分布式NoSQL列存储数据库HbaseHbase的功能与应用场景基本设计思想
Posted 大数据Manor
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式NoSQL列存储数据库HbaseHbase的功能与应用场景基本设计思想相关的知识,希望对你有一定的参考价值。
分布式NoSQL列存储数据库Hbase(一)
知识点01:课程回顾

-
离线项目为例
- 数据生成:用户访问咨询数据、意向用户报名信息、考勤信息
- 数据采集
- Flume:实时数据采集:采集文件或者网络端口
- Sqoop:离线数据同步:采集数据库的数据
- 数据存储
- HDFS:分布式离线文件存储系统
- Hive:离线数据仓库
- 将HDFS上的文件映射成了表的结构,让用户可以通过数据库和表的形式来管理大数据
- 数据计算
- MapReduce+YARN:分布式离线数据计算
- Hive:通过SQL进行分布式计算
- 将SQL语句转换为MapReduce程序,提交给YARN运行
- 数据应用:通过对数据进行分析
- 提高转化率:访问与咨询转化率、报名转换率
- 考勤分析:通过考勤分析来把握所有人学习的情况
-
离线与实时
- 离线:数据从产生到最后被使用,时效性比较低,时间比较长
- 实时:数据从产生到最后被使用,时效性比较高,时间比较短
- 方向:所有数据的价值会随着时间的流逝,价值会越来越低,希望所有数据都能被实时的计算以及处理
- 实现实时:所有环节都必须是实时环节
- 数据生成:实时的
- 数据采集:实时的,Flume、Canal……
- 数据存储:实时的,Hbase、Kafka、Redis……
- 数据计算:实时的,Spark、Flink……
- 数据应用:实时应用:风控系统、实时推荐、精准分析
-
学习知识的逻辑
-
step1:先了解基本的功能与应用场景
-
step2:基本的使用
-
step3:深入了解原理
-
知识点02:课程目标
-
Hbase的功能与应用场景、基本设计思想【重点掌握】
- 这玩意有什么用?解决什么问题?
- 这玩意为什么能实现这样的功能?
- 什么时候需要用这个玩意?
- 这个玩意中的一些特殊的概念
-
搭建Hbase分布式集群环境
- 分布式架构【重点】
知识点03:HBASE诞生
1、问题
- 随着大数据的发展,大数据的应用场景越来越多,有了实时性的需求
- HDFS、MapReduce:都只能实现离线的处理以及计算
- 想做实时推荐
- 实时的采集用户的数据,实时分析,根据用户画像给用户推荐合适的商品
- 实时采集:Flume
- 实时存储:存储读写的性能在毫秒级别
- 实时计算:计算处理的性能在毫秒级别
2、需求
- 需要一项技术能实现大量的数据实时数据读写
- HDFS已经满足不了:HDFS解决离线大数据存储读写
- 设计:为了满足怎么存储大数据的问题
3、解决
- 谷歌的三篇论文
- GFS:基于文件系统的离线大数据存储平台HDFS
- MapReduce:基于离线大数据批处理分布式计算平台
- BigTable:分布式实时随机读写的NoSQL数据库【Chubby】
- Hbase + Zookeeper
- 设计:怎么高效的进行大数据读写存储的问题
4、总结
- Hbase能实现基于海量数据的随机实时的数据存储及读写
- 与mysql区别:Hbase实现大数据存储
- 与HDFS区别:Hbase性能更好,更快
知识点04:Hbase功能及应用场景

Apache HBase™ is the Hadoop database, a distributed, scalable, big data store.
#分布式 可扩展 大数据存储数据库
Use Apache HBase™ when you need random, realtime read/write access to your Big Data.
#随机的实时的大数据访问
This project's goal is the hosting of very large tables -- billions of rows X millions of columns --
#存储非常大的数据表
atop clusters of commodity hardware. Apache HBase is an open-source, distributed, versioned, non-relational database modeled after Google's Bigtable: A Distributed Storage System for Structured Data by Chang et al. Just as Bigtable leverages the distributed data storage provided by the Google File System, Apache HBase provides Bigtable-like capabilities on top of Hadoop and HDFS.
