长文预警!吐血总结2万字Java容器,再也不怕面试官刨根问底了。
Posted 洛 神
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了长文预警!吐血总结2万字Java容器,再也不怕面试官刨根问底了。相关的知识,希望对你有一定的参考价值。
人世仙家本自殊,何须相见向中途。惊鸿瞥过游龙去,漫恼陈王一事无。
嗨,大家好,我是洛神,性别男。一个来自快乐星球的程序员。
欢迎大家专注我的公众号【程序员洛神】,不仅分享技术,还会分享生活趣事、体育。
前言
失踪人口回归啦!!!俺也不是故意失踪这么久的,这一个多月事儿太多啦,实在是处理不过来才停更了,希望各位见谅。后面我会正常恢复更新的,嘤嘤嘤。

引言
数组为我们提供了一种存储对象的方式,然而,很显然数组在动态增减、空间利用率等方面有缺陷。所以,我们需要一种能够满足动态增减的存储方式。
数组:
int[] args = new int[10];
数组每次扩容需要创建一个比原数组更大的新的数组,然后将原数组的值依次放入。
餐前甜点:
容器家族族谱:

根据上图我们可以看到,Java容器分为两类,Collection和Map
Collection
一个独立元素的序列,这些元素都服从一条或多条规则。其中List必须按照插入的顺序保存元素(List的有序并不是指内部自动排序,而是保证插入的顺序和存储的顺序一致)。Set不能有重复的元素(可以利用这个特性对集合进行去重->HashSet set = new HashSet(list);) Queue按照排队规则来确定对象的产生顺序(FIFO(先进先出) 栈(FILO 先进后出))
(关于队列、栈引申出堆、栈、队列 内存中(堆(公共)、栈(私有栈)) 数据结构中(栈、队列)) https://www.cnblogs.com/guoxiaoyan/p/8664150.html
Map
一组成对的键值对(key-value),允许用键来查找值。(可以理解为一本字典 key就是目录 通过hash+散列法取余获取下标(字典页数))
正文开始
List
List承诺可以将元素维护在特定的序列中。List接口在Collection的基础上加入了大量的方法,使得可以在集合中任意位置插入和移除元素。
ArrayList
特点
随机访问元素快(就是查询的时候快的很) 但是插入和移除比较慢。
题外话:为什么说ArrayList是随机访问的?

重点看介个RandomAccess接口 它为操作类提供了随机快速访问的能力
来让我们看一下RandomAccess接口的官方注释:

总结一句话:你实现我,你查询起来就快的一批。
为啥访问访问快?
因为ArrayList底层是数组
证据:

数组是紧凑连续存储的,可以随机访问,通过数组在内存中的起始位置以及下标来快速查找对应元素。时间复杂度是O(1)

多维数组也是一样的:(arr[0][1])
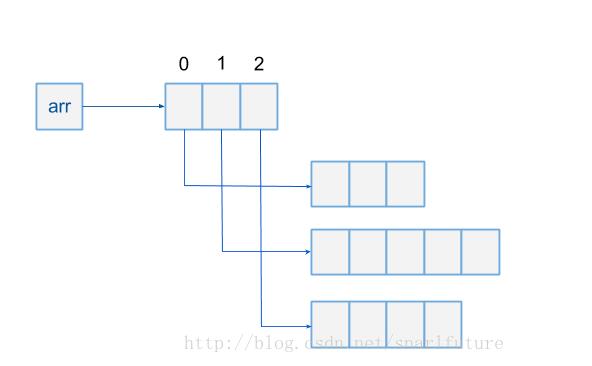
那他为什么插入和删除很慢嘞?
成也连续,败也连续,正是因为数组在内存中是连续的,所以一开始就需要分配好空间的(新建数组的时候必须分配大小,不分配默认10)
这也就意味着,如果超过了既定数组长度,那么我就需要重新建立一个比原数组更大的数组来存放以前的数据和以后的数据,这个操作过程的时间复杂度是O(N)。而且如果你想在数组中间插入或者删除数据,那么你每次必须将操作的元素后面所有的元素都整体挪动,以此保证元素永远连续,这个操作的时间复杂度也是O(N)。

