「深度学习一遍过」必修26:机器学习与深度学习基础知识汇总
Posted 大展鸿兔
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了「深度学习一遍过」必修26:机器学习与深度学习基础知识汇总相关的知识,希望对你有一定的参考价值。
本专栏用于记录关于深度学习的笔记,不光方便自己复习与查阅,同时也希望能给您解决一些关于深度学习的相关问题,并提供一些微不足道的人工神经网络模型设计思路。
专栏地址:「深度学习一遍过」必修篇
目录
1 Boosting与Bagging
Boosting
- 个体学习器存在强依赖关系
- 串行
- 最著名的的代表
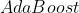
Bagging
- 个体学习器不存在强依赖关系
- 并行
- 一个扩展变体:随机森林
2 卷积层、激活层、池化层作用
- 卷积层:提取特征
- 激活层:进行特征的选择和抑制
- 池化层:降低特征平面分辨率及抽象特征
3 卷积神经网络特性
局部连接
- 思想来自生理学的感受野机制和图像的局部统计特性
权值共享
- 使图像局部学习到的信息可以应用到其他区域,从而使同样的目标在不同的位置能提取到同样的特征
4 正则化相关知识
正则化目的
- 避免过拟合
正则化思路
- 以增大训练集误差为代价来减小泛化误差
正则化方法
- 参数正则化方法:如
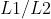 正则化
正则化 - 经验正则化方法:提前停止、模型集成(如
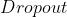 )
) - 隐式正则化方法:数据增强
5 评测指标相关知识
分类评测指标
- 准确率
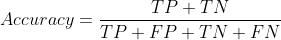
- 精确率
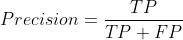
- 召回率
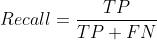
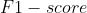

- 混淆矩阵
用于查看是否有特定的类别相互混淆
对于包含多个类别的任务,混淆矩阵很清晰地反映了各类别之间错分的概率
越好的分类器对角线上的值越大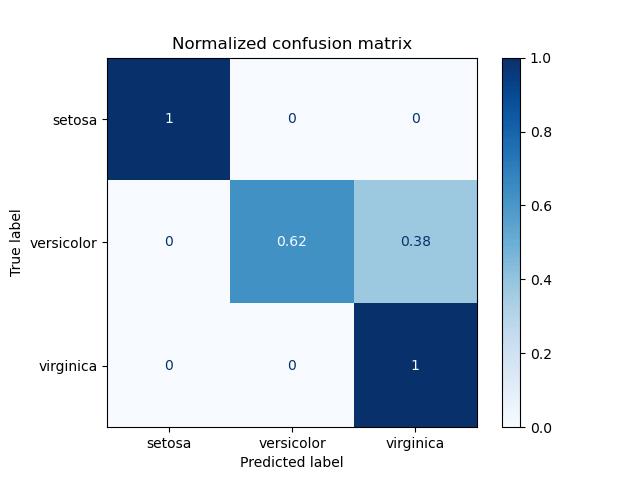
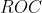 曲线
曲线
用于评价一个分类器在不同阈值下的表现
横坐标: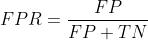
纵坐标: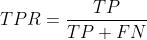
它对正负样本不均衡问题不敏感,所以对于不均衡样本问题常选用 曲线作为评价准则 曲线越靠近左上角,表示该分类器性能越好 
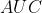 指标
指标
若想通过两条 曲线来定量评估两个分类器的性能,就可以使用 这个指标。 是 曲线下的面积(值不大于 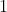 )
)
检索与回归评测指标