1、功能
-
Hbase是一个分布式的NoSQL数据库,能实现随机实时的大量数据的读写
-
大数据存储:分布式 + HDFS
-
实时数据读写
2、应用场景
- 电商:实时推荐
- 金融:实时风控、实时征信统计
- 交通:实时车辆监控
- 游戏:实时记录所有操作
- ……
知识点05:HBASE设计思想
1、问题
- 对于计算机而言,数据的存储只会在两个地方
- 内存:读写比较快
- 硬盘:读写相对慢一些
- 为什么Hbase可以实现大量数据的实时的读写?
- 问题1:为什么Hbase能存储大量数据?
- 问题2:为什么Hbase能读写很快?
2、需求
- 需求1:必须实现分布式存储,利用多台机器的硬件资源从逻辑上整合为一个整体
- 类似于HDFS设计思想
- 需求2:必须实现将数据存储在内存中,读写速度才能很快
- 为什么HDFS也是分布式,但是慢:HDFS所有的数据是存储在磁盘中
3、实现
- 实现1:Hbase做了分布式结构,利用多台机器组合成一个整体,多台机器的内存和磁盘进行逻辑合并了
- 实现2:Hbase优先将数据写入内存,读取数据时,如果数据在内存中,可以被直接读取
- 新的问题:内存的空间是比较小的,能存储的数据量不大,违背了Hbase能存储大数据吗?
- 内存的特点:内存容量小、数据易丢失、读写速度快
- 磁盘的特点:容量空间大、数据相对安全、速度相对慢
- Hbase如何能实现容量大和速度快的问题?
- 设计思想:冷热数据分离,实时计算中,对当前最新的数据进行读取处理应用
- 冷:大概率不会被用到的数据
- 在实时架构中,已经产生很久的数据
- 热:大概率会被用到的数据
- 在实时架构中,刚产生的数据
- 冷:大概率不会被用到的数据
- 解决:Hbase将数据写入内存中,如果内存中存储的数据满了,就将内存的数据写入磁盘
- 热:写内存,大概率的情况下,可以直接从内存中读取
- 冷:将内存中产生很久的数据写入磁盘中
4、总结
-
为什么Hbase既能存储大数据,也能很高的性能:冷热数据分离
-
最新的数据写入内存,大概率也是读内存
