k8s网络之Calico网络-工作原理
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了k8s网络之Calico网络-工作原理相关的知识,希望对你有一定的参考价值。
参考技术A 他写的太好了,上链接: https://www.cnblogs.com/goldsunshine/p/10701242.htmlcalico有两种模式:ipip(默认)、bgp,bgp效率更高。
如果宿主机在同一个网段,可以使用ipip模式;
如果宿主机不在同一个网段,pod通过BGP的hostGW是不可能互相通讯的,此时需要使用ipip模式(如果仍想使用bgp模式,除非你在中间路由器上手动添加路由)。
Calico 网络原理
一、Calico基本介绍
Calico是一个纯三层的协议,为OpenStack虚机和Docker容器提供多主机间通信。Calico不使用重叠网络比如flannel和libnetwork重叠网络驱动,它是一个纯三层的方法,使用虚拟路由代替虚拟交换,每一台虚拟路由通过BGP协议传播可达信息(路由)到剩余数据中心。
二、Calico结构组成
Calico不使用重叠网络比如flannel和libnetwork重叠网络驱动,它是一个纯三层的方法,使用虚拟路由代替虚拟交换,每一台虚拟路由通过BGP协议传播可达信息(路由)到剩余数据中心;Calico在每一个计算节点利用Linux Kernel实现了一个高效的vRouter来负责数据转发,而每个vRouter通过BGP协议负责把自己上运行的workload的路由信息像整个Calico网络内传播——小规模部署可以直接互联,大规模下可通过指定的BGP route reflector来完成。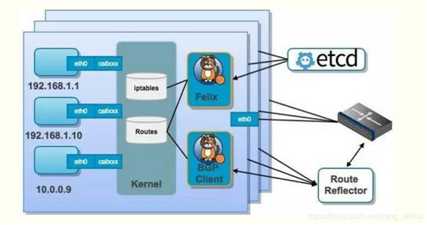
结合上面这张图,我们来过一遍 Calico 的核心组件:
Felix: Calico agent,跑在每台需要运行 workload 的节点上,主要负责配置路由及 ACLs 等信息来确保 endpoint 的连通状态;
etcd: 分布式键值存储,主要负责网络元数据一致性,确保 Calico 网络状态的准确性;
BGPClient(BIRD): 主要负责把 Felix 写入 kernel 的路由信息分发到当前 Calico 网络,确保 workload 间的通信的有效性;
BGP Route Reflector(BIRD): 大规模部署时使用,摒弃所有节点互联的 mesh 模式,通过一个或者多个BGP Route Reflector来完成集中式的路由分发;
通过将整个互联网的可扩展 IP 网络原则压缩到数据中心级别,Calico 在每一个计算节点利用Linux kernel实现了一个高效的vRouter来负责数据转发而每个vRouter通过BGP
协议负责把自己上运行的 workload 的路由信息像整个 Calico 网络内传播 - 小规模部署可以直接互联,大规模下可通过指定的BGP route reflector 来完成。这样保证最终所有的 workload 之间的数据流量都是通过 IP 包的方式完成互联的。
三、Calico 工作原理
Calico把每个操作系统的协议栈认为是一个路由器,然后把所有的容器认为是连在这个路由器上的网络终端,在路由器之间跑标准的路由协议——BGP的协议,然后让它们自己去学习这个网络拓扑该如何转发。所以Calico方案其实是一个纯三层的方案,也就是说让每台机器的协议栈的三层去确保两个容器,跨主机容器之间的三层连通性。
对于控制平面,它每个节点上会运行两个主要的程序,一个是Felix,它会监听ECTD中心的存储,从它获取事件,比如说用户在这台机器上加了一个IP,或者是分配了一个容器等。接着会在这台机器上创建出一个容器,并将其网卡、IP、MAC都设置好,然后在内核的路由表里面写一条,注明这个IP应该到这张网卡。绿色部分是一个标准的路由程序,它会从内核里面获取哪一些IP的路由发生了变化,然后通过标准BGP的路由协议扩散到整个其他的宿主机上,让外界都知道这个IP在这里,你们路由的时候得到这里来。
