我用python一个小时爬了10.9G图片
Posted 旁观者lgp
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了我用python一个小时爬了10.9G图片相关的知识,希望对你有一定的参考价值。
免责声明:本项目仅供学习使用,请勿用于其他用途
预览地址:https://tx.lgpqkl.cn/static/meizi/#/

我先爬取了5000张图片,放到腾讯云存储上,然后做了一个前端项目来随机加载并显示图片,现在界面比较简陋,日后会逐渐完善。
如果想要本项目源码或打包图片可以添加我的微信(加备注):lgp15732461131
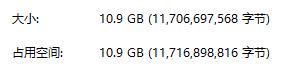
图片总大小截图
部分图片截图


爬数据
本来想去网站上爬取图片,却不曾想作者是通过接口方式来返回图片,便不需要去分析网页爬取图片了,只需要调用接口,获取图片地址和标签,将图片下载,再将图片信息存储到数据库,便大功告成了!二话不说,先上代码
import requests
import json
import pymysql
#连接数据库并查询
def doMysql(_id,_tag):
#打开数据库连接
db = pymysql.connect(host='127.0.0.1',user='root',passwd='root',db='images')
#获取游标
cur=db.cursor()
# SQL 插入语句 里面的数据类型要对应
sql = "INSERT INTO alls(id,tag) VALUES (%s,%s);"
val=(item['id'],str(",".join(item['tag'])))
try:
# 执行sql语句
cur.execute(sql,val)
# 执行sql语句
db.commit()
print('sql执行成功')
return True
except:
# 发生错误时回滚
print('sql执行失败')
db.rollback()
return False
# 关闭数据库连接
db.close()
# 多次获取数据,每次30条
for count in range(0,4980,30):
print(count)
all_image_url="http://这里是接口地址"
res=requests.get(all_image_url)
response=json.loads(res.text)
print(response['res']['wallpaper'][0]['preview'])
# 遍历每一次请求的30条数据,分别下载每一章图片
for index,item in enumerate(response['res']['wallpaper']):
print(index)
r=requests.get(item['preview'])
with open(r"pictures/"+item['id']+".png",'wb') as f:
f.write(r.content)
doMysql_result=doMysql(item['id'],str("".join(item['tag'])))
print(type(item['id']),str(item['tag']))
if(not doMysql_result):
break
# 关闭数据库连接
db.close()
#print(",".join(response['res']['wallpaper'][0]['tag']))
print('ok')
服务端
服务端采用nodejs实现,主要负责随机从数据库获取图片,返回给客户端,部分代码如下(加密部分以省略)
//引入mysql模块
const mysql = require('mysql');
// console.log(md5.hex_md5('123'))
/* GET home page. */
router.get('/get', function(req, res) {
//先检测时间戳是否在范围内,先后哈希运算进行检测真实性
mysql_query(function (result) {
if (result.length){
res.send(result)
add_request();
}
else {
res.send('err')
}
})
});
//每请求一次,插入一条记录,记录时间,ip等
function add_request() {
//创建数据库对象
const connection = mysql.createConnection({
host : '127.0.0.1',
user : 'root',
password : 'root',
database : 'images'
});
//连接数据库
connection.connect(function(err) {
if (err) {
console.error('连接失败: ' + err.stack);
// callback([]);
}
else {
var time_now=String(new Date());
// console.log('连接成功 id ' + connection.threadId);
//随机查询10条数据
var sql='INSERT INTO requests(time_req) VALUES(?);'
connection.query(sql,time_now, (err, results, fields) => {
if(err){
console.log(err);
// callback([]);
}
else {
// console.log(results);
// callback(results)
}
})
}
});
}
//随机获取10条数据函数
function mysql_query(callback){
//创建数据库对象
const connection = mysql.createConnection({
host : '127.0.0.1',
user : 'root',
password : 'root',
database : 'images'
});
//连接数据库
connection.connect(function(err) {
if (err) {
// console.error('连接失败: ' + err.stack);
callback([]);
}
else {
// console.log('连接成功 id ' + connection.threadId);
//随机查询10条数据
connection.query('SELECT * FROM alls ORDER BY RAND() LIMIT 10;', (err, results, fields) => {
if(err){
console.log(err);
callback([]);
}
else {
// console.log(results);
callback(results)
}
})
}
});
}
客户端
客户端采用uniapp实现,由于页面较简单,只有对服务器发起请求获取图片这样一部操作,这里不展示相应代码。
部署
下载完所有图片后觉得服务器空间已经快不够了,就开通了腾讯云的对象存储,将所用图片上传,并打开权限,共有读私有写,客户端根据图片id和腾讯云地址进行拼接即可找到图片的真实地址。
介绍结束,有什么问题的小伙伴可以私信我哦
以上是关于我用python一个小时爬了10.9G图片的主要内容,如果未能解决你的问题,请参考以下文章
为了在上海租房,我用python连夜爬了20000多条房源信息