ArrayList实际使用:
//默认长度是10 每次扩容为原数组的1.5倍
ArrayList<String> list1 = new ArrayList<String>( );
list1.add("我");
list1.add("秦始皇");
list1.add("打钱!!");
list1.forEach(System.out::println);
//获取集合中的n个元素
System.out.println(list1.get(0));
//获取集合大小
System.out.println(list1.size());
//截取集合元素 下标从0开始 到1结束(不包括1)
List<String> newList1 = list1.subList(0, 1);
newList1.forEach(System.out::println);
//数组转换为ArrayList
String[] strArr = new String[10];
strArr[0] = "拿来吧你";
java.util.List<String> strs = Arrays.asList(strArr);
strs.forEach(System.out::println);
LinkedList
LinkedList底层是基于链表的。
先上证据,免得你觉得我在骗你:

Node作为每个链表的节点,里面会有一个next指向下一个链表。prev指向前一个链表。
特点
查询速度慢,增删改速度快。
它为什么查询数据很慢嘞?
在内存中不连续,所以无法随机访问,每次查询元素需要遍历链表查询,时间复杂度为O(n)。
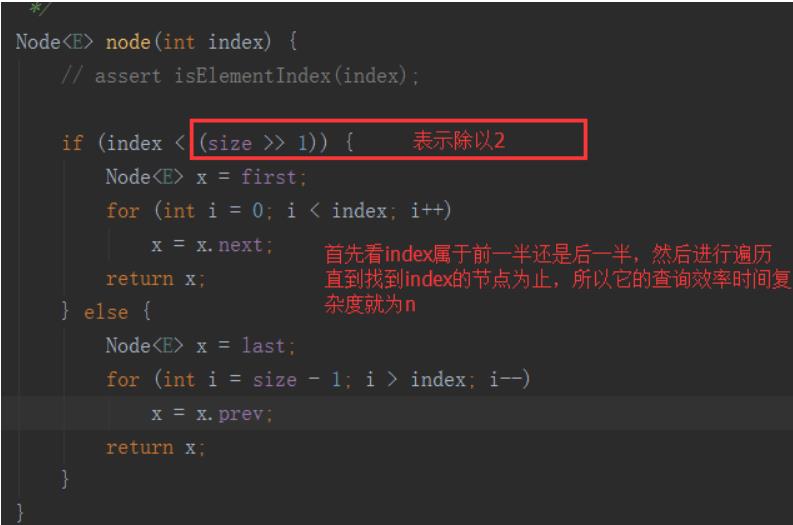
为什么增删改速度快嘞?
也正是因为它是不连续的,所以每个元素需要依靠指针指向下一个元素的地址,所以不存在数组的类似扩容问题,每次新增或删除操作只需要将操作位置的前后元素进行拆开后插入或移除即可。时间复杂度是O(1)。但是也是由于不连续的,,而且由于每个元素都要存放前后元素位置的指针(前驱节点和后驱节点),所以会消耗额外的存储空间。
LinkedList和ArrayList的API基本上是一致的,区别就是根据不同的业务场景来挑选使用不同的集合。
Vector
vector主要实现了一个动态数组。和上面我们说到的ArrayList很相似,但是两者是不同的。
最大的不同点,就是Vector是同步访问的,也就是说vector是绝对线程安全的。
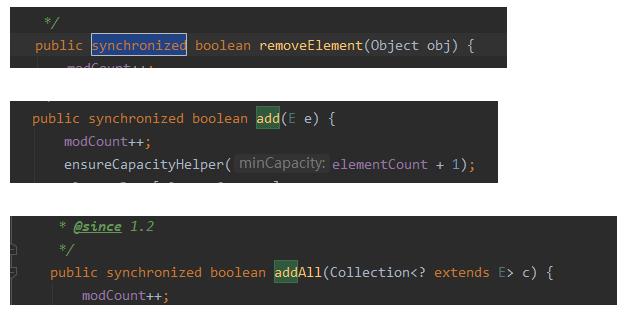
几乎所有的方法都加了synchronized锁,而且锁的整个方法哟。当然安全。
但是,众所周知,锁方法是很危险的,尤其是在并发量较大的情况下。会造成严重的延迟响应。所以Vector平时开发中我们使用的是比较少的(可能只是我用的少,小丑竟是我自己!)
Set集合
Set集合的人生格言:哥注定就是要跟别人不一样!
为啥这么说呢,因为Set集合的特性就是比较特殊的:
1.不存储重复的元素。
2.存进去的值的顺序是无法保证的。
大家先知道下这个特性,下面讲HashSet的时候我会带大家实战。
HashSet:我来了兄dei!
唉WC,说曹操曹操就到,HashSet底层其实是使用HashMap来存放值的,也就是使用哈希表,当我add()一个元素的时候,其实是将元素作为map的key存储,value默认是一个固定的Object。
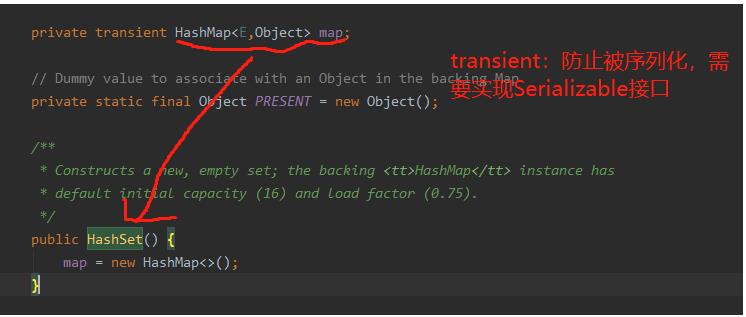
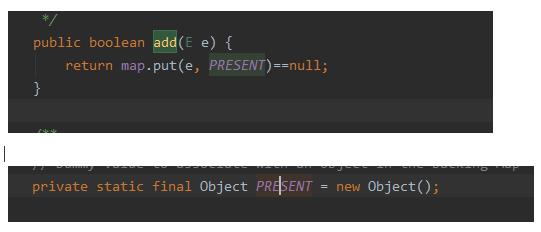
当add元素的时候,会计算待插入元素的hashCode值,将元素插入到对hash表中对应的位置。
特点
除了Set集合的无序和不可重复外,还具有:
1.允许插入null值,也就是允许key为null。
2.线程不安全,如果两个线程同时操作这个HashSet,必须通过代码实现同步(考虑线程安全,目前用的比较多的是ConcurrentHashMap,后面详细介绍)
话不多说,咱们直接刚代码
HashSet<Integer> sets1 = new HashSet<>();
sets1.add(1);
sets1.add(1);
sets1.add(1);
sets1.add(1);
sets1.add(6);
sets1.add(7);
sets1.forEach(System.out::println);
输出结果:

呐,看到了吧,刚才说过,HashSet的底层基于HashMap的,map的特性就是key不重复,相同的会被覆盖(当然,只是我们感觉的重复了,如果出现了Hash冲突而且两个元素equals不相等的时候,就会将重复的值放到同一位置的链表中。。。。JDK8以后链表长度大于8又会退化成红黑树。。。 我们后面仔细说)
知识点扩充
Object的hashCode()和equals()方法:
这两个方法的作用其实是一致的,都是用来比较两个对象是否相同的,但是hashCode()是没有equals()可靠的,因为hashCode()相等,两个对象不一定是一样的,也就是说equals()比较不一定为true,而equals()比较后相等,那么他们的hashCode()结果也一定相等,那么问题来了:
既然equals()方法比hashCode()可靠,为什么还要使用hashCode()呢?
答案:为了效率,hashCode()的执行效率是比equals()高的,所以通常都会先使用hashCode()来比较,如果hashCode()都不相同,那么这两个对象一定就不相同,直接返回false,如果hashCode()结果为true,再去调用equals()方法比较,结果还是true的话就代表这俩对象确实是相同的。这种方法常用在hash容器中。
好了,回到正题,继续我们的测试:
HashSet<String> sets = new HashSet<>();
sets.add("我");
sets.add("秦始皇");
sets.add("打钱!!!");
sets.add("不给?");
sets.add("拿来吧你!!!!");
sets.forEach(System.out::println);
输出结果:
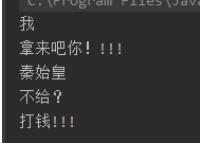
看到了吧,我add进去的顺序和输出的顺序是不一样的,这就叫无序。
你以为这就结束了?来,给你看个神奇的现象
同样的,我是用hashSet来存放值。
HashSet<Integer> sets1 = new HashSet<>();
sets1.add(1);
sets1.add(2);
sets1.add(3);
sets1.add(4);
sets1.add(5);
sets1.add(6);
sets1.add(7);
sets1.forEach(System.out::println);
输出结果:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pZcb46I2-1627631753514)(C:/Users/DD-28/AppData/Roaming/Typora/typora-user-images/image-20210730134908684.png)]
结果每次输出都是有序的,都是按照我add进去的顺序输出的,完了,它变了,变得陌生了~~~
这是为什么呢? 原因的话就得从盘古开天辟地解释开始解释了。
上面我们已经讲过了,HashSet的add()方法底层是调用了HashMap的put()方法,那么,我们来看下put()方法

