爬了个豆瓣小说
Posted 小苹果的苹果树
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬了个豆瓣小说相关的知识,希望对你有一定的参考价值。
书友群里经常有人闹书荒,求推荐,于是我想了想,把豆瓣里面的小说们都爬了下来。

还是用的老方法,urllib+正则提取,没有用到scrapy这么高科技的东西(其实是因为windows下太难装了)。不过这一次我用的是python3。其实我只是在网上找了一下http头应该怎么写,那个网页用的是python3的,我就也用了。python2应该类似。其实方法还是相当简单的。
首先看看,豆瓣上面标签为“小说”的书的地址:
https://book.douban.com/tag/%E5%B0%8F%E8%AF%B4
试着前后翻翻页,能看到这个url后面加上了
?start=0&type=T
这两个get的参数,其中start表示从第几本书开始(20本书一页),type表示书的排序方式。其实豆瓣有默认的按照评分排序,但是并不准,所以,就按默认排序吧,下载下来自己手动sort一下就好了!
首先抓下来一个网页:
def get_html(url): """ 抓取网页 """ cj = http.cookiejar.CookieJar() opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj)) opener.addheaders = [(\'User-Agent\', \'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.101 Safari/537.36\'), (\'Cookie\', \'4564564564564564565646540\')] urllib.request.install_opener(opener) try: while True: page = urllib.request.urlopen(url) html = page.read().decode("utf-8") page.close() anti_spider = re.findall(r\'403 Forbidden\', html) if anti_spider: print("反爬虫了,休息10分钟...") time.sleep(600) else: return html except Exception as e: print(e) sys.exit()
对这一个网页中进行正则提取。在提取的过程中,我发现只能看到书籍的链接和书名,其他内容比如作者名和评分什么的,都是通过js动态生成的。噗。那就只好通过链接来获得每一本书的作者和评分了。
def get_books_info(html): """ 获得一页上面所有书的信息 """ books = [] one_page_books = re.findall(r\'href="(https://book\\.douban\\.com/subject/\\d+/)" title="(.*?)"\', html) for url, name in one_page_books: one_book_html = get_html(url) # print one_book_html author, score = get_book_info(one_book_html) # print author, score if not author and not score: break name = "《" + name + "》" print(\'{"name": %s, "author": %s, "score": %s, "url": %s}\' % (name, author, score, url)) books.append({"name": name, "author": author, "score": score, "url": url}) # print("别爬太快,休息一下") time.sleep(3) return books
有一件很重要的事应该要说一下,做爬虫,一定要记得sleep,不仅仅是伪装人类行为迷惑反爬虫,也是对网站的尊重。互联网上各种网站的访问已经有90%是爬虫了,其中大部分都是搜索引擎,我们就不要再给人家网站添麻烦了——处理你家爬虫是要消耗服务器资源的,连续不停的爬是不文明的行为!我在开始的时候没有sleep,结果在调试的过程中爬了几百个网页,然后被反爬虫了。好吧,应该向豆瓣道个歉。人家已经很客气了,让我放肆的爬了几百本书,才把我封掉,而且豆瓣本身提供了给爬虫使用的API,我还自己费劲的写正则。
