docker网络原理,k8s网络原理
Posted Leo Han
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了docker网络原理,k8s网络原理相关的知识,希望对你有一定的参考价值。
我们知道docker安装完之后,每个docker容器里面都有自己单独的网络,那么docker的网络是怎么工作的呢 ?
首先我们需要了解的是Linux提供了基于NameSpace的隔离机制,主要包含如下NameSpace隔离:
- Mount Namespace隔离了一组进程所看到的文件系统挂载点的集合,因此,在不同Mount Namespace的进程看到的文件系统层次结构也不同。
- UTS Namespace隔离了uname()系统调用返回的两个系统标示符nodename和domainname,在容器的上下文中,UTS Namespace允许- 每个容器拥有自己的hostname和NIS domain name,这对于初始化和配置脚本是很有用的,这些脚本根据这些名称来定制它们的操作。
- IPC Namespace隔离了某些IPC资源(interprocess community,进程间通信),即System V IPC和POSIX消息队列,这些IPC机制的共同特点是,IPC对象由文件系统路径名以外的机制来识别。每个IPC命名空间都有自己的一套System V IPC标识符和自己的POSIX消息队列文件系统。
- PID Namespace隔离了进程ID号空间,不同的PID Namespace中的进程可以拥有相同的PID。PID Namespace的好处之一是,容器可以在主机之间迁移,同时容器内的进程保持相同的进程ID。PID命名空间还允许每个容器拥有自己的init(PID 1),它是 “所有进程的祖先”,负责管理各种系统初始化任务,并在子进程终止时收割孤儿进程。
从特定的PID Namespace实例来看,一个进程有两个PID:Namespace内的PID和主机系统上命名空间外的PID。PID命名空间可以嵌套:一个进程从它所在的PID Namespace一直到根PID Namespace,每一层的层次结构都有一个PID,一个进程只能看到他自己PID Namespace和嵌套在该PID Namespace下面的Namespace中包含的进程。 - Network Namespace提供了网络相关系统资源的隔离,因此,每个Network Namespace都有自己的网络设备、IP地址、IP路由表、/proc/net目录、端口号等。
网络命名空间使得容器从网络的角度来看是很有用的:每个容器可以有自己的(虚拟)网络设备和自己的应用程序,并与每个命名空间的端口号空间绑定;主机系统中合适的路由规则可以将网络数据包引导到与特定容器相关联的网络设备。因此,例如,可以在同一个主机系统上拥有多个容器化的网络服务器,每个服务器都绑定到其(每个容器)网络命名空间的80端口。 - User Namespace隔离了用户和组ID号空间,一个进程的用户和组ID在用户命名空间内外可以是不同的,一个进程可以在用户命名空间外拥有一个正常的无权限用户ID,同时在命名空间内拥有一个(root权限)的用户ID。
而docker中的网络则使用了 Network Namespace命名空间隔离,docker的网络提供了如下四种模型:
- Bridge模式,docker容器会拥有一个自己独立的Network Namespace,然后会建立一个veth对,另外一端连接docekr0网桥
- Host 模式,docker容器不会拥有自己独立的Network Namespace,而是和宿主机共享同一个Network Namespace,使用同样的环境
- Container模式,docker容器会跟应存在的容器共享同一个Network Namespace
- None 模式,docker容器会拥有独立的Network Namespace,但是不会进行任何的网络设置,只有一个网络回环地址
先大致介绍上面这些内容,然后引出下面要介绍的一个点:Linux网桥、veth对
-
Veth pair
在Linux中,根据之前的介绍,Network Namespace提供了不同的网络环境隔离,不同Network Namespace中,网络环境不同,这两个Network Namespace该如何通信?为此,Linux提供了虚拟网络设备Veth pair 对,一端连着一个Network Namespace,一端连着另外一个Network Namespace,这样这两个Network Namespace通过Veth对就可以实现通信了。 -