如图所示,return值之前有一个hash(key)的操作,这个就是对key值进行hash计算,来,我们继续点进去。

int n = tab.length;
// 将(tab.length - 1) 与 hash值进行&运算
int index = (n - 1) & hash;
首先我们来分析一下:
hashCode是Object类中的一个方法,在子类中一般都会重写,而根据我们之前自己给出的程序,暂以Integer类型为例,我们来看一下Integer中hashCode方法的源码:
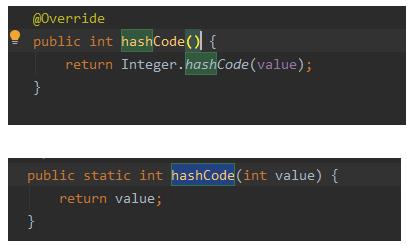
我们可以看到,Integer类的hashCode返回的hashCode是这个数本身。
那么上面的 (h = key.hashCode()) ^ (h>>>16) 就可以化简为 key ^ key>>>16,我们可以看到基于key的hash结果又进行了16位的高位运算以及两者的异或计算,这个操作其实就是所谓的扰动函数,归根结底就是为了降低hash冲突的概率。

hash&(table.length-1)这一步是取模计算得到最终存放再Node中的下标值,为什么要这样子呢?
因为如果使用之前的hash值,我们可以看到转换成十进制之后,数字是很大的,总不能把一个数组扩容到几千万的大小吧。
好了,讲到这里就行了,适可而止,再深入的话一篇文章讨论不过来了,回到最初的问题上,就很容易解释清楚为什么1 2 3 4 5 6 都是有序的了,其实hashSet本身只是保证不一定有序,不保证一定无序,根本原因就在于add的时候(也就是map put的时候)的位置计算的原因。其实也是恰巧我们使用了Integer,Integer重写了hashcode方法,使得它的hashCode就是它本身,然后最终计算的下标结果也是它本身了,所以在插入的时候其实已经排好序了(元素下标位置有序)。
同样的,我们再来观察一组示例:
HashSet<Integer> sets1 = new HashSet<>();
sets1.add(1);
sets1.add(10);
sets1.add(11);
sets1.add(18);
sets1.forEach(System.out::println);
猜猜输出结果是什么?

如果我没有讲上面关于map put操作原理的话,你可能会一脸懵逼,但是,现在,你可以把18带入计算公式自己推演一边,你会发现最终18计算出的下标是2,所以,它就出现在了一个莫名其妙的地方。
LinkedHashSet
LinkedHashSet是HashSet的一个子类,它底层其实是维护了一个LinkedHashMap,所有的操作也是通过这个LinkedHashMap来操作的,LinkedHashMap的底层维护了一个hash表和一个双向链表。每个插入的元素节点都有一个before和after属性。

实战:
LinkedHashSet<Integer> sets = new LinkedHashSet<>();
sets.add(1);
sets.add(12);
sets.add(15);
sets.add(14);
sets.add(12);
sets.forEach(System.out::println);
输出结果:

我们可以到,输出结果是有序的,按照输入顺序输出出来了。这就是它跟HashSet最大的区别。
它能保证有序的最大功臣,就是底层维护的双向链表了,当我们add()元素的时候(对于LinedHashMap来说就是put操作),会先计算元素的hash值,然后计算出它的索引,确定在元素中的位置,然后将元素put到hash表中,这是我们常说的hashMap的put过程。
但是,HashMap源码中设置了这三个回调函数,注释说明了允许LinkedHashMap使用。也就是通过这三个我们来将元素插入到链表中,这样的话我们就保证了在看起来,输入和输出是一致的。

