只需要5秒就能克隆出你的声音
Posted 修炼之路
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了只需要5秒就能克隆出你的声音相关的知识,希望对你有一定的参考价值。
导读
只需要一段5秒钟的录音,就能将其他的文字转换成你的声音。Real-Time-Voice-Cloning该项目目前在git上以及接近30k的星,作者将克隆后的效果已经上传到youtube演示视频。遗憾的是这个项目只支持英文。
最近从这个项目中发展了一个中文的分支Realtime-Voice-Clone-Chinese,作者已经在效果上传到了bilibili演示视频
下面我就教大家如何在你的电脑上使用这个项目

运行环境
- 系统:Windows、Linux
- Python版本:3.7+
- pytorch版本:1.9.0
- GPU:可无
环境搭建
- 创建虚拟环境
conda create -n py3.9 python==3.9
- clone项目到本地
git clone https://github.com/babysor/Realtime-Voice-Clone-Chinese.git
- 安装项目所需要的库
pip install -r requirements.txt
- 安装pytorch
根据pytorch官方的文档,选择适合你系统适应的安装方式,安装1.9.0版本
https://pytorch.org/get-started/locally/
- 安装webrtcvad
pip install webrtcvad-wheels
- 安装ffmpeg
下载地址:https://ffmpeg.org/download.html#get-packages
根据你的系统选择ffmpeg进行安装
测试声音克隆的效果
- 下载预训练模型
百度网盘:https://pan.baidu.com/s/1PI-hM3sn5wbeChRryX-RCQ 提取码:2021
这里大家只需要下载synthesizer文件夹就行了,节省时间。其它的两个模型已经在项目里面了,下载好后将saved_models目录放到synthesizer目录下
- 启动工具箱
#激活你的虚拟环境
activate py3.9
#进入到项目目录
cd Realtime-Voice-Clone-Chinese
#启动UI界面
python demo_toolbox.py

