个性化联邦学习算法框架发布,赋能AI药物研发
Posted 华为云
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了个性化联邦学习算法框架发布,赋能AI药物研发相关的知识,希望对你有一定的参考价值。
摘要:近期,中科院上海药物所、上海科技大学联合华为云医疗智能体团队,在Science China Life Sciences 发表题为“Facing Small and Biased Data Dilemma in Drug Discovery with Enhanced Federated Learning Approaches”的文章。
本文分享自华为云社区《中科院上海药物所/上海科技大学、华为云联合团队发布个性化联邦学习算法框架,赋能AI药物研发》,作者: 华为云头条 。
文章来源:中国科学杂志社
药物研发是一个漫长的过程,传统的药物研发需要投入大量的研发人员,并且花费十到十五年,数十亿美元的研发经费才能使一个药物走向上市。近些年来,随着AI、大数据和云计算等技术的发展,越来越多的制药公司和科技巨头把目光投到这一领域。然而AI药物研发面临着一系列困难和挑战,AI模型需要大量的数据进行建模,而药物研发数据的高壁垒、高成本、高机密性影响到了制药公司数据贡献的积极性。同时,数据孤岛现象普遍存在,很多企业内部的数据都是量少而且高度有偏的,这给高质量的AI药物研发模型带来很大的挑战。近年来新兴的联邦学习可以很好的解决这个问题。联邦学习本质上是一种分布式机器学习技术,其目标是在保证数据隐私安全合规的基础上,实现共同建模。在联邦学习框架下,多家药企之间无需共享数据,仅通过共享模型权重,来实现药企之间协同训练,在保证数据安全的同时彼此增强AI模型的效果。

近期,中科院上海药物所、上海科技大学联合华为云医疗智能体团队,在Science China Life Sciences 发表题为“Facing Small and Biased Data Dilemma in Drug Discovery with Enhanced Federated Learning Approaches”的文章。联合团队使用三个任务来模拟跨数据孤岛的联合学习过程:基于化学结构进行药物溶解度、激酶抑制活性和hERG心脏毒性的预测。这些数据涵盖了不同的药物化学空间、实验测量方法、实验条件和数据大小,代表真实世界中不同制药公司的数据分布的差异。借此,来研究联邦学习对打破数据孤岛的意义,并从分析结果中发现,联邦学习的效果均优于单独数据来源的模型训练。