下面是从一本书籍的页面中获得作者和评分:
def get_book_info(html): """ 获得一本书的评分和作者 """ try: score = re.findall(r\'property="v:average"> (.*?) </strong>\', html)[0] author = re.findall(r\'<span class="pl"> 作者</span>[\\w\\W]*?<a class="" href=".*?">(.*?)</a>\', html)[0] return author, score except Exception as e: print("评分和作者出了点小问题:") print(e) return "", ""
这段没什么好说的,全是偷懒写法的正则。
把上面的几个函数组合起来:
def main(): page = 0 books = [] while True: url = "https://book.douban.com/tag/%%E5%%B0%%8F%%E8%%AF%%B4?start=%s&type=T" % str(page) html = get_html(url) one_page_books = get_books_info(html) books.extend(one_page_books) if len(one_page_books) == 0: print("好啦只有这些书啦~") break page += 20 # 有的书评价人数太少,没有分数,怕信息不全,补全一下 for b in books: b["author"] = b["author"] or "(佚名)" b["score"] = b["score"] or "0.0" # 排序 books.sort(key=lambda x: float(x["score"]), reverse=True) # 保存书籍信息 with open("douban.csv", "w", encoding="gbk", errors="ignore") as f: line_template = "%(name)s,%(author)s,%(score)s,%(url)s\\n" f.write(line_template % ({"name": "书名", "author": "作者", "score": "豆瓣评分", "url": "豆瓣链接"})) for book in books: f.write(line_template % book)
最后在open的时候其实遇到了点小麻烦:网页是utf-8编码的,我爬下来网页之后就直接decode("utf-8")了。但是在windows下,open("douban.csv", "w")函数默认使用的中文编码方式是gbk,于是write时候就直接抛了个中文编码的异常。查到这个原因之后,我就加上了encoding="utf-8"这个参数。这回倒是成功保存了,但是csv默认用excel打开时还是乱码呀!因为excel使用gbk来打开的。倒是可以手动先用记事本打开,另存为选择ANSI来解决,但是我表示不屑于用这种方式,在群里问了问,有同学告诉我用ignore,燃鹅,在python3里面还encode/decode写一串,不是丑死!于是再百度,终于查到在python3中,open函数里面就可以直接加errors="ignore"这个参数。
搞定~最后的效果:
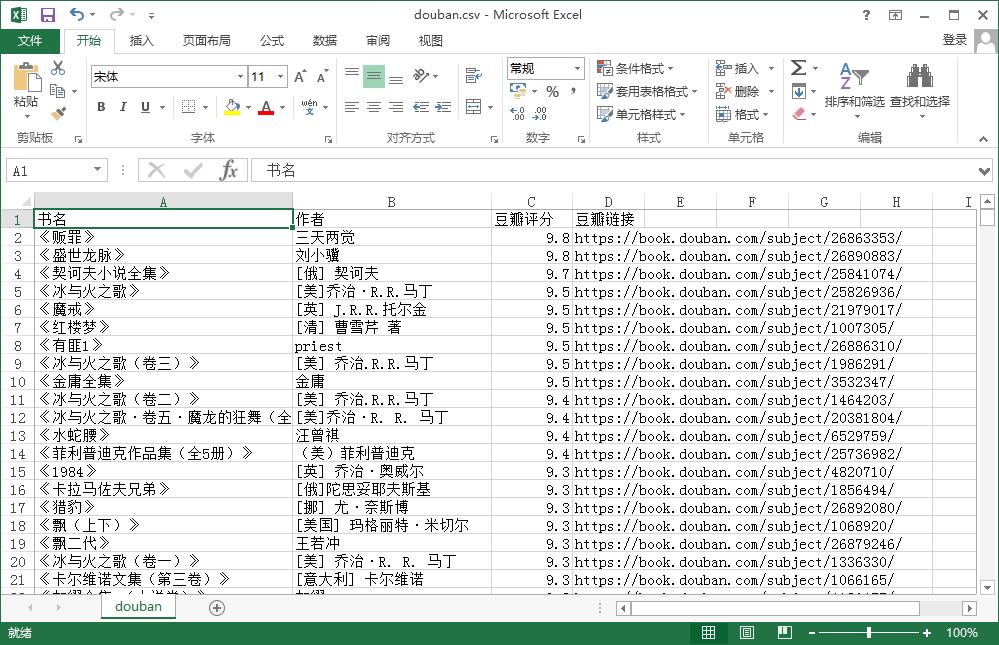
就酱。代码已上传github(https://github.com/anpengapple/doubanbooks)。有需要的同学拿去玩~其实还是不完美:第一,没有小说的详细类型;第二,只有小说而没有别的书;第三,没有直接保存excel,还得自己排版。将来有闲心可以再改改。(话说一直没学写excel也是因为懒,感觉全是体力劳动,完全没有技巧可言,不好玩)。
后记:
我发现我还是太天真了。今天在豆瓣看书评的时候,无意中发现小说标签的书有460多万本。纳尼?那为什么我只能爬下来998本呢?试了试,果然在浏览器中start的参数只支持3位,后面就搜不到了。(⊙﹏⊙)b果然这种爬虫还是不靠谱啊,等有空去看看api好了。https://developers.douban.com/wiki/?title=book_v2 只能说豆瓣对于开发者还是相当友好的,连这个都提供。
后后记:
API方式放弃。单个IP限制每小时访问才500次,这数量有点坑啊!我不想用伪装IP的方式来弄,还是想想别的办法吧!
以上是关于爬了个豆瓣小说的主要内容,如果未能解决你的问题,请参考以下文章