- 构建分布式内存:数据优先写入分布式内存
- Hbase集群
-
将老的数据写入磁盘,被读的概率相对较低
- 构建分布式磁盘:老的数据写入分布式磁盘
- HDFS集群
-
新的问题:Hbase数据如何能保证安全?
- HDFS保证数据安全机制:副本机制,每个数据块存储3份,存储在不同的机器上
- 内存:本身就是容易丢失的,如果断电
- 一般内存中数据不能通过副本机制来保证
- 因为内存空间小、内存都是易丢失的
- 一般内存的数据安全都选择写WAL的方式来实现的【记住这是保证内存数据安全的方式】
- 磁盘:Hbase将数据从内存写入HDFS,由HDFS的保障机制来保证磁盘数据安全
知识点06:HBASE中的对象概念
0、NoSQL数据库与RDBMS数据库
-
RDBMS:一般是为了解决数据管理问题
- 数据安全性高、支持事务特性、数据量比较小、数据相对比较差
- MySQL、Oracle……
- 都支持SQL语句,存储固定的行列数据
- 数据库、表、行、列
-
NoSQL:一般是为了解决性能问题
-
数据安全性相对没有那么高、不支持完善是事务,数据量比较大、性能比较高
-
Hbase、Redis、MongoDB……
-
都不支持SQL语句,存储的数据也有固定的格式
-
每种数据库都有自己的API方式
-
1、数据库设计
-
NameSpace:命名空间,类似于MySQL中的数据库概念,Namespace中有多张表,Hbase中可以有多个Namespace
-
直接把它当做数据库来看
-
Hbase自带了两个Namespace
- default:默认自带的namespace
- hbase:存储系统自带的数据表
-
注意
-
Hbase中的每张表都必须属于某一个Namespace,将namespace当做表名的一部分
-
如果在对表进行读写时,必须加上namespace:tbname方式来引用
-
例如:namespace叫做itcast,里面有一张表叫做heima
itcast:heima
-
-
如果不加namesp引用表的操作,这张表就默认为default的namespace下的表
