Real-Time-Voice-Cloning(github声音克隆项目)
Posted So istes immer
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Real-Time-Voice-Cloning(github声音克隆项目)相关的知识,希望对你有一定的参考价值。
①检查pytorch的安装

②ffmpeg是做什么的,在哪里下载?怎么使用?
ffmpeg是一个处理多媒体信息的框架,有视频采集、视频格式转换、视频抓图、给视频加水印等功能
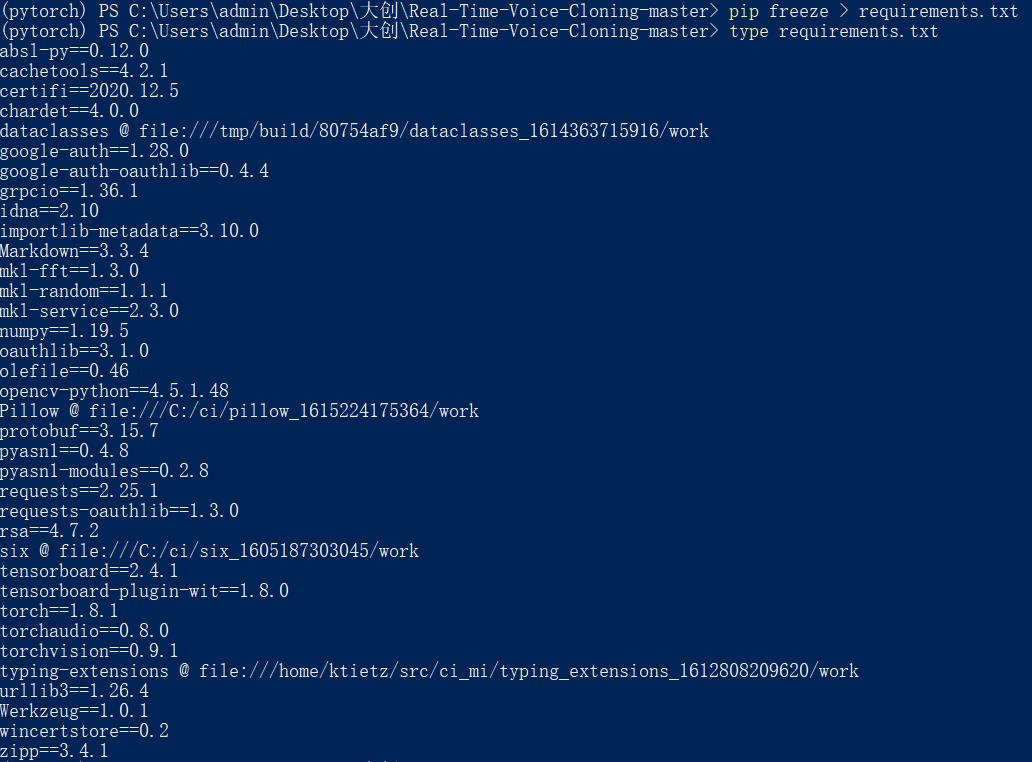
requirements.txt
python项目中必须包含一个 requirements.txt 文件,用于记录所有依赖包及其精确的版本号,以便新环境部署
切换到项目目录,生成requirement.txt文件并查看
③Download Pretrained Models(预训练模型)
预训练模型作为包含所有三个模型(扬声器编码器、合成器、声码器)的档案。
存档带有与存储库相同的目录结构,您需要将其内容与存储库的根目录合并。
下完pretrained.zip并解压,有三个文件夹encoder、synthesizer、vocoder。
把这三个文件夹中的内容复制到项目中对应的三个同名文件夹中
④Test Configuration(测试配置)
python demo_cli.py
发现No module named 'librosa'
也就是说少了个librosa模块(librosa是一个非常强大的python语音信号处理的第三方库)
安装:pip install librosa