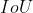 (交并比)
(交并比)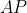
其值等于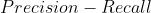 曲线下的面积
曲线下的面积
假设有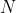 个
个 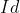 ,其中有
,其中有 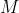 个
个 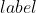 值等于这 个精确率值求平均
值等于这 个精确率值求平均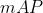
假设有 个 ,其中有 个 值等于 个类别的 值求平均
图像生成指标
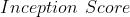
同时评估了生成图像的质量和多样性
仅评估图像生成模型,没有评估生成图像与原始图像之间的相似度,不能保证生成的使我们想要的图像分数对其进行了改进,增加了
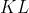 散度来度量真实分布于生成分布之间的差异
散度来度量真实分布于生成分布之间的差异
最大平均差异

6 参数初始化方法
要满足的条件
- 各层激活值不会出现饱和现象
- 各层激活值不为
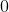
神经网络要求
- 参数梯度应该保持非零
常见问题
- 初始值太小:导致反向传播梯度太小、梯度弥散。降低收敛速度
- 初始值太大:造成振荡,会使
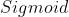 函数等进入梯度饱和区
函数等进入梯度饱和区
参数初始化方法
- 初始化为 :中间层节点值都为零,不利于优化。训练逻辑回归等模型才用
- 生成小的随机数:
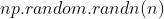
- 标准初始化:权重参数从
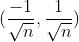 的均匀分布中生成
的均匀分布中生成
保持神经网络每层权重方差与层数无关,会更加有利于优化 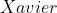 初始化:基于
初始化:基于 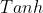 函数提出的,对
函数提出的,对 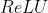 并不友好(虽常搭配使用)
并不友好(虽常搭配使用)
网络越深,各层输入的方差就越小,网络越难训练初始化:基于
函数提出的
7 归一化相关知识
归一化目的
- 让每层输入和输出的分布比较一致,从而降低学习难度
Batch Normalization(BN)
- 用在卷积层后,用于重新调整数据分布
- 方式:求均值
 求方差 归一化 尺度缩放和偏移操作
求方差 归一化 尺度缩放和偏移操作 - 具体方法:
输入数据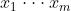 (这些数据是准备进入激活函数的数据)