heima
-
-
2、数据表设计
-
Table:表,Hbase中的每张表都必须属于某一个Namespace
-
注意:在访问表时,如果这张表不在default的namespace下面,必须加上namespace:表名的方式来引用
- Hbase中的表时分布式结构,写入Hbase表的数据,会分布式存储到多台机器上
-
知识点07:HBASE中的存储概念
1、数据行设计
- Rowkey:行健,这个概念是整个Hbase的核心,类似于MySQL主键的概念
- MySQL主键:可以没有,唯一标记一行、作为主键索引
- Hbase行健:自带行健这一列【行健这一列的值由用户自己设计】,唯一标识一行,作为Hbase表中的唯一索引
- Hbase整个数据存储都是按照Rowkey实现数据存储的
2、列族设计
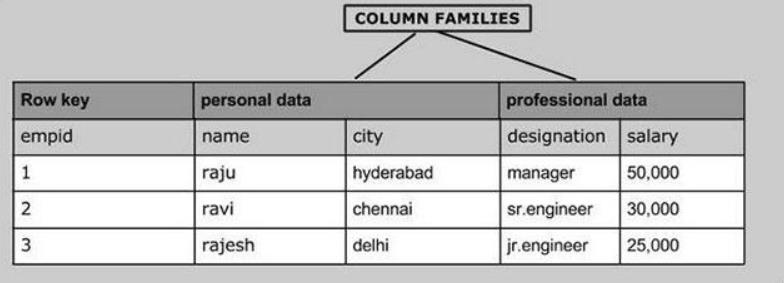
-
ColumnFamily:列族,对除了Rowkey以外的列进行分组,将列划分不同的组中
-
注意:任何一张Hbase的表,都至少要有一个列族,除了Rowkey以外的任何一列,都必须属于某个列族,Rowkey不属于任何一个列族
-
分组:将拥有相似IO属性的列放入同一个列族【要读一起读,要写一起写】
-
原因:划分列族,读取数据时可以加快读取的性能
-
如果没有列族:找一个人,告诉你这个人就在这栋楼
-
如果有了列族:找一个人,告诉你这个人在这栋楼某个房间
-
-
3、数据列设计
-
Column:列,与MySQL中的列是一样
-
注意
-
Hbase除了rowkey以外的任何一列都必须属于某个列族,引用列的时候,必须加上列族
- 如果有一个列族:basic
- 如果basic列族中有两列:name,age
basic:name basic:age -
Hbase中每一行拥有的列是可以不一样的
- 每个Rowkey可以拥有不同的列
-
-
4、版本设计
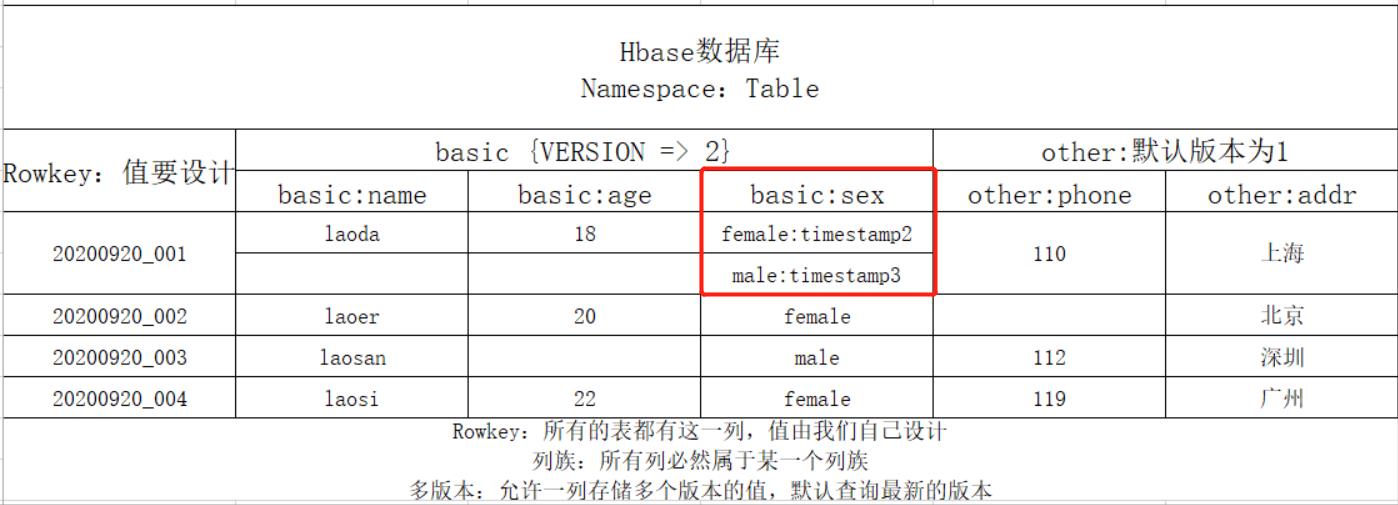