TreeSet
TreeSet是一个有序的集合 有序 有序 有序 重要的事情说三遍!而且它默认是升序的,对于数字就是比较大小,对于字符串就是比较首字母,其他的类型则需要自己实现Comparable接口。
先看实战代码
TreeSet<Integer> set = new TreeSet<>();
sets.add(5);
set.add(7);
set.add(2);
set.add(13);
set.forEach(System.out::println);
输出结果:

呐,看到了吗?鲁迅先生都说过:实践是检验真理的唯一标准,你要是不相信,那我就带你看看源码。

看 底层其实是使用的TreeMap来存储元素的,TreeMap也是有序的,底层使用红黑树。红黑树天然支持自然排序。
同时TreeSet支持传入一个Comparator,这意味着我们可以通过创建排序器来自定义排序规则。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Pf8B6OtU-1627631753520)(C:/Users/DD-28/AppData/Roaming/Typora/typora-user-images/image-20210730140315843.png)]
//从大到小
TreeSet<Integer> sets = new TreeSet<>((o1, o2) -> o2 - o1);
sets.add(5);
sets.add(7);
sets.add(2);
sets.add(13);
sets.forEach(System.out::println);
输出结果:

现在我们知道了TreeSet是有序的了,那么,究竟它是如何实现有序的呢?
刚才既然都说了,TreeSet底层使用的是TreeMap,当然,add()操作也是用的map的put操作了。

呐,捋一下逻辑哈,如果树为null的话,就会构建一个TreeMapEntry并且将它设置为root根。

然后检查TreeMap有没有设置构造器,如果设置了就用它去对比key,如果没设置就用k.compareTo()去进行比较,注意了,put的时候,key不允许为null,否则会报空指针。
如果遍历树没有找到节点,就会通过new Entry<>(key, value, parent)去创建一个节点,然后扔到树上。
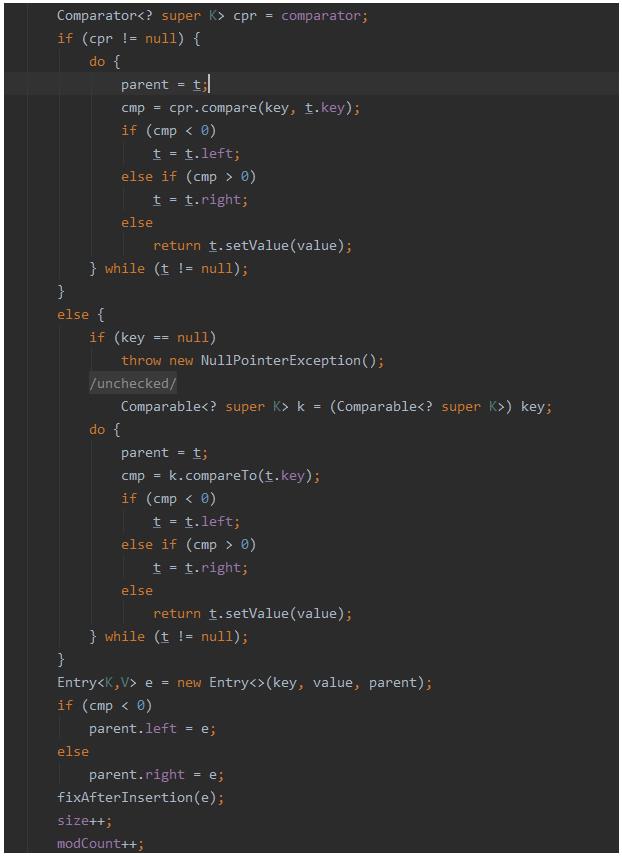
通过对比结果去判断放到父类的左节点还是右节点。
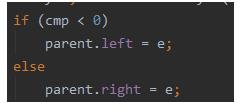
放完后会通过fixAfterInsertion(e)对节点进行操作,保证插入后还是一颗红黑树。

