hadoop 学习笔记-2wordcount 完整实例
Posted Zonson9999
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hadoop 学习笔记-2wordcount 完整实例相关的知识,希望对你有一定的参考价值。
目录
开发工具
IDEA
创建Maven项目
New Project-> Maven ,取名为 WordCountDemo ,然后点Finish 即可。


POM.XML 中添加项目依赖
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.3</version>
</dependency>
</dependencies>创建MyMapper.java
完整代码
package com.test;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class MyMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String data = value.toString();
String[] words = data.split(" ");
for (String word : words) {
context.write(new Text(word), new IntWritable(1));
}
}
}代码说明
类定义
public class MyMapper extends Mapper<LongWritable, Text, Text, IntWritable> 表示
1 Mapper的输入的键值对的类型分别是 LongWritable 和 Text
2 Mapper的输出的键值对的类型分别是 Text 和 IntWritable
函数定义
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException { 比如我有一个待处理的文件,文件内容一共两行,如下:
i have a dream
i want to be a coder那么这个map 函数会被调用两次,第一次调用输入的参数是
key : 1
value: i have a dream
第二次调用输入的参数是
key : 15
value: i want to be a coder
注:这里的key 是 value 首个字符在文件中的偏移量 offset
函数实现
1 把输入的内容转为java String 类型
String data = value.toString()
2 对字符串以空格为分隔符进行切分
String[] words = data.split(" ")比如, i have dream 分割后的结果是一个字符串数组
[
i,
have,
a,
dream
]
3 写入 mapper 的结果
i 出现了 1 次
have 出现了 1 次
a 出现了 1 次
dream 出现了 1 次
for (String word : words) {
context.write(new Text(word), new IntWritable(1));
}创建MyReducer.java
完整代码
package com.test;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class MyReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int total = 0;
for (IntWritable v : values) {
total += v.get();
}
context.write(key, new IntWritable(total));
}
}
代码说明
类定义
public class MyReducer extends Reducer<Text, IntWritable, Text, IntWritable>
表示
1 Reducer 的输入的键值对的类型分别是 Text 和 IntWritable
2 Reducer 的输出的键值对的类型分别是 Text 和 IntWritable
函数定义
protected void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException
从略
函数代码说明
从略
创建Main.java
完整代码
ackage com.test;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class Main {
public static void main(String[] args) throws Exception {
Job job = Job.getInstance( new Configuration());
job.setJarByClass(Main.class);
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job, new Path("/test/demo.txt"));
FileOutputFormat.setOutputPath(job, new Path("/test/demo.wc"));
job.waitForCompletion(true);
}
}

运行wordcount
生成jar包
点击 maven lifecycle package 生成 jar 包


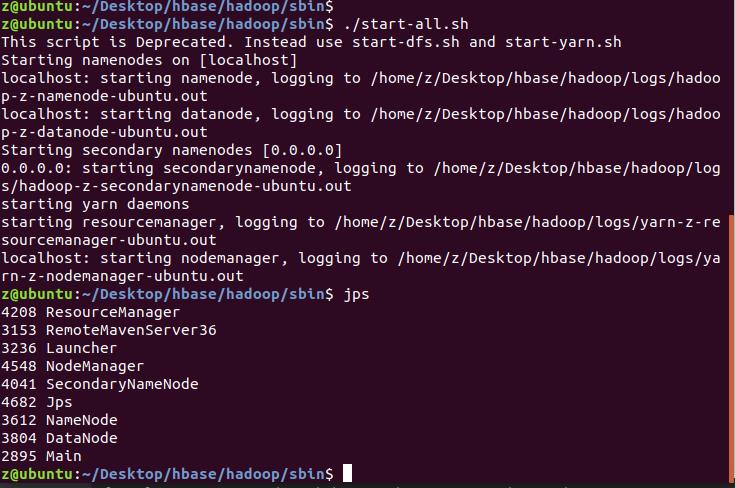
启动hadoop
准备测试文件
代码里指定了程序的输入文件为 hdfs /test/demo.txt
输出文件为 /test/demo.wc
使用 hadoop fs -copyFromLocal 将文件上传至hdfs

运行

运行成功输出
查看运行结果:

以上是关于hadoop 学习笔记-2wordcount 完整实例的主要内容,如果未能解决你的问题,请参考以下文章