Linux网桥
Linxu网桥同veth pair一样,也是一个虚拟网桥设备,这里首先说一下桥接的概念:桥接就是把一台服务器上的不同网络端口连接起来,从而使得一个端口接收到的数据能从另外一个端口发送出去,这样端口之间能够进行报文的转发。看过之前的网络介绍
TCP三次握手详解,滑动窗口,网络包路由过程,全连接队列,半连接队列
其中交换机就实现了这样的功能,连接在同一个交换机上的不同服务器能够通过交换机的桥接可以互相通信。
Linux从内核级别支持了桥接功能,其实现就是前面说的网桥。veth pair对可以将两个不同Network Namespace进行连通,但是超过两个则无法实现,这时候可以使用网桥,veth pair一端连着网桥,另外一端连着Network Namespace,这样当主机上多个不同的Network Namespace进行通信时,通过网桥进行转发,这时候网桥相当于是交换机,每个Network Namespace相当于是一台机器,在同一个网段的机器之间通过网桥实现相互之间的通信。
docker在安装完之后,就会在host主机上添加一个docker0网桥,通过docker0网桥,host宿主机上的不同容器之间可以相互通信。
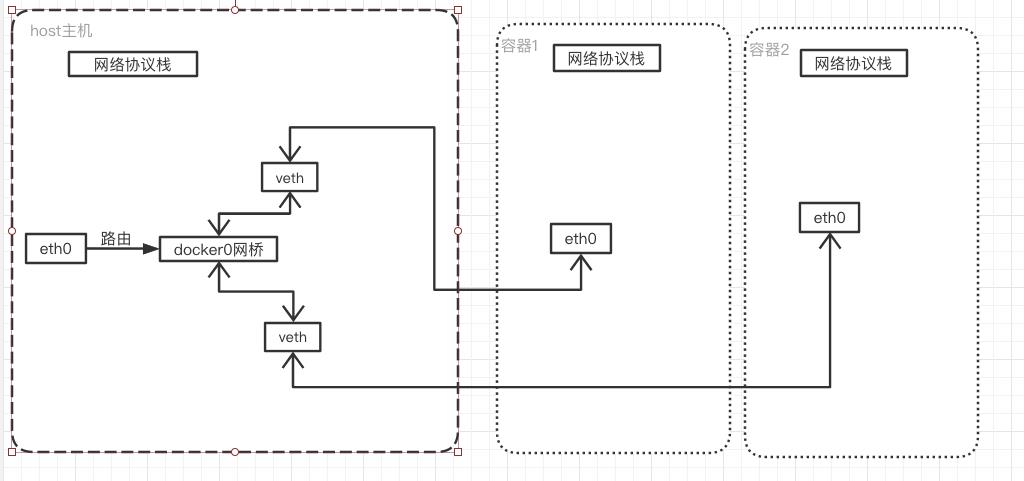
如上图所示,这里大概简单描述了下网络交互。
实际上除了上面说的veth pari和网桥,还有一个比较重要的工作机制是iptables路由。
iptables和Netfilter
Linux内核中提供了一套机制,让用户自定义处理自己关心的数据包,在linux网络协议栈中有一组回调函数挂载点,通过这些挂载点挂在的回调函数,可以对Linux网络栈处理处举报的过程中对数据包进行一些操作,如:过滤、修改、丢弃等。这个技术就是俗称的Netfiler和iptables。
Netfilter负责在内核中执行各种挂接的规则,运行在内核模式中,而iptables则是在用户模式下运行,负责协助和维护内核中Netfilter的各种规则表,二者相互配合。
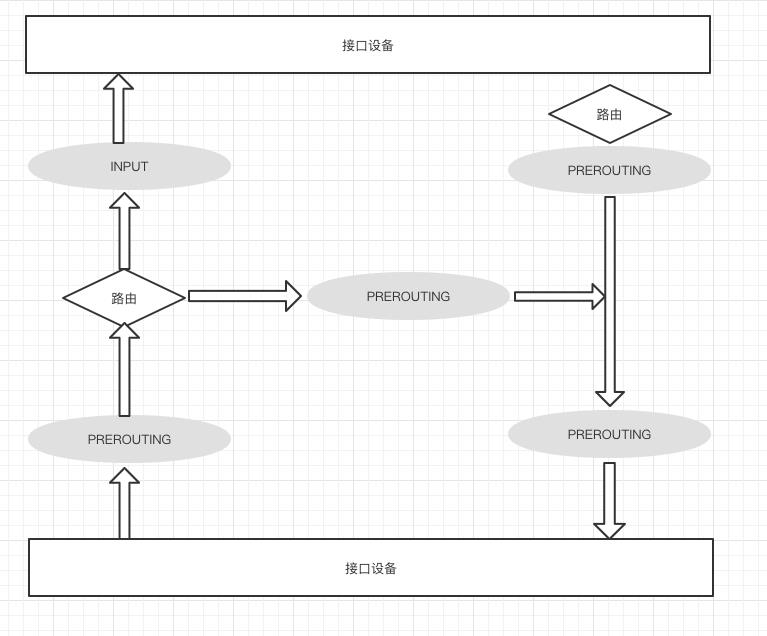
如上图所示,iptables主要在5条链上:
- INPUT链,一般用于处理输入本地进程的数据包
- OUTPUT链,一般用于处理本地进程的输出数据包
- FORWARD链,一般用于转发到其他机器或者Network Namespace的数据包
- PREROUTING链,可以在此进行DNAT
- POSTROUTING链,可以在此进行SANT
另外iptables还有5张表: - filter表,用于过滤某条链路上的数据包,是继续往下传输还是丢弃或者拒绝
- nat表,用于修改数据包的源和目的地址
- mangle表,用于修改数据包的ip头信息
- raw表,去除iptables对数据表的连接追踪
- security表,在数据包上应用SELINUX
5张表的优先级从高到低是 raw > mangle > nat > filter > security
一般iptables在匹配到规则之后会有如下几种操作:
- DROP,直接将数据包丢弃,不在进行后续的处理
- REJECT,返回Connection refused或者destination unreachable报文
- QUEUE,将数据包放入用户空间队列,供用户空间的程序处理
- RETURN,跳出当前链,后续的规则不在处理
- ACCEPT,同意数据包通过,继续执行后续的规则
这里说下几个概念:
- DNAT,根据指定条件修改数据包的目标IP地址和目标端口,
- SNAT,可以理解为DNAT的反向操作,即修改数据包的源IP地址和端口
现在我们在回到我们开始说的docker的网络模型,docker启动的时候默认采用的bridge模式,docker daemon启动后会安装一个docker0网桥,然后会为每个容器分配一个Network Namespace,然后通过veth pair模式,一端连接到docker0网桥上,另外一端连接到我们的容器里。
这样,在单个host主机上,通过网桥、veth pair对、iptables就能够实现不同容器之间的网络通信,但是跨主机之间如何进行通信呢 ?
