主流 NoSQL 数据库对比
Posted Mars亟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了主流 NoSQL 数据库对比相关的知识,希望对你有一定的参考价值。
HBase
HBase 是 Apache Hadoop 中的一个子项目,属于 bigtable 的开源版本,所实现的语言为Java(故依赖 Java SDK)。HBase 依托于 Hadoop 的 HDFS(分布式文件系统)作为最基本存储基础单元。
HBase在列上实现了 BigTable 论文提到的压缩算法、内存操作和布隆过滤器。HBase的表能够作为 MapReduce任务的输入和输出,可以通过Java API来访问数据,也可以通过REST、Avro或者Thrift的API来访问。
1. 特点
1.1 数据格式
HBash 的数据存储是基于列(ColumnFamily)的,且非常松散—— 不同于传统的关系型数据库(RDBMS),HBase 允许表下某行某列值为空时不做任何存储(也不占位),减少了空间占用也提高了读性能。
不过鉴于其它NoSql数据库也具有同样灵活的数据存储结构,该优势在本次选型中并不出彩。
我们以一个简单的例子来了解使用 RDBMS 和 HBase 各自的解决方式:
⑴ RDBMS方案:
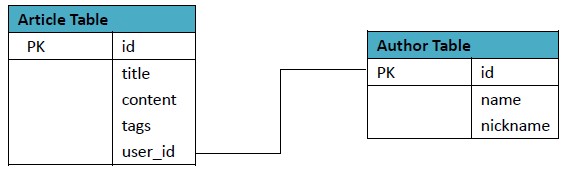
其中Article表格式:
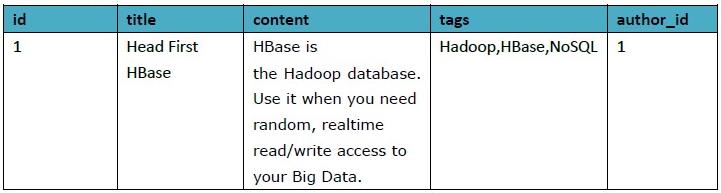
Author表格式:

⑵ 等价的HBase方案:

对于前端而言,这里的 Column Keys 和 Column Family 可以看为这样的关系:
|
1
2
3
4
5
6
7
8
9
10
11
|
columId1 = { //id=1的行
article: { //ColumnFamily-article
title: XXX, //ColumnFamily-article下的key之一
content: XXX,
tags: XXX
},
author: { //ColumnFamily-author
name: XXX
nickname: XXX
}
}
|
1.2 性能
HStore存储是HBase存储的核心,它由两部分组成,一部分是MemStore,一部分是StoreFiles。
MemStore 是 Sorted Memory Buffer,用户写入的数据首先会放入MemStore,当MemStore满了以后会Flush成一个StoreFile(底层实现是HFile),当StoreFile文件数量增长到一定阈值,会触发Compact合并操作,将多个StoreFiles合并成一个StoreFile,合并过程中会进行版本合并和数据删除,因此可以看出HBase其实只有增加数据,所有的更新和删除操作都是在后续的compact过程中进行的,这使得用户的写操作只要进入内存中就可以立即返回,保证了HBase I/O的高性能。
1.3 数据版本
Hbase 还能直接检索到往昔版本的数据,这意味着我们更新数据时,旧数据并没有即时被清除,而是保留着:
Hbase 中通过 row+columns 所指定的一个存贮单元称为cell。每个 cell都保存着同一份数据的多个版本——版本通过时间戳来索引。
时间戳的类型是 64位整型。时间戳可以由Hbase(在数据写入时自动 )赋值,此时时间戳是精确到毫秒的当前系统时间。时间戳也可以由客户显式赋值。如果应用程序要避免数据版本冲突,就必须自己生成具有唯一性的时间戳。每个 cell中,不同版本的数据按照时间倒序排序,即最新的数据排在最前面。
为了避免数据存在过多版本造成的的管理 (包括存贮和索引)负担,Hbase提供了两种数据版本回收方式。一是保存数据的最后n个版本,二是保存最近一段时间内的版本(比如最近七天)。用户可以针对每个列族进行设置。
2. Node下的使用
HBase的相关操作可参考下表:
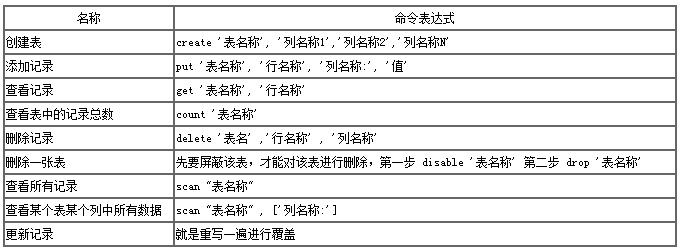
在node环境下,可通过 node-hbase 来实现相关访问和操作,注意该工具包依赖于 PHYTHON2.X(3.X不支持)和Coffee。
如果是在 window 系统下还需依赖 .NET framwork2.0,64位系统可能无法直接通过安装包安装。
官方示例:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
var assert = require(\'assert\');
var hbase = require(\'hbase\');
hbase({ host: \'127.0.0.1\', port: 8080 })
.table(\'my_table\' )
//创建一个Column Family
.create(\'my_column_family\', function(err, success){
this.row(\'my_row\') //定位到指定行
.put(\'my_column_family:my_column\', \'my value\', function(err, success){
this.get(\'my_column_family\', function(err, cells){
this.exists(function(err, exists){
assert.ok(exists);
});
});
});
});
|
数据检索:
|