-
选择合成的模型

合成模型有两个可以选择,ceshi和mandarin。目前ceshi的效果要好些,所以最好选择这个模型。这两个模型都是基于adatatang_200zh数据集训练出来的 -
克隆声音
提供了两种克隆声音的方式,第一种是通过录音,第二种是通过上传一段音频。通过从说话人的声音中提取声音特征信息,然后再利用这些特征信息来合成新的声音
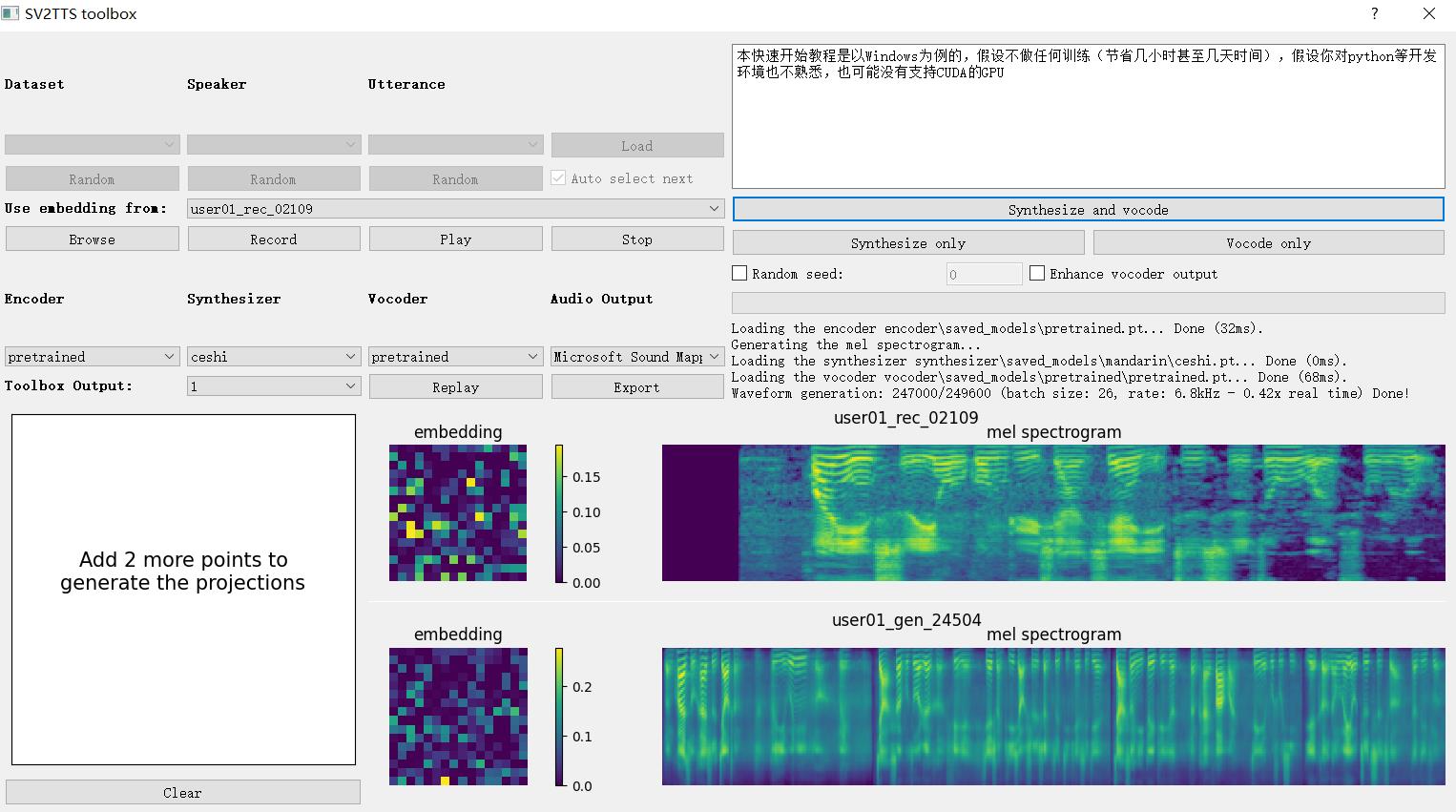
在录完音和上传一段音频之后,在文字框内输入你想要的合成声音的文字,再点击Synthesize and vocode就能开始合成声音,合成完成之后会自动播放合成的声音。
合成后的声音中可能会包含一些杂音,点击export导出音频文件会自动过滤掉杂音。
- 异常情况
在点击Synthesize and vocode之后,在输出信息报错

我这里是没有问题的,错误信息如下所示
RuntimeError: Error(s) in loading state_dict for Tacotron: size mismatch for encoder.embedding.weight: copying a param with shape torch.Size([70, 512]) from checkpoint, the shape in current model is torch.Size([75, 512]).
或者没有报错,但是合成的声音中全是杂音没有人声,需要做下面的修改,打开Realtime-Voice-Clone-Chinese\\synthesizer\\utils目录下的symbols.py文件

将11行的代码注释掉,改成下面的代码
_characters = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz12340!\\'(),-.:;? '
训练自己的模型
- 下载或者准备你想使用的数据集
- 数据集的预处理
需要使用梅尔频谱图对音频进行预处理
python synthesizer_preprocess_audio.py <datasets_root>
可以传入参数 --dataset {dataset} 支持adatatang_200zh,magicdata,aishell3如果是其他格式的数据集,可以将格式转换为上面这几种。
如果你的aidatatang_200zh文件放在D盘,train文件路径为 D:\\data\\aidatatang_200zh\\corpus\\train , 你的datasets_root就是 D:\\data\\
- 预处理嵌入
python synthesizer_preprocess_embeds.py <datasets_root>/SV2TTS/synthesizer
- 训练合成模型
python synthesizer_train.py mandarin <datasets_root>/SV2TTS/synthesizer
总结
从我目前的使用效果来看,合成声音的效果音色更像是数据集中的,和自己的还是有一定差距的。而且,对于一些数字和英文的效果不太理想。初步猜测应该是因为数据集的问题,毕竟训练模型的数据只有200h,而且数据中可能对于数字和英文覆盖的还不够。
建议:如果想要获得更好效果的模型,需要使用更大的数据集同时也要保证数据集的质量要高才行。
以上是关于只需要5秒就能克隆出你的声音的主要内容,如果未能解决你的问题,请参考以下文章