强化学习笔记5:learning&planning, exploration&exploitation
Posted 刘文巾
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了强化学习笔记5:learning&planning, exploration&exploitation相关的知识,希望对你有一定的参考价值。
1 learning & planning
Learning 和 Planning 是序列决策的两个基本问题。
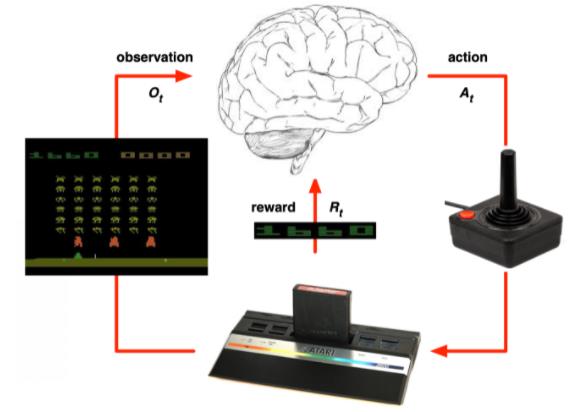
在强化学习中,环境初始时是未知的,agent 不知道环境如何工作,agent 通过不断地与环境交互,逐渐改进策略。(learning过程)
在 plannning 中,环境是已知的,我们被告知了整个环境的运作规则的详细信息。
Agent 能够计算出一个完美的模型,并且在不需要与环境进行任何交互的时候进行计算。
Agent 不需要实时地与环境交互就能知道未来环境,只需要知道当前的状态,就能够开始思考,来寻找最优解。
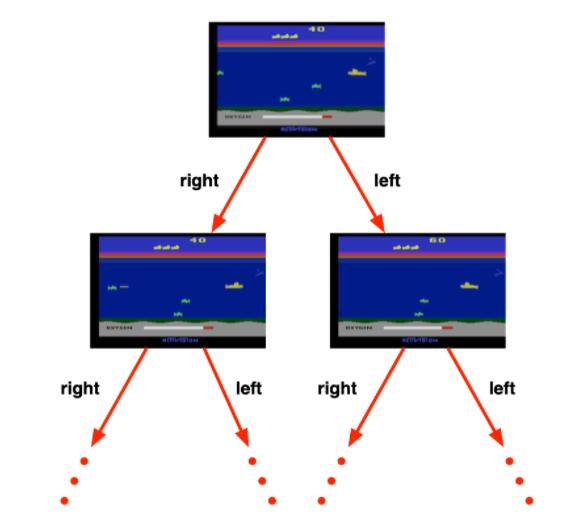
在上图这个游戏中,规则是制定的,我们知道选择 left或者right 之后环境将会产生什么变化。我们完全可以通过已知的变化规则,来在内部进行模拟整个决策过程,无需与环境交互。
一个常用的强化学习问题解决思路是,先学习环境如何工作,也就是了解环境工作的方式,即学习得到一个模型,然后利用这个模型进行规划。
2 exploration& exploitation
在强化学习里面,探索exploration 和利用exploitation 也是两个很核心的问题。
-
探索exploration是说我们怎么去探索这个环境,通过尝试不同的行为来得到一个最佳的策略,得到最大奖励的策略。
-
利用exploitation是说我们不去尝试新的东西,就采取已知的可以得到很大奖励的行为。
因为在刚开始的时候强化学习 agent 不知道它采取了某个行为会发生什么,所以它只能通过试错去探索。
所以探索exploration就是通过试错来理解采取的这个行为到底可不可以得到好的奖励。
利用exploitation是说我们直接采取已知的可以得到很好奖励的行为。
这里就面临一个权衡,怎么通过牺牲一些短期的奖励来获得行为的理解,从而学习到更好的策略。
2.1 探索和利用的例子:
| 餐馆 |
|
| 做广告 |
|
| 挖油 |
|
| 玩游戏 |
|
3 K-armed Bandit
与监督学习不同,强化学习任务的最终奖赏是在多步动作之后才能观察到。
这里我们不妨先考虑比较简单的情形:最大化单步奖赏,即仅考虑一步操作。
需注意的是,即便在这样的简化情形下,强化学习仍与监督学习有显著不同,因为机器需通过尝试来发现各个动作产生的结果,而没有训练数据告诉机器应当做哪个动作。
想要最大化单步奖赏需考虑两个方面:一是需知道每个动作带来的奖赏,二是要执行奖赏最大的动作。
若每个动作对应的奖赏是一个确定值,那么尝试遍所有的动作便能找出奖赏最大的动作。然而,更一般的情形是,一个动作的奖赏值是来自于一个概率分布,仅通过一次尝试并不能确切地获得平均奖赏值。
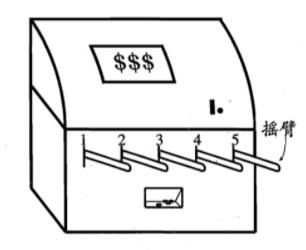
实际上,单步强化学习任务对应了一个理论模型,即 K-臂赌博机(K-armed bandit)。
K-臂赌博机也被称为 多臂赌博机(Multi-armed bandit) 。如上图所示,K-摇臂赌博机有 K 个摇臂,赌徒在投入一个硬币后可选择按下其中一个摇臂,每个摇臂以一定的概率吐出硬币,但这个概率赌徒并不知道。赌徒的目标是通过一定的策略最大化自己的奖赏,即获得最多的硬币。
-
若赌徒仅为获知每个摇臂的期望奖赏,则可采用
仅探索(exploration-only)法:将所有的尝试机会平均分配给每个摇臂(即轮流按下每个摇臂),最后以每个摇臂各自的平均吐币概率作为其奖赏期望的近似估计。 -
若赌徒仅为执行奖赏最大的动作,则可采用
仅利用(exploitation-only)法:按下目前最优的(即到目前为止平均奖赏最大的)摇臂,若有多个摇臂同为最优,则从中随机选取一个。
显然,仅探索法能很好地估计每个摇臂的奖赏,却会失去很多选择最优摇臂的机会;仅利用法则相反,它没有很好地估计摇臂期望奖赏,很可能经常选不到最优摇臂。
因此,这两种方法都难以使最终的累积奖赏最大化。
事实上,探索(即估计摇臂的优劣)和利用(即选择当前最优摇臂)这两者是矛盾的,因为尝试次数(即总投币数)有限,加强了一方则会自然削弱另一方,这就是强化学习所面临的探索-利用窘境(Exploration-Exploitation dilemma)。
显然,想要累积奖赏最大,则必须在探索与利用之间达成较好的折中。
以上是关于强化学习笔记5:learning&planning, exploration&exploitation的主要内容,如果未能解决你的问题,请参考以下文章
CS294-112 深度强化学习 秋季学期(伯克利)NO.21 Guest lecture: Aviv Tamar (Combining Reinforcement Learning and Plan
机器学习应用——强化学习&课程总结 实例 “自主学习Flappy Bird游戏”(MDP&蒙特卡洛强化学习&Q-learning&DRL&DQN)