1
2
3
4
5
6
7
8
|
client
.table(\'node_table\')
.scan({
startRow: \'my_row\', //起始行
maxVersions: 1 //版本
}, function(err, rows){
console.log(err, rows);
});
|
另有 hbase-client 也是一个不错的选择,具体API参照其文档。
3. 优缺点
优势
1. 存储容量大,一个表可以容纳上亿行,上百万列;
2. 可通过版本进行检索,能搜到所需的历史版本数据;
3. 负载高时,可通过简单的添加机器来实现水平切分扩展,跟Hadoop的无缝集成保障了其数据可靠性(HDFS)和海量数据分析的高性能(MapReduce);
4. 在第3点的基础上可有效避免单点故障的发生。
缺点
1. 基于Java语言实现及Hadoop架构意味着其API更适用于Java项目;
2. node开发环境下所需依赖项较多、配置麻烦(或不知如何配置,如持久化配置),缺乏文档;
3. 占用内存很大,且鉴于建立在为批量分析而优化的HDFS上,导致读取性能不高;
4. API相比其它 NoSql 的相对笨拙。
适用场景
1. bigtable类型的数据存储;
2. 对数据有版本查询需求;
3. 应对超大数据量要求扩展简单的需求。
Redis
Redis 是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。目前由VMware主持开发工作。
1. 特点
1.1 数据格式
Redis 通常被称为数据结构服务器,因为值(value)可以是 字符串(String), 哈希(Hash/Map), 列表(list), 集合(sets) 和 有序集合(sorted sets)五种类型,操作非常方便。比如,如果你在做好友系统,查看自己的好友关系,如果采用其他的key-value系统,则必须把对应的好友拼接成字符串,然后在提取好友时,再把value进行解析,而redis则相对简单,直接支持list的存储(采用双向链表或者压缩链表的存储方式)。
我们来看下这五种数据类型。
⑴ String
- string 是 Redis 最基本的类型,你可以理解成与 Memcached 一模一样的类型,一个key对应一个value。
- string 类型是二进制安全的。意思是 Redis 的 string 可以包含任何数据。比如 jpg 图片或者序列化的对象 。
- string 类型是 Redis 最基本的数据类型,一个键最大能存储512MB。
实例:
|
1
2
3
4
|
redis 127.0.0.1:6379> SET name zfpx
OK
redis 127.0.0.1:6379> GET name
"zfpx"
|
在以上实例中我们使用了 Redis 的 SET 和 GET 命令。键为 name,对应的值为”zfpx”。 注意:一个键最大能存储512MB。
⑵ Hash
- Redis hash 是一个键值对集合。
- Redis hash 是一个 string 类型的 field 和 value 的映射表,hash 特别适合用于存储对象。
实例:
|
1
2
3
4
5
6
7
|
redis 127.0.0.1:6379> HMSET user:1 username zfpx password 123
OK
redis 127.0.0.1:6379> HGETALL user:1
1) "username"
2) "zfpx"
3) "password"
4) "123"
|
以上实例中 hash 数据类型存储了包含用户脚本信息的用户对象。 实例中我们使用了 Redis HMSET, HGETALL 命令,user:1 为键值。 每个 hash 可以存储 232 – 1 键值对(40多亿)。
⑶ List
Redis 列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素导列表的头部(左边)或者尾部(右边)。
实例:
|
1
2
3
4
5
6
7
8
9
10
|
redis 127.0.0.1:6379> lpush name zfpx1
(integer) 1
redis 127.0.0.1:6379> lpush name zfpx2
(integer) 2
redis 127.0.0.1:6379> lpush name zfpx3
(integer) 3
redis 127.0.0.1:6379> lrange name 0 -1
1) "zfpx3"
2) "zfpx2"
3) "zfpx1"
|
列表最多可存储 232 – 1 元素 (4294967295, 每个列表可存储40多亿)。
⑷ Sets
Redis的Set是string类型的无序集合。 集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是O(1)。
添加一个string元素到 key 对应的 set 集合中,成功返回1,如果元素已经在集合中返回0,key对应的set不存在返回错误,指令格式为
|
1
|
sadd key member
|
实例:
|
1
2
3
4
5
6
7
8
9
10
11
12
|
redis 127.0.0.1:6379> sadd school zfpx1
(integer) 1
redis 127.0.0.1:6379> sadd school zfpx1
(integer) 0
redis 127.