-
功能:某一行的任何一列存储时,只能存储一个值,Hbase可以允许某一行的某一列存储多个版本的值的
-
级别:列族级别,指定列族中的每一列最多存储几个版本的值,来记录值的变化的
-
区分:每一列的每个值都会自带一个时间戳,用于区分不同的版本
- 默认情况下查询,根据时间戳返回最新版本的值
5、分布式设计
-
Hbase的表如何实现分布式设计
-
Region:分区,Hbase中任何一张都可以有多个分区,数据存储在表的分区中,每个分区存储在不同的机器上
- 非常类似于HDFS中Block的概念
- 划分规则:范围分区
-
HDFS设计
- 文件夹
- 文件
- 划分Block:根据每128M划分一个块
- 每个Block存储在不同的机器上

-
Hbase设计
- Namespace
- Table:分布式表
- 划分Region/Part
- 存储在不同的机器上:RegionServer
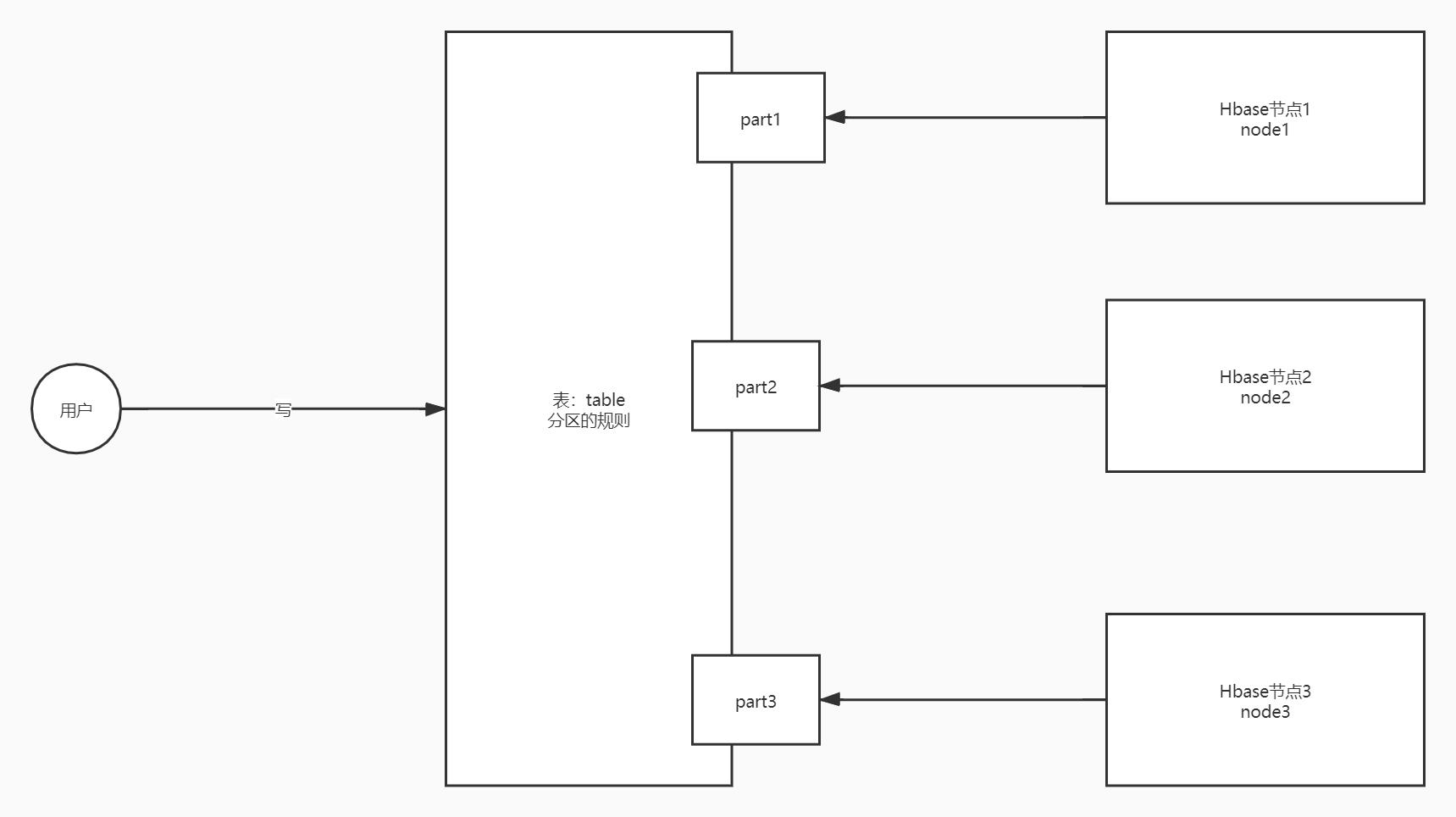
-
对比
分布式概念 HDFS Hbase 对象 目录 + 文件 Namespace + Table 分布式 Block Region 划分规则 按照大小划分:128M 按照范围划分
6、概念对比
| 概念 | MySQL | Hbase |
|---|---|---|
| 数据库 | DataBase | NameSpace |
| 数据表 | Table | Table【分布式的】 |
| 数据分区 | - | Region |
| 数据行 | 主键+其他列 | Rowkey+其他列 |
| 列族 | - | ColumnFamily |
| 数据列 | 普通列与对应的值 | 列【timestamp】与对应的值【支持多版本】 |
知识点08:HBASE中的按列存储
1、功能
- Hbase的最小操作单元是列,不是行,可以实现对每一行的每一列进行读写
2、问题
- Hbase性能很好原因
- 读写内存
- 思考问题:依旧存在一定的概率会读HDFS文件,怎么能让读文件依旧很快?