接下来我们说下k8s中的网络,我们知道k8s中调度单元是基于pod的,而一个pod内是可以存在多个容器的,我们首先在pod级别查看网络是怎么工作的。
在单个pod内部,实际上k8s会默认的给我们启动一个pause容器,这个容器有什么作用呢 ?这里需要说下的就是在一个pod内部是共享一个Network Namespace的,k8s将单个pod内部的网络设置都放在了这个pause容器内部,可以将paues容器理解为这个pod内部所有容器的父容器。
这就是我们说的,在同一个pod内部,不同服务之间可以通过localhost来进行通信。
我们知道在docker中如果要访问不同主机/机器上的容器,需要通过host主机端口映射来实现,但是在k8s中,在同一个集群中,每个docker0网桥都是可以被路由到的,同一个集群中,每台主机都可以访问其他主机上的pod的IP地址,并不需要在主机上做端口映射。
在同一个集群内部,不同主机上的POD是可以直接通过POD IP相互访问的,无需通过主机端口映射来访问
k8s在pod上层封装了一个Servce的概念,这个概念实际上类似发现代理的概念,请求service,然后service将请求转发到对应的POD上。
一般默认创建的service
kube-proxy
kube-proxy是k8s的核心组件,每个Node节点都会部署一份。
访问service的虚拟地址,即clusterIP+port,是通过kube-proxy来实现的。在每个k8s节点Node上都会运行kube-proxy进程,其核心功能是将某个service的访问请求转发到后端的多个POD实例上。kube-proxy将service的clusterIP+port通过iptables的NAT转换到具体的POD实例上,kube-proxy会动态的在iptables中创建该service的相关规则,而这些规则将访问当前节点请求分发到后端的POD的功能。由于在集群内部每个节点上都有kube-proxy服务,这样我们在集群内部任意一个节点上都可以发起对服务的请求访问。
如果是集群外部想要访问集群内部的service,则可以基于kube-proxy和NodePort来实现集群外部访问集群内部的pod
kube-proxy会定期从etcd中获取service的信息
总结来说,kube-proxy的作用如下:
- 监听kube-api,获取service信息
- 修改所有node上的iptables规则,维护路由信息
- 将请求转发到对应的pod上
在k8s 1.8版本之前,都是基于iptables实现,但是iptables有个问题,如果集群规模比较大,则iptabels规则表会很大,可能会导致内核忙不过来,假如集群有5000个节点,一共有2000个服务,每个服务有10个POD,则会在每个节点上产生20000个iptables记录
因此在k8s 1.8版本引入了ipvs支持,IPVS相对于iptables来说效率会更加高,使用ipvs模式需要在允许proxy的节点上安装ipvsadm,ipset工具包加载ipvs的内核模块。并且ipvs可以轻松处理每秒 10 万次以上的转发请求。
k8s中集群外部访问集群内部服务
在k8s中一般通过如下方式可以在集群外部访问集群内部服务:
- NodePort,这时候集群中每个Node节点上都会指定监听端口,可以通过访问任意节点端口即可访问到指定服务,但是如果服务过多,大量端口难以维护
- LoadBalance,LoadBalance一般由云服务厂商提供
- Ingress,相当于是一个7层的转发器,创建一个Ingress Controller,例如nginx-ingress-controller,在每个Node节点都会启动一个nginxpod,采用
hostPort模式,这样外部客户端可以通过访问Node节点上的nginx服务来代理到实际的服务。
以上是关于docker网络原理,k8s网络原理的主要内容,如果未能解决你的问题,请参考以下文章