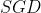 优化算法,尤其是填入的这几个参数无法阻止模型梯度发散,所以决定换个优化算法试试,具体见下文。
优化算法,尤其是填入的这几个参数无法阻止模型梯度发散,所以决定换个优化算法试试,具体见下文。
1.1.2 momentum 动量法
加速SGD,特别是处理高曲率、小但一致的梯度;积累了之前梯度指数级衰减的移动平均,并且继续沿该方向移动。

如果梯度方向不变,就越发更新的快,反之减弱,当前保证梯度收敛。
1.1.3 Nesterov accelerated gradient 法
在标准动量方法中添加了一个校正因子
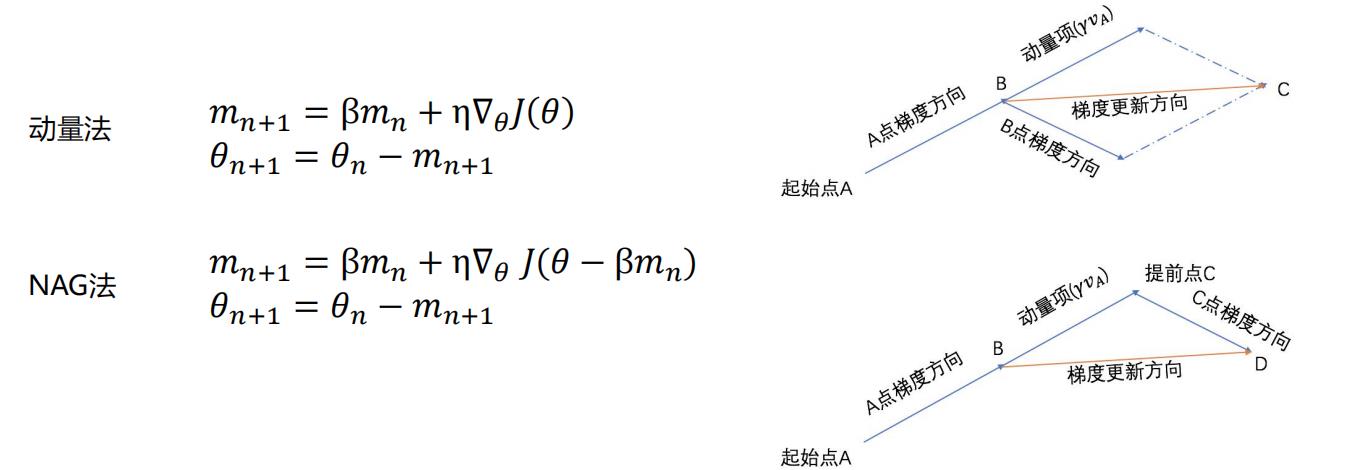
要求梯度下降更快,更加智能,直接先按照前一次梯度方向更新一步将它作为当前的梯度
1.2 基于选择更为合理的学习率
1.2.1 Adam 优化算法
对梯度的一阶和二阶都进行了估计与偏差修正,使用梯度的一阶矩估计和二阶矩估计来动态调整每个参数的学习率。
- 对学习率没有那么敏感,学习步长有一个确定 的范围,参数更新比较稳。
- 学习率在训练的后期仍然可能不稳定导致无法 收敛到足够好的值,泛化能力较差。
torch.optim.Adam(params, lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0)- () – 待优化参数的iterable或者是定义了参数组的
- (, 可选) – 学习率(默认:)
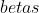 (
(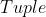 [, ], 可选) – 用于计算梯度以及梯度平方的运行平均值的系数(默认:,
[, ], 可选) – 用于计算梯度以及梯度平方的运行平均值的系数(默认:,)
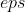 (, 可选) – 为了增加数值计算的稳定性而加到分母里的项(默认:
(, 可选) – 为了增加数值计算的稳定性而加到分母里的项(默认: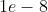 )
) 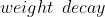 (, 可选) – 权重衰减( 惩罚)(默认: )
(, 可选) – 权重衰减( 惩罚)(默认: )
在某多分类任务中,设置其损失函数、优化器、学习率:
criterion = nn.CrossEntropyLoss()
optimizer_ft = optim.Adam(modelclc.parameters(), lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0)
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=100, gamma=0.1)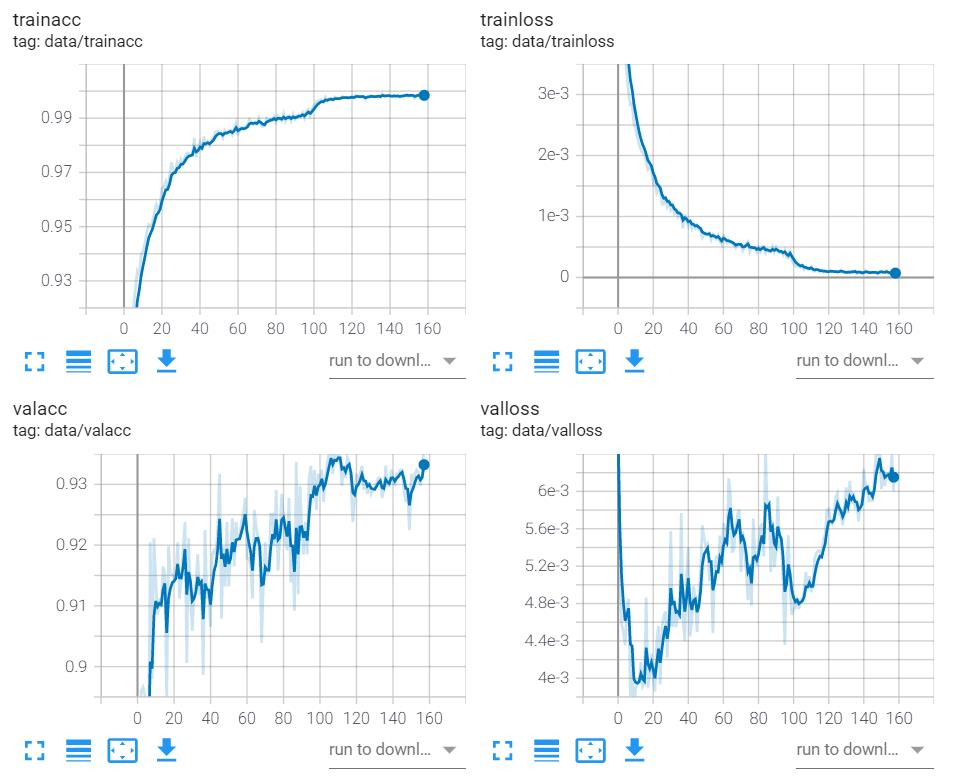
还是同样的结果:验证集的 又没有收敛,于是我果断提前按下了 “暂停” 键。此情此景下,我分析:改了个优化器不行,于是我决定进行调参这一痛苦操作…………
1.2.2 RMSprop 优化算法
torch.optim.RMSprop(params, lr=0.01, alpha=0.99, eps=1e-08, weight_decay=0, momentum=0, centered=False)- () – 待优化参数的 或者是定义了参数组的
- (, 可选) – 学习率(默认:)
- (, 可选) – 动量因子(默认:)
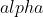 (, 可选) – 平滑常数(默认:
(, 可选) – 平滑常数(默认:)
- (, 可选) – 为了增加数值计算的稳定性而加到分母里的项(默认:)
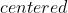 (, 可选) – 如果为
(, 可选) – 如果为  ,计算中心化的
