如何实现高效联表查询
Posted 迹说
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何实现高效联表查询相关的知识,希望对你有一定的参考价值。
本地缓存
缓存作为提高性能一种可选方式最先被考虑,其具有简单、易用、高效的特性。在结合Java8之后的新特性 Lambda 表达式,可以轻松实现类似 Join、Groupby、Sort 操作。
这个方式也是我首选的处理方式。其本质是将原本数据库处理压力转嫁到服务器内存中,鉴于现在绝大多数公司都是分布式架构,服务性能相比单体架构有明显的提升,反观,mysql 在分布式时代常常成为性能的瓶颈,从而衍生出 TiDB 这类分布式数据库。
但缓存方式存在明显的短板—不适合大数据量操作,容易导致 Out Of Memory。但我有一个大胆,其实也称不上大胆想法,我们是不是可以实现 Spark SQL 一样在内存中构建表结构,处理表相关操作呢?如果有机会的话,再跟大家进行分享。
冗余
退而求其次,冗余也是常常被采用的方式,但其往往存在实时性和准确性的问题,因而只适合允许不精准和对变化宽容的场景。从本质来说,我认为冗余也是缓存的一种实现方式,如果这个问题,不局限于自身数据库去实现冗余,我们可以尝试使用 Redis 实现实时性的冗余,把所有服务都需要的用户手机号码信息放到 Redis 中,其他服务通过直接调用 Redis 获取数据,或者用户中心提供一系列查询 API 供其他业务线服务使用。而且 Github 上存在一个 rediSQL 开源项目,支持 Redis 数据通过 SQL 方式实现数据查询,现在已经孵化成为 zeeSQL,这样是不是可以更加 Think Big 了呢。
Join 查询
虽然本文已经使用大量的篇幅表明不愿意在数据库层面处理 Join 查询,但还是存在大量场景选用数据库 Join 操作才是比较简单高效的方式。因而,当不得不选择该种方式时,我们又有哪些提高查询性能的方式呢?
很多时候不是产品不够好,而是使用的人不会用。Join 查询也是一样,如果从实现原理了解,从根上对其有深入的了解,才能发挥其真正的作用。下面是我的一些摘记,与大家分享:
本文以 Left Join 作为示例说明,其他 Join 类似。
前提:
- 被 Join 表 关联字段需要存在索引
- 两表的关联字段需要编码格式一样,否则索引会失效
优化:
- 根据实际情况选择合适的Join算法(NLJ 和 BNL)
- 尽量使用 hash join(8.0.18 )
- 根据业务场景选择 Join 类型,尽可能选择 Join,而避免使用 Left Join 、Right Join、Full Join
- 关联条件存在 NULL 情况,在 where 语句中添加排除为空的条件
- 不使用子查询
- 结合实际业务场景选择合适 Join 方案
答疑:
Left Join 与 Join 原理区别
Join 以两张表中的数据量小的那张表作为基础表,依据关联条件,查询另一张表。Left Join 以左边那张表作为基础表,进行查询,往往左边那表是大表,所以 Join 查询要比 Left Join 性能好。
NLJ 和 BNL 原理
- 嵌套循环连接 Nested-Loop Join(NLJ) 算法:
适用于关联的两个字段都为索引的情况下,首先会查询出全部驱动表的关联字段,然后一一去和被驱动表关联,直至全部关联完成。
- 基于块的嵌套循环连接 Block Nested-Loop Join(BNL)算法:
如果关联字段不是索引或者有一个字段不是索引,MySQL则会采用此算法,和NLJ不同的是,BNL算法会多加一个join_buffer缓存块,关联时会把驱动表的部分数据放入到缓存块中,然后用被驱动表一一对比,直至查询完成。但是这个join_buffer缓存块是无序的,所以查询对比的次数会很多。
如何知晓当前查询属于哪种 Join 算法
至于一条SQL语句使用什么算法去做的关联操作,使用EXPLAIN命令可以查看,下面为嵌套循环连接算法:
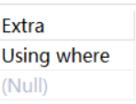
基于块的嵌套循环连接 Block Nested-Loop Join(BNL)算法:
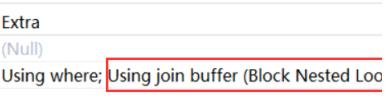
拓展阅读:
- mysql 如何优化left join - 云+社区 - 腾讯云
- 技术分享 | MySQL 优化:JOIN 优化实践 - 知乎
- https://blog.csdn.net/xianyun1992/article/details/107776797
以上是关于如何实现高效联表查询的主要内容,如果未能解决你的问题,请参考以下文章