发现No module named 'torch' 安装:pip install torch
发现No module named 'unidecode' 安装:pip install unidecode
发现No module named 'inflect' 安装:pip install inflect
发现No module named 'sounddevice' 安装:pip install sounddevice
都安装完了,显示如下

⑤Download Datasets(数据集)
对于单独使用工具箱,建议下载 LibriSpeech/train-clean-100
train-clean-100.tar.gz下好解压,有一个LibriSpeech文件夹
在Real-Time-Voice-Cloning-master这个项目里面,自己建一个名为datasets的文件夹,将LibriSpeech文件夹放进去
终端切换到项目的当前目录
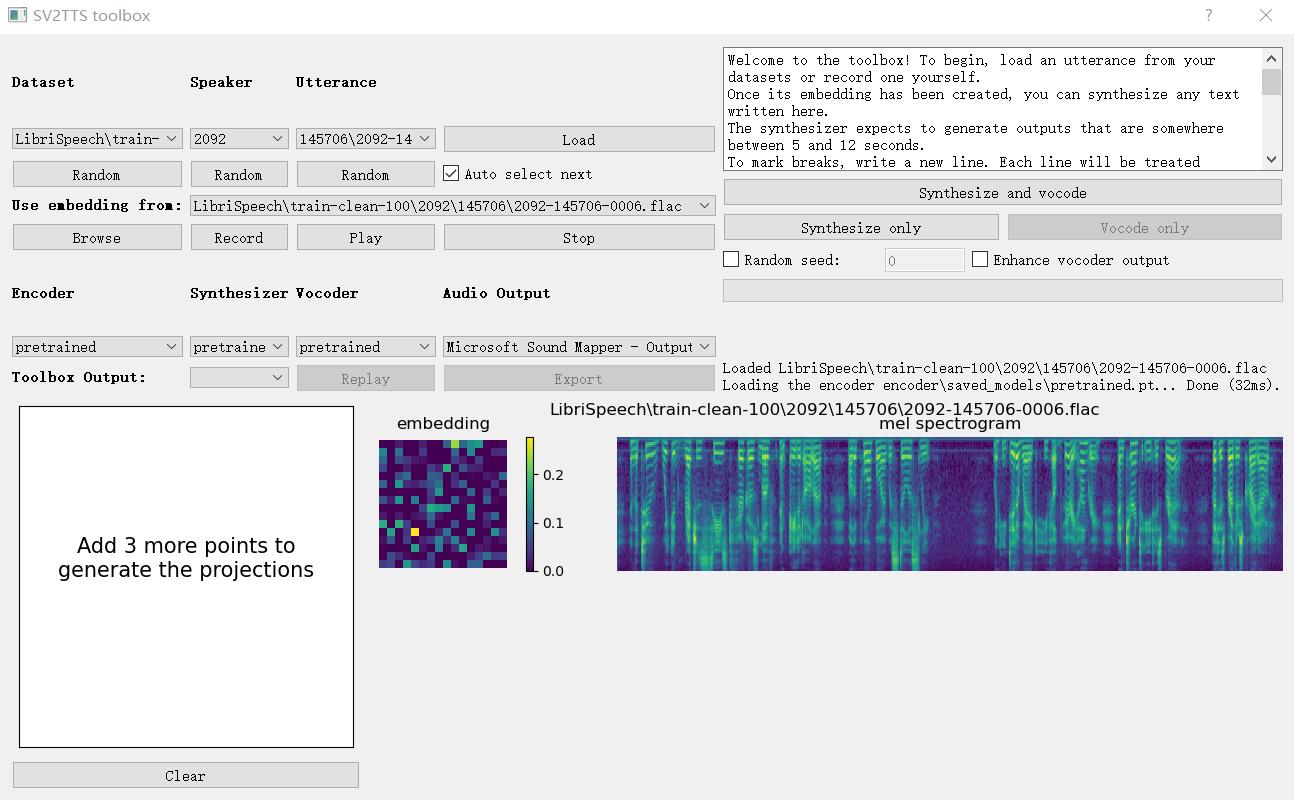
运行:python demo_toolbox.py -d datasets
即可Launch the Toolbox(启动工具箱)
在这过程中
发现No module named 'umap'
安装:pip install umap-learn -i https://mirrors.ustc.edu.cn/pypi/web/simple
发现"Unable to import 'webrtcvad'
安装:pip install webrtcvad
工具箱显示如下
以上是关于Real-Time-Voice-Cloning(github声音克隆项目)的主要内容,如果未能解决你的问题,请参考以下文章