(这些数据是准备进入激活函数的数据)
计算过程中可以看到:
1、求数据均值
2、求数据方差
3、数据进行标准化
4、训练参数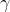 、
、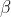
5、输出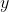 通过 与 的线性变换得到新的值
通过 与 的线性变换得到新的值
在正向传播的时候,通过可学习的γ与β参数求出新的分布值
在反向传播的时候,通过链式求导方式,求出γ与β以及相关权值
- 让每一层的输出归一化到了均值为 ,方差为 的分布
- 好处:①减轻了对初始值的依赖
②训练更快,可以使用更高的学习速率 - 缺陷:依赖于
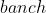 , 很小时计算的均值和方差不稳定
, 很小时计算的均值和方差不稳定
补充: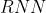 使得 有长有短,因此也不适用此归一化方法
使得 有长有短,因此也不适用此归一化方法
8 最优化方法相关知识
8.1 一阶
批量梯度下降
- 使用所有的训练样本计算梯度,梯度计算稳定,但计算非常慢
随机梯度下降(SGD)
- 每次只取一个样本进行梯度计算,梯度计算不稳定易振荡,但整体趋近于全局最优解
- 解决
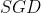 有时很慢的方法:引入动量项(对在梯度点处具有相同方向的维度,增大其动量项;对在梯度点处改变方向的维度,减小其动量项)
有时很慢的方法:引入动量项(对在梯度点处具有相同方向的维度,增大其动量项;对在梯度点处改变方向的维度,减小其动量项) - 上述方法对所有参数使用了同一个更新速率,但同一个更新速率并不一定适合所有参数(有的参数已经到了仅需微调的阶段,而有些参数由于对应样本少等原因,还需要较大幅度的调整)
- 解决办法见下
AdaGrad
- 自适应地为各个参数分配不同的学习率
- 存在问题:学习率单调递减,训练后期学习率非常小,且需手动设置一个全局的出示学习率
Adadelta
- 可有效解决
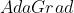 的问题,本质是 算法的扩展,同样是对学习率的自适应约束,不依赖全局学习率,训练初、中期效果理想,训练后期反复在局部最小值附近抖动。
的问题,本质是 算法的扩展,同样是对学习率的自适应约束,不依赖全局学习率,训练初、中期效果理想,训练后期反复在局部最小值附近抖动。 - 算法会累加之前所有的梯度平方,
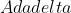 算法只累加固定大小的项,并且仅存储这些项近似计算对应的平均值
算法只累加固定大小的项,并且仅存储这些项近似计算对应的平均值
RMSProp
- 可以看做 的一个特例,依然依赖全局学习率,效果位于 与 之间,适合处理非平稳目标,适用于 的优化
Adam
- 本质是带有动量项的
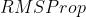 算法,利用梯度的一阶矩估计和二阶矩估计动态调整没和参数的学习率,迭代到后期时,学习率不稳定,可能过大或过小