,计算中心化的 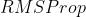 ,并且用它的方差预测值对梯度进行归一化
,并且用它的方差预测值对梯度进行归一化 - (, 可选) – 权重衰减( 惩罚)(默认: )
1.2.3 Adadelta优化算法
Adadelta 与 Adagrad 不同,只累加了一个窗口的梯度,使用动量平均计算。
- 优点:保留了 Adagrad 调节不同维度学习率的优势
- 缺点:训练后期反复在局部最小值附近抖动
torch.optim.Adadelta(params, lr=1.0, rho=0.9, eps=1e-06, weight_decay=0)- () – 待优化参数的 或者是定义了参数组的
 (, 可选) – 用于计算平方梯度的运行平均值的系数(默认:)
(, 可选) – 用于计算平方梯度的运行平均值的系数(默认:) - ( , 可选) – 为了增加数值计算的稳定性而加到分母里的项(默认:
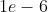 )
) - (, 可选) – 在
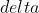 被应用到参数更新之前对它缩放的系数(默认:
被应用到参数更新之前对它缩放的系数(默认: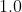 )
) - (, 可选) – 权重衰减( 惩罚)(默认: )
1.2.4 Adagrad优化算法
自适应地为各个维度的参数分配不同的学习率
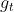 较小的时候,能够放大梯度,较大的时候,能够约束梯度(激励+惩罚)。
较小的时候,能够放大梯度,较大的时候,能够约束梯度(激励+惩罚)。
- 梯度累积导致学习率单调递减,后期学习率非常小。
- 需要设置一个合适的全局初始学习率 。
torch.optim.Adagrad(params, lr=0.01, lr_decay=0, weight_decay=0)- () – 待优化参数的 或者是定义了参数组的
- (, 可选) – 学习率(默认: )
 (, 可选) – 学习率衰减(默认: )
(, 可选) – 学习率衰减(默认: ) 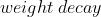 (, 可选) – 权重衰减( 惩罚)(默认: )
(, 可选) – 权重衰减( 惩罚)(默认: )
1.2.5 Adamax优化算法
torch.optim.Adamax(params, lr=0.002, betas=(0.9, 0.999), eps=1e-08, weight_decay=0)- () – 待优化参数的 或者是定义了参数组的
- (, 可选) – 学习率(默认:
 )
) - ( [, ], 可选) – 用于计算梯度以及梯度平方的运行平均值的系数
- (, 可选) – 为了增加数值计算的稳定性而加到分母里的项(默认:)
- (, 可选) – 权重衰减( 惩罚)(默认: )
1.2.6 AMSgrad 方法
Adam 类的方法之所以会不能收敛到好的结果,是因为在优化算法中广泛使用的指数衰减方法会使得梯度的记忆时间太短。
使用过去平方梯度的最大值来更新参数, 而不是指数平均 。
2 学习率迭代策略
2.1 StepLR调整算法
等间隔调整学习率,调整倍数为 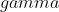 倍,调整间隔为
倍,调整间隔为 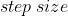 ,
,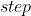 指
指 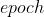 。
。
torch.optim.lr_scheduler.StepLR(optimizer, step_size, gamma=0.1, last_epoch=-1)scheduler = StepLR(optimizer, step_size=30, gamma=0.1)
for epoch in range(100):
train(...)