由于Calico是一种纯三层的实现,因此可以避免与二层方案相关的数据包封装的操作,中间没有任何的NAT,没有任何的overlay,所以它的转发效率可能是所有方案中最高的,因为它的包直接走原生TCP/IP的协议栈,它的隔离也因为这个栈而变得好做。因为TCP/IP的协议栈提供了一整套的防火墙的规则,所以它可以通过IPTABLES的规则达到比较复杂的隔离逻辑。
四、Calico网络方式(两种)
IPIP
从字面来理解,就是把一个IP数据包又套在一个IP包里,即把 IP 层封装到 IP 层的一个 tunnel,看起来似乎是浪费,实则不然。它的作用其实基本上就相当于一个基于IP层的网桥!一般来说,普通的网桥是基于mac层的,根本不需 IP,而这个 ipip 则是通过两端的路由做一个 tunnel,把两个本来不通的网络通过点对点连接起来。ipip 的源代码在内核 net/ipv4/ipip.c 中可以找到。
BGP
边界网关协议(Border Gateway Protocol, BGP)是互联网上一个核心的去中心化自治路由协议。它通过维护IP路由表或‘前缀’表来实现自治系统(AS)之间的可达性,属于矢量路由协议。BGP不使用传统的内部网关协议(IGP)的指标,而使用基于路径、网络策略或规则集来决定路由。因此,它更适合被称为矢量性协议,而不是路由协议。BGP,通俗的讲就是讲接入到机房的多条线路(如电信、联通、移动等)融合为一体,实现多线单IP,BGP 机房的优点:服务器只需要设置一个IP地址,最佳访问路由是由网络上的骨干路由器根据路由跳数与其它技术指标来确定的,不会占用服务器的任何系统。
五、Calico网络通信模型
calico是纯三层的SDN 实现,它基于BPG 协议和Linux自身的路由转发机制,不依赖特殊硬件,容器通信也不依赖iptables NAT或Tunnel 等技术。
能够方便的部署在物理服务器、虚拟机(如 OpenStack)或者容器环境下。同时calico自带的基于iptables的ACL管理组件非常灵活,能够满足比较复杂的安全隔离需求。
在主机网络拓扑的组织上,calico的理念与weave类似,都是在主机上启动虚拟机路由器,将每个主机作为路由器使用,组成互联互通的网络拓扑。当安装了calico的主机组成集群后,其拓扑如下图所示: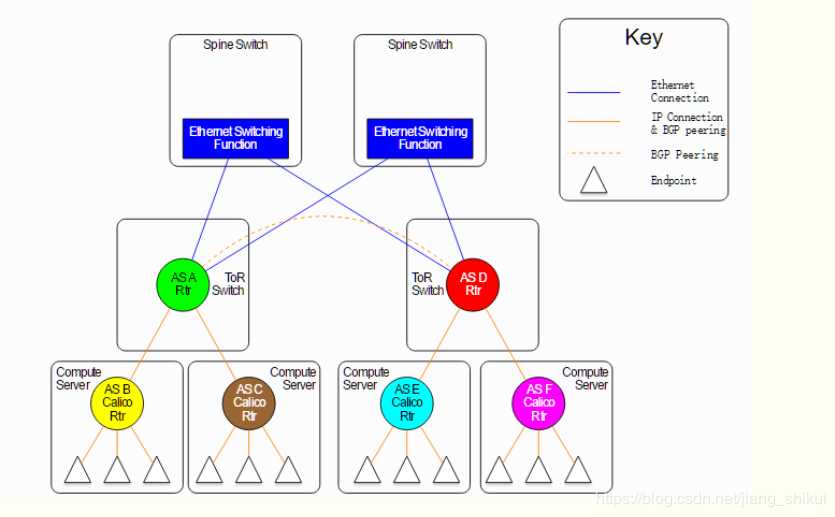
每个主机上都部署了calico/node作为虚拟路由器,并且可以通过calico将宿主机组织成任意的拓扑集群。当集群中的容器需要与外界通信时,就可以通过BGP协议将网关物理路由器加入到集群中,使外界可以直接访问容器IP,而不需要做任何NAT之类的复杂操作。
当容器通过calico进行跨主机通信时,其网络通信模型如下图所示: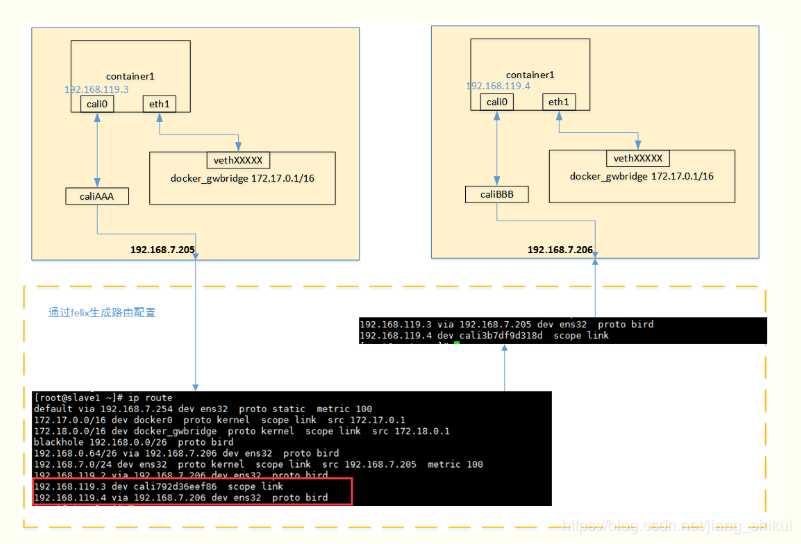
从上图可以看出,当容器创建时,calico为容器生成veth pair,一端作为容器网卡加入到容器的网络命名空间,并设置IP和掩码,一端直接暴露在宿主机上,并通过设置路由规则,将容器IP暴露到宿主机的通信路由上。于此同时,calico为每个主机分配了一段子网作为容器可分配的IP范围,这样就可以根据子网的CIDR为每个主机生成比较固定的路由规则。
当容器需要跨主机通信时,主要经过下面的简单步骤:
容器流量通过veth pair到达宿主机的网络命名空间上。
根据容器要访问的IP所在的子网CIDR和主机上的路由规则,找到下一跳要到达的宿主机IP。
流量到达下一跳的宿主机后,根据当前宿主机上的路由规则,直接到达对端容器的veth pair插在宿主机的一端,最终进入容器。
从上面的通信过程来看,跨主机通信时,整个通信路径完全没有使用NAT或者UDP封装,性能上的损耗确实比较低。但正式由于calico的通信机制是完全基于三层的,这种机制也带来了一些缺陷,例如:
calico目前只支持TCP、UDP、ICMP、ICMPv6协议,如果使用其他四层协议(例如NetBIOS协议),建议使用weave、原生overlay等其他overlay网络实现。
基于三层实现通信,在二层上没有任何加密包装,因此只能在私有的可靠网络上使用。
流量隔离基于iptables实现,并且从etcd中获取需要生成的隔离规则,有一些性能上的隐患。
以上是关于k8s网络之Calico网络-工作原理的主要内容,如果未能解决你的问题,请参考以下文章
16.kubernetes笔记 CNI网络插件(二) Calico介绍