- 列族的设计:加快数据的读取性能
- Rowkey构建索引,基于有序的文件数据
- 按列存储
3、设计
- MySQL:按行存储,最小的操作单元是行
- insert:插入一行
- delete:删除一行
- ……
- Hbase:按列存储,最小操作单元是列
- 插入:为某一行插入一列
- 读取:只读某一行的某一列的
- 删除:只删除这一行的某一列
4、举例
- MySQL中读取数据
- 查询【id,name,age,addr,phone……100列,每一列10M】:select id from table ;
- 先找到所有符合条件的行,将整行的数据所有列全部读取:1000M数据
- 再过滤id这一列:10M
- 查询【id,name,age,addr,phone……100列,每一列10M】:select id from table ;
- Hbase中读取数据
- 查询【id,name,age,addr,phone……100列,每一列10M】:select id from table ;
- 直接对每一行读取这一列的数据:10M
5、总结
-
思想:通过细化了操作的颗粒度,来提高读的性能
-
如果按行存储:找一个人,告诉你这个人就在这栋楼某个房间的某一排
-
如果按列存储:找一个人,告诉你这个人在这栋楼某个房间的某一排的某一列
知识点09:HBASE集群架构
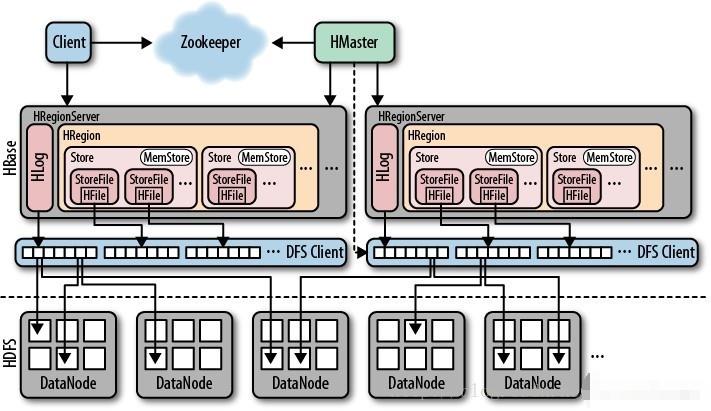
1、分布式主从架构
-
Hbase集群:分布式架构集群,主从架构
-
HMaster:主节点:管理节点
- 负责所有从节点的管理
- 负责元数据的管理
-
HRegionServer:从节点:存储节点
- 负责存储每张表的数据:Region
- Region存储在RegionServer中
- 对外提供Region的读写请求
- 用于构建分布式内存:每台RegionServer有10GB内存存储空间,100台RegionServer
- Hbase可以存储的总内存空间:1000G
- 数据写入Hbase,先进入分布式内存
2、HDFS的设计
-
如果HRegionServer的内存达到一定阈值,就会将内存中的数据写入HDFS,实现数据持久化存储
-
用于存储冷数据的:大部分的数据都在HDFS中
3、Zookeeper的设计
- Zookeeper在大数据工具中的作用
- 功能一:用于存储元数据:Hbase、Kafka……
- 功能二:用于解决主节点的单点故障问题HA,辅助选举Active的Master
知识点10:集群部署【自己部署】
1、解压安装
-
上传HBASE安装包到第一台机器的/export/software目录下
cd /export/software/ -
解压安装
tar -zxvf hbase-2.1.0.tar.gz -C /export/server/ cd /export/server/hbase-2.1.0/
2、修改配置
-
切换到配置文件目录下
cd /export/server/hbase-2.1.0/conf/ -
修改hbase-env.sh
#28行 export JAVA_HOME=/export/server/jdk1.8.0_241 #125行 export HBASE_MANAGES_ZK=false -
修改hbase-site.xml
cd /export/server/hbase-2.1.0/ mkdir datas vim conf/hbase-site.xml<property > <name>hbase.tmp.dir</name> <value>/export/server/hbase-2.1.0/datas</value> </property> <property > <name>hbase.rootdir</name> <value>hdfs://node1:8020/hbase</value> </property> <property > <name>hbase.cluster.distributed</name> <value>true</value> </property> <property> <name>hbase.zookeeper.quorum</name> <value>node1:2181,node2:2181,node3:2181</value> </property> -
修改regionservers
vim conf/regionserversnode1 node2 node3 -
配置环境变量
vim /etc/profile#HBASE_HOME export HBASE_HOME=/export/server/hbase-2.1.0 export PATH=:$PATH:$HBASE_HOME/binsource /etc/profile
3、分发启动
-
分发
cd /export/server/ scp -r hbase-2.1.0 node2:$PWD scp -r hbase-2.1.0 node3:$PWD -
启动
-
step1:启动HDFS
start-dfs.sh -
step2:启动ZK