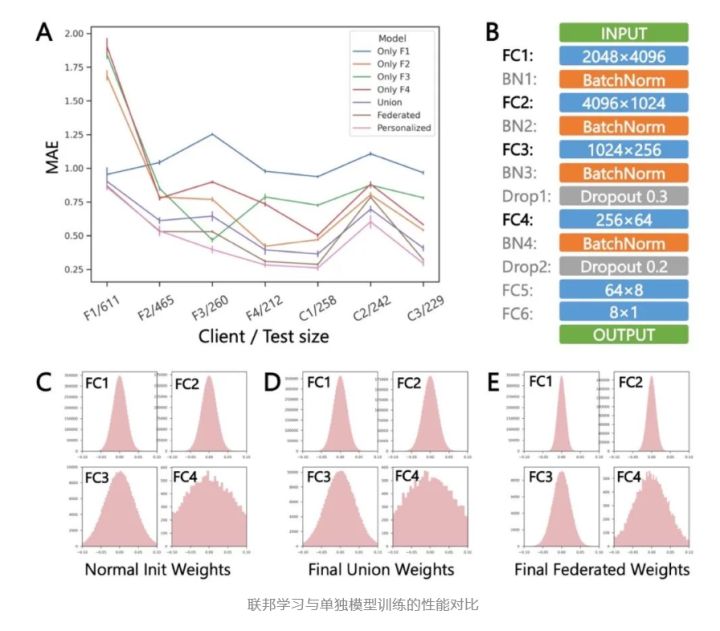
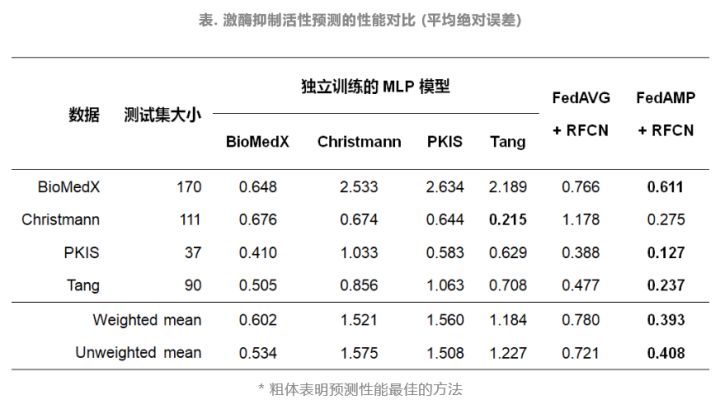
接着,为进一步提升模型效果,联合团队引入了残差全连接网络(RFCN),通过利用AI自动建模工具AutoGenome1,对三个任务重新训练以获得更精确的模型骨架;另外,在联邦模型参数整合策略中联合团队引入了个性化联邦学习(FedAMP)2,为联邦计算参与者训练个性化模型,并且通过注意力消息传递机制加强具有相似数据分布的参与者之间的协同,使得数据贡献越多、质量越好的参与方获益也越大;在激酶抑制活性预测的性能对比我们可以看到,RFCN和FedAMP的引入,在药物溶解度、激酶抑制活性和hERG心脏毒性预测这三个AI任务上,均优于传统MLP和FedAvg方法。
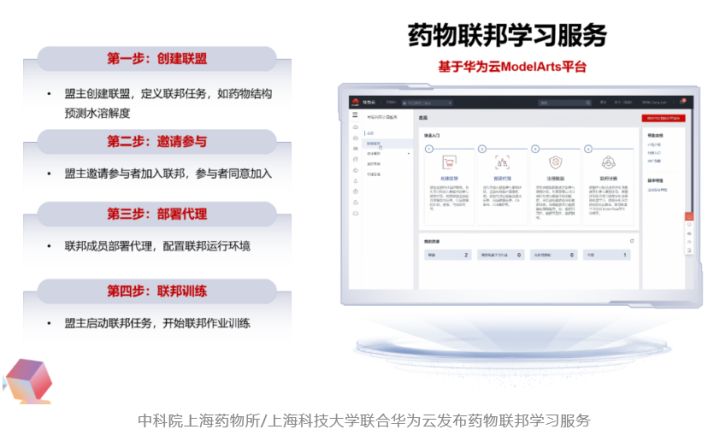
近日,上海药物所/上海科技大学和华为云医疗智能体,联合发布基于华为云ModelArts平台的药物联邦学习服务,来帮助药企和研究机构更加方便的使用药物联邦学习,通过简单的四步操作,参与联邦学习的用户就可以便捷的实现联邦训练:第一步:盟主创建联盟,定义联邦任务,如药物结构预测水溶解度;第二步:盟主邀请参与者加入联邦,参与者同意加入;第三步:联邦成员部署代理,配置联邦运行环境;第四步:盟主启动联邦任务,开始联邦作业训练。
华为云医疗智能体EIHealth基于华为云AI昇腾集群服务、华为云一站式AI开发平台ModelArts的强大AI能力,集成了医药领域众多算法、工具、AI模型和自动化流水线,目标是打造一个全栈、开放、专业的医疗行业企业级AI研发平台。 更多信息请访问 : https://www.huaweicloud.com/product/eihealth.html
参考文献
1. Liu, D. et al. AutoGenome: An AutoML Tool for Genomic Research. bioRxiv 842526 (2019) doi:10.1101/842526.2. Huang, Y. et al. Personalized Cross-Silo Federated Learning on Non-IID Data. arXiv:2007.03797 [cs, stat] (2021).
以上是关于个性化联邦学习算法框架发布,赋能AI药物研发的主要内容,如果未能解决你的问题,请参考以下文章