validate(...)
scheduler.step()2.2 MultiStepLR 调整算法
调节的 是自己定义。
torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones, gamma=0.1, last_epoch=-1)lr = 0.05 if epoch < 30
lr = 0.005 if 30 <= epoch < 80
lr = 0.0005 if epoch >= 80
scheduler = MultiStepLR(optimizer, milestones=[30,80], gamma=0.1)
for epoch in range(100):
train(...)
validate(...)
scheduler.step()2.3 ExponentialLR
指数形式增长
torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma, last_epoch=-1)2.4 LambdaLR
能够根据自己的定义调节 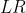
torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda, last_epoch=-1)lambda1 = lambda epoch: epoch // 30
lambda2 = lambda epoch: 0.95 ** epoch
scheduler = LambdaLR(optimizer, lr_lambda=[lambda1, lambda2])
for epoch in range(100):
train(...)
validate(...)
scheduler.step()3 分类优化目标定义
机器学习用有限训练集上的期望损失作为优化目标(代理损失函数 ),损失代表预测值
),损失代表预测值 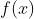 与真实值
与真实值 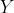 的不一致程度,损失函数越小,一般模型的性能越好。
的不一致程度,损失函数越小,一般模型的性能越好。
观察训练集和测试集的误差就能知道模型的收敛情况,估计模型的性能。
- 分类,预测概率分布
- 回归,预测具体数值
- 稳定平滑
- 适配不平衡样本
- 优化分类界面等
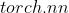 包来构建
包来构建
import torch.optim as optim
criterion = nn.CrossEntropyLoss() #交叉熵损失3.1 NLLLoss优化目标
负的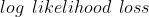 损失,用于训练一个
损失,用于训练一个 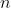 类分类器。
类分类器。
torch.nn.NLLLoss(weight=None, size_average=True)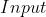 : (
: ( ,
,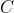 ) , 是类别的个数
) , 是类别的个数 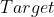 : (),
: (),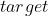 中每个值的大小满足
中每个值的大小满足 
m = nn.LogSoftmax()
loss = nn.NLLLoss()
# input is of size nBatch x nClasses = 3 x 5
input = autograd.Variable(torch.randn(3, 5), requires_grad=True)
# each element in target has to have 0 <= value < nclasses
target = autograd.Variable(torch.LongTensor([1, 0, 4]))
output = loss(m(input), target)
output.backward()3.2 CrossEntropyLoss优化目标
torch.nn.CrossEntropyLoss(weight=None, size_average=True)- : (,) ,是类别的个数
- : (), 是
 的大小,
的大小,
将 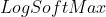 和
和 
3.3 BCELoss优化目标
计算 与 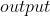 之间的二进制交叉熵
之间的二进制交叉熵
torch.nn.BCELoss(weight=None, size_average=True)- : (,) , 是类别的个数
- Target: (,) , 中每个值的大小满足

3.4 KL散度优化目标:
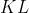 散度常用来描述两个分布的距离,并在输出分布的空间上执行直接回归是有用的。
散度常用来描述两个分布的距离,并在输出分布的空间上执行直接回归是有用的。
torch.nn.KLDivLoss(weight=None, size_average=True)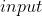 的形状相同
的形状相同
3.5 MSELoss与L1优化目标
torch.nn.MSELoss(size_average=True)torch.nn.L1Loss(size_average=True)torch.nn.SmoothL1Loss(size_average=True)欢迎大家交流评论,一起学习
希望本文能帮助您解决您在这方面遇到的问题
感谢阅读
END
以上是关于「深度学习一遍过」必修11:优化器的高级使用+学习率迭代策略+分类优化目标定义的主要内容,如果未能解决你的问题,请参考以下文章
「深度学习一遍过」必修16:Tensorboard与Transforms
「深度学习一遍过」必修3:Pytorch数据读取——使用Dataloader读取Dataset