这一块的代码还是比较重要的,这个地方会去校验所有关于红黑树的规则。
扩展一点点红黑树知识
红黑树是一种含有红黑结点并能自平衡的二叉查找树。
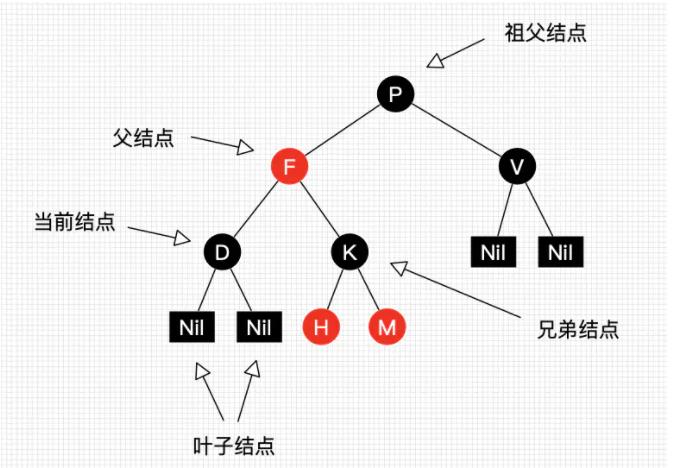
我们把正在处理(遍历)的结点叫做当前结点,如图2中的D,它的父亲叫做父结点,它的父亲的另外一个子结点叫做兄弟结点,父亲的父亲叫做祖父结点。
红黑树的特性:
性质1:每个节点要么是黑色,要么是红色。
性质2:根节点是黑色。
性质3:每个叶子节点(NIL)是黑色。
性质4:每个红色结点的两个子结点一定都是黑色。
性质5:任意一结点到每个叶子结点的路径都包含数量相同的黑结点。
Queue(队列)
定义
队列是一种特殊的线性表,它只允许在表的前端进行删除操作,而在表的后端进行插入操作。先进先出。

先思考一个问题,为什么我们要使用队列?
队列其实说到底只是一种数据结构,它不依赖于任何业务,但可以适用于任何业务,像我们常用的MQ,底层也是用到了队列,队列更多的是一种思路,为我们提供了一种先进先出的方式,我们可以用这种特性来约束功能,例如我们可以用它来做排队功能,先进先出。可以适用于绝大部分生产者消费者的情景。
站在整体架构看队列家族谱

Queue家族还是很庞大的,总整体来看,分为三类:Deque(双端队列)、BlockingQueue(阻塞队列)、AbstractQueue(非阻塞队列)
如果每个都铺开讲的话,估计打底两篇文章的篇幅,太多了,我会讲下每种队列的含义和应用并且找其中用的比较多的进行讲解,其余的大家自行www.google.com
AbstractQueue(非阻塞队列)
定义
顾名思义,非阻塞,队列中不会出现阻塞情况,进行任何操作,如果未达到预想,会直接返回null,而不是像阻塞队列那样停在那里,非阻塞队列想实现阻塞效果,需要使用wait/notify来实现。
ConcuretnLinkedQueue(无界的线程安全的非阻塞队列)
类图:
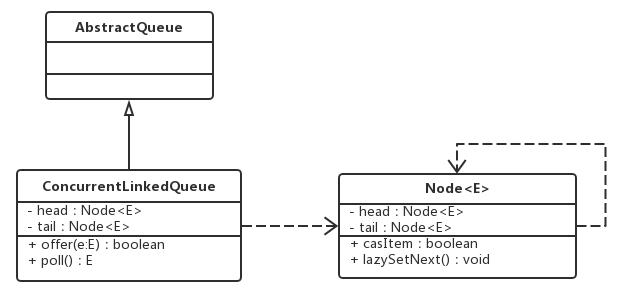
由类图我们看出,ConcurrentLinkedQueue是由head和tail节点组成的,而每个节点(Node)由Item(节点元素)和Next(指向下一个节点的引用)组成,正是通过这个next将队列变成了一个链表。
来,废话不多说,讲下实际应用
ConcurrentLinkedDeque<Integer> queue = new ConcurrentLinkedDeque<>();
for (int i = 0; i < 20; i++) {
queue.add(1+i);
System.out.println("我放进去了一个元素:"+(1+i));
}
System.out.println("队列中的一个元素是:"+queue.peek());
System.out.println("我取出了一个元素" + queue.poll());
//在队首放入一个元素
queue.addFirst(0);
//在队尾放入一个元素
queue.addLast(66);
System.out.println(queue);
API:

有兴趣的可以去看下它的底层源码,它使用了大量的cas思想来保证线程安全。
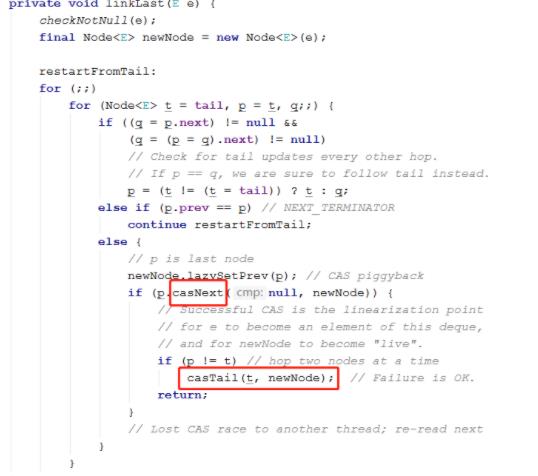
BlockingQueue(阻塞队列)
阻塞队列用的是很多的,例如在线程池中,就会使用到阻塞队列,处理不了的线程会放到阻塞队列中排队等待。而且JDK中很多关于多线程的解决方案中,都会使用BlockingQueue来做
定义
BlockingQueue 方法以四种形式出现,对于不能立即满足但可能在将来某一时刻可以满足的操作,这四种形式的处理方式不同:第一种是抛出一个异常,第二种是返回一个特殊值(null 或 false,具体取决于操作),第三种是在操作可以成功前,无限期地阻塞当前线程,第四种是在放弃前只在给定的最大时间限制内阻塞。
ArrayBlockingQueue
基于数组的有界队列,创建的时候需要指定大小

如果想要抛出异常:
queue.add();
如果添加的元素数量超过了队列长度,会抛出Queue full的异常
ArrayBlockingQueue<Integer> queue = new ArrayBlockingQueue<>(2);
for (int i = 0; i < 5; i++) {
queue.add(1+i);
}
for (int i = 0; i < 5; i++) {
queue.remove(1+i);
}
queue.remove();
如果队列已经空了 还执行remove操作会报NoSuchElement的异常
如果想要不 抛出异常:
添加元素的时候使用queue.offer(); //这样如果队列满了的话就会返回false 不会抛异常
移除元素的时候使用queue.poll(); //这样如果队列中空了话就会返回null 不会抛出异常。
ArrayBlockingQueue<Integer> queue = new ArrayBlockingQueue<>(2);
for (int i = 0; i < 5; i++) {
boolean offer = queue.offer(1 + i);
System.out.println("我放入成功了吗?:" + offer);
}
for (int i = 0; i < 6; i++) {
Integer poll = queue.poll();
System.out.println("我从队列里拿出的值:"+poll);
}
如果想要满了之后一直阻塞:
queue.put();//添加 如果满了之后会阻塞在最后一个添加的满了元素的位置。
queue.take();//移除 如果没有了会一直阻塞在最后一个移除的元素的位置。
ArrayBlockingQueue<Integer> queue = new ArrayBlockingQueue<>(2);
for (int i = 0; i < 5; i++) {
queue.put(1 + i);
System.out.println("我放入了值:"+(1+i));
}
//再试一下i<2的情况
//.....
for (int i = 0; i < 6; i++) {
Integer take = queue.take();
System.out.println("我取出了值:" + take);
}
设置阻塞超时等待:
queue.offer(“a”,2,TimeUnit.Seconds) 代表添加元素a时如果超时两秒钟 就超时返回false
SynchronousQueue
它本质上并不是一个队列,因为他没有给元素保留任何的存储空间,而是维护了一份线程清单,也就是说一个线程进入后,它就被从清单中移除,除非这个线程出去,否则下一个是永远无法进入队列的,会一直阻塞,所以这种队列只适用于消费者很充足的时候。
SynchronousQueue<Integer> queue = new SynchronousQueue<Integer>();
Thread putThread = new Thread(new Runnable() {
@Override
public void run() {
try {
System.out.println("我放进去了一个值");
queue.put(1);
} ca以上是关于长文预警!吐血总结2万字Java容器,再也不怕面试官刨根问底了。的主要内容,如果未能解决你的问题,请参考以下文章
长文预警!吐血总结2万字Java容器,再也不怕面试官刨根问底了。