/export/server/zookeeper-3.4.6/bin/start-zk-all.sh #!/bin/bash ZK_HOME=/export/server/zookeeper-3.4.6 for number in {1..3} do host=node${number} echo ${host} /usr/bin/ssh ${host} "cd ${ZK_HOME};source /etc/profile;${ZK_HOME}/bin/zkServer.sh start" echo "${host} started" done -
step3:启动Hbase
start-hbase.sh
-
-
关闭
stop-hbase.sh
4、测试
-
访问Hbase Web UI
node1:16010 Apache Hbase 1.x之前是60010,1.x开始更改为16010 CDH版本:一直使用60010
5、搭建Hbase HA
-
关闭Hbase所有节点
stop-hbase.sh -
创建并编辑配置文件
vim conf/backup-mastersnode2 -
启动Hbase集群
6、测试HA
-
启动两个Master,强制关闭Active Master,观察StandBy的Master是否切换为Active状态
-
【测试完成以后,删除配置,只保留单个Master模式】
知识点11:集群部署【导入虚拟机】
-
参考虚拟机导入文档,实现虚拟机导入配置
-
所有软件的安装目录
/export/server
知识点12:HBASE集群测试
1、启动Hbase Shell
hbase shell
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-j3OUucRa-1627099407310)(20210316_分布式NoSQL列存储数据库Hbase(一).assets/image-20210316180046440.png)]
2、查看帮助命令
help
3、创建NameSpace
create_namespace 'itcast'

4、创建Table
create 'itcast:heima',{NAME =>'cf1',VERSIONS=> 3},{NAME =>'cf2'}
5、插入数据
#往itcast:heima表中的这一行20210301_001中插入一列cf1列族下,插入name这一列,列的值为laoda
put 表名 rowkey 列族:列 值
put 'itcast:heima','20210301_001','cf1:name','laoda'
put 'itcast:heima','20210301_001','cf1:age',20
put 'itcast:heima','20210301_001','cf2:phone','110'
put 'itcast:heima','20210201_002','cf1:name','laoer'
put 'itcast:heima','20210201_002','cf2:phone','120'
put 'itcast:heima','20210301_003','cf1:name','laosan'
6、查询数据
scan 'itcast:heima'
练习作业
1、简答题
- 简述Hbase的功能、应用场景及其设计思想
- 简述NameSpace、Table、Rowkey、ColumnFamily、VERSIONS概念的含义及与MySQL中概念的区别
- 简述Hbase集群的架构组成及角色功能
2、操作题
创建Table
create 'itcast:heima',{NAME =>'cf1',VERSIONS=> 3},{NAME =>'cf2'}
5、插入数据
#往itcast:heima表中的这一行20210301_001中插入一列cf1列族下,插入name这一列,列的值为laoda
put 表名 rowkey 列族:列 值
put 'itcast:heima','20210301_001','cf1:name','laoda'
put 'itcast:heima','20210301_001','cf1:age',20
put 'itcast:heima','20210301_001','cf2:phone','110'
put 'itcast:heima','20210201_002','cf1:name','laoer'
put 'itcast:heima','20210201_002','cf2:phone','120'
put 'itcast:heima','20210301_003','cf1:name','laosan'
6、查询数据
scan 'itcast:heima'
练习作业
1、简答题
- 简述Hbase的功能、应用场景及其设计思想
- 简述NameSpace、Table、Rowkey、ColumnFamily、VERSIONS概念的含义及与MySQL中概念的区别
- 简述Hbase集群的架构组成及角色功能
2、操作题
- 基于知识点11,导入虚拟机并测试Hbase集群读写成功
以上是关于分布式NoSQL列存储数据库HbaseHbase的功能与应用场景基本设计思想的主要内容,如果未能解决你的问题,请参考以下文章