算法,利用梯度的一阶矩估计和二阶矩估计动态调整没和参数的学习率,迭代到后期时,学习率不稳定,可能过大或过小 - 优点主要在于经过偏置校正后,每次迭代学习率都有一个确定的范围,使得参数比较平稳,对内存需求较小,适用于大多数非凸优化问题,尤其适合处理大数据集和高维空间问题
8.2 二阶
牛顿法
- 有较一阶梯度优化方法更快的收敛速度,但计算量大
拟牛顿法
- 可简化运算的复杂度
9 激活函数相关知识
Sigmoid 函数
(注: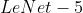 :激活函数 )
:激活函数 )
- 缺陷:
- 两端是饱和区,饱和区内梯度接近于 ,会带来梯度消失问题;随着网络层数增加,由于链式法则,连乘的 函数导数也越来越小,导致梯度难以回传,降低网络收敛速度,甚至不能收敛
- 输出并不以 为中心,总是大于 ,而权重参数的梯度与输入有关,这就会造成在反向传播时,一个样本的某个权重的梯度总是同一个符号,这不利于权重的更新
Tanh函数
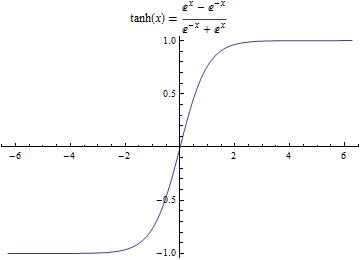
- 解决了 输出值并不以 为中心的问题,但梯度消失问题和幂运算问题仍然存在
线性ReLU函数
(注: :激活函数 )
:激活函数 )
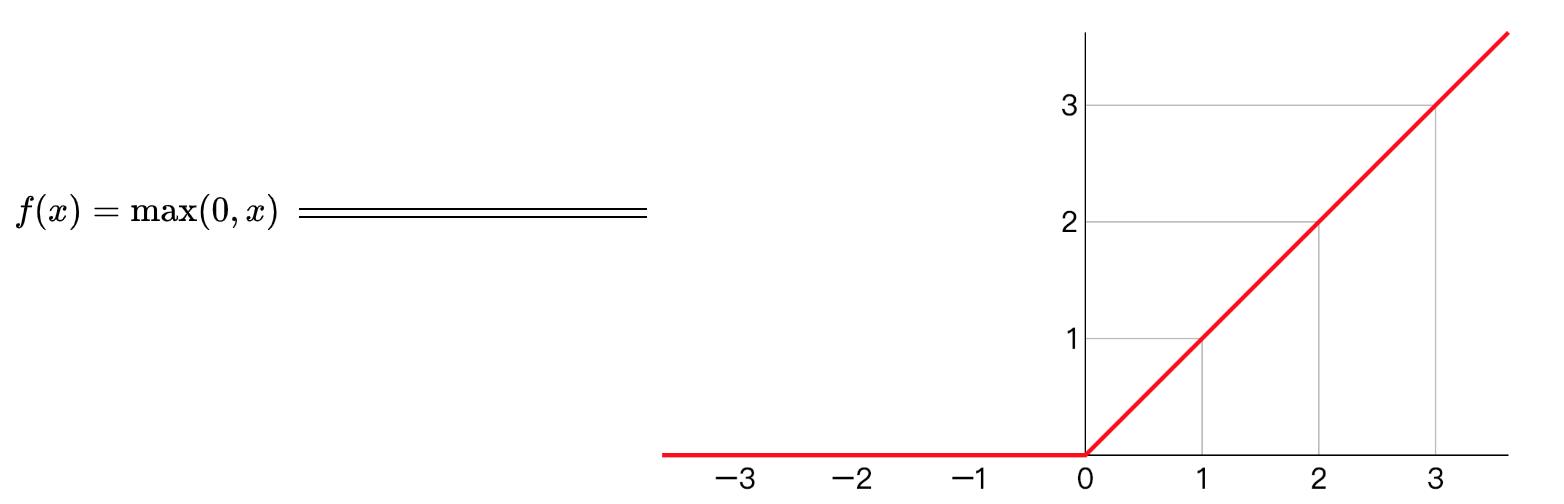
- 若用 函数表示则同时有一半神经元被激活,这不符合生物学只有
 被激活的要求,因此需要新的具有稀疏性的激活函数来学习相对稀疏的特征
被激活的要求,因此需要新的具有稀疏性的激活函数来学习相对稀疏的特征 - 优点:
 在使用时只需要判断输入是否大于 ,所以其计算速度非常快,收敛速度远快于 和 函数
在使用时只需要判断输入是否大于 ,所以其计算速度非常快,收敛速度远快于 和 函数 - 缺点:存在
 问题,即某些神经元可能永远不会参与计算,导致其相应的参数无法被更新
问题,即某些神经元可能永远不会参与计算,导致其相应的参数无法被更新
Leaky ReLU函数
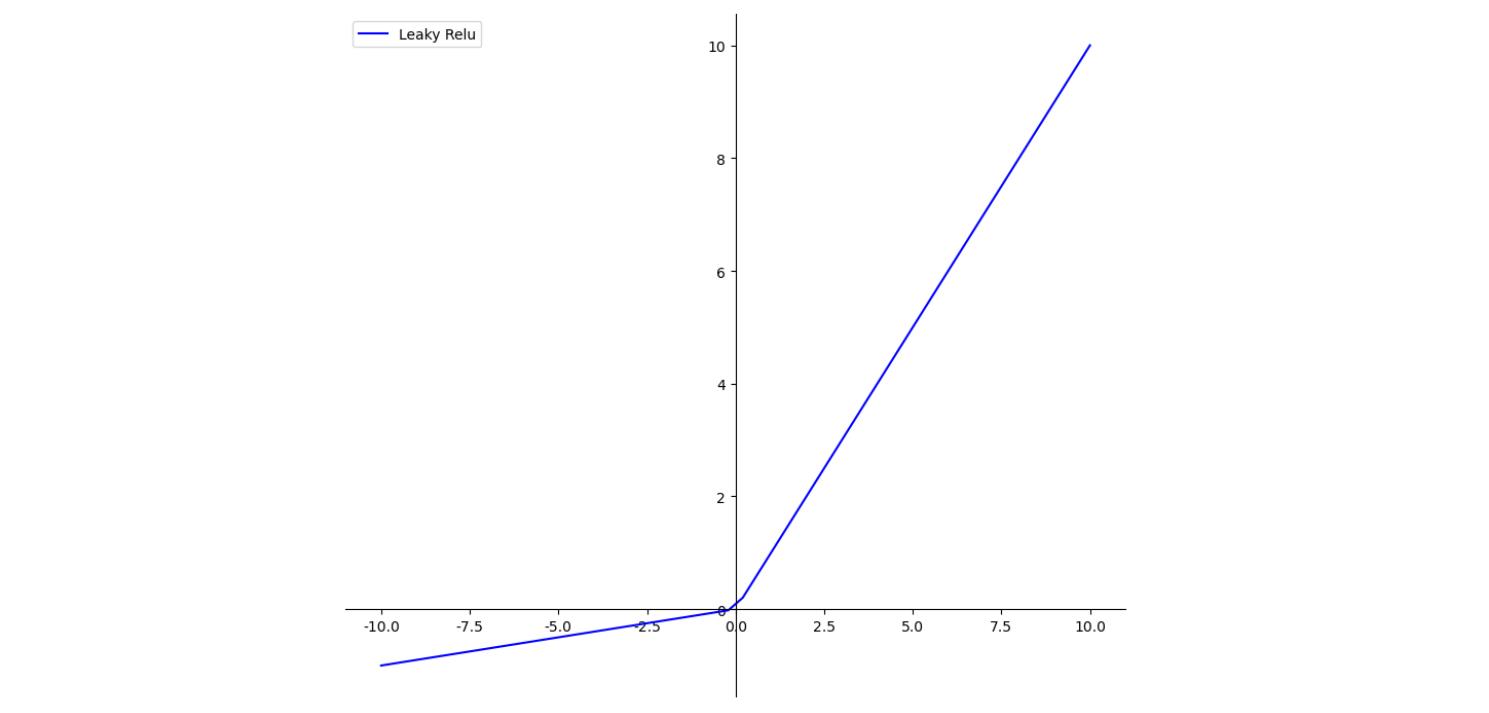
- 其提出是为了解决 问题,从理论上来讲,
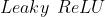 具有 的所有优点,并且不会有 问题,但实际操作并没有完全证明 函数总是好于 函数
具有 的所有优点,并且不会有 问题,但实际操作并没有完全证明 函数总是好于 函数
Maxout函数
- 就是最大值函数,从多个输入中取最大值,其具有 函数的所有优点,线性、不饱和性,同时没有 函数的缺点。其拟合能力非常强,可以拟合任意的凸函数,实验结果表明,
函数与
组合使用可以发挥比较好的效果
Softmax函数
- 公式
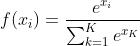
- 可视为 函数的泛化形式,该函数一般用于多分类神经网络输出,待补充……
10 优化目标相关知识
- 损失函数越小,模型的鲁棒性越好
10.1 分类任务损失
0-1损失
- 当标签与预测类别相等时,损失为 ,否则为
 损失无法对
损失无法对 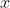 进行求导,这使其在依赖反向传播的深度学习模型中无法被优化
进行求导,这使其在依赖反向传播的深度学习模型中无法被优化
交叉熵损失
- 交叉熵函数是两个分布的互信息,可以反映两个概率分布的相关程度
- 损失的大小完全取决于分类为正确标签那一类的概率,当所有样本都分类正确时,损失为 ,否则,损失大于
Softmax损失
- 是交叉熵损失的特例(
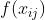 的表现形式为
的表现形式为 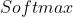 ),常应用于分类分割任务
),常应用于分类分割任务
KL散度
- 用于估计两个分布的相似性, 散度并不是一个对称的损失,常被用于生成式模型
Sigmoid Cross Entropy损失
- 通常被用于多分类任务
10.2 回归任务损失
- 回归结果是整数或实数,并没有先验的概率密度分布,其常用的损失是
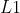 损失和
损失和 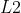 损失
损失
L1损失
- 公式

- 以绝对误差作为距离,具有稀疏性,常被作为正则项添加到其他损失中来约束参数的稀疏性, 损失最大的问题是梯度在零点不平滑
L2损失
- 公式

- 以绝对误差的平方和作为距离, 损失也常常作为正则项,当预测值与目标值相差很大时,梯度容易爆炸,因为梯度中包含了预测值和目标值的差异项, 损失最大的问题是梯度容易爆炸
Smooth L1损失
- 公式
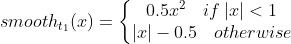
- 解决
 梯度不平滑, 梯度爆炸问题
梯度不平滑, 梯度爆炸问题 - 在 比较小时,上式等价于 ,保持平滑
- 在 比较大时,上式等价于 ,可以限制数值的大小
问答环节
- 问:神经网络的初始权值和阈值为什么都归一化 到 之间呢?(分割归一化到
 )
)
答:因为神经元的传输函数在 之间区别比较大,如果大于 以后,传输函数值变化不大(导数或斜率就比较小),不利于反向传播算法的执行。反向传播算法需要用到各个神经元传输函数的梯度信息,当神经元的输入太大时(大于 比如),相应的该点自变量梯度值就过小,就无法顺利实现权值和阈值的调整)。传输函数比如
之间区别比较大,如果大于 以后,传输函数值变化不大(导数或斜率就比较小),不利于反向传播算法的执行。反向传播算法需要用到各个神经元传输函数的梯度信息,当神经元的输入太大时(大于 比如),相应的该点自变量梯度值就过小,就无法顺利实现权值和阈值的调整)。传输函数比如  或
或 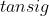 ,若把函数图像画出来会发现,
,若把函数图像画出来会发现,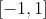 之间函数图像比较徒,一阶导数(梯度)比较大,如果在这个范围之外,图像就比较平坦,一阶导数(梯度)就接近 了。
之间函数图像比较徒,一阶导数(梯度)比较大,如果在这个范围之外,图像就比较平坦,一阶导数(梯度)就接近 了。
欢迎大家交流评论,一起学习
希望本文能帮助您解决您在这方面遇到的问题
感谢阅读
END
以上是关于「深度学习一遍过」必修26:机器学习与深度学习基础知识汇总的主要内容,如果未能解决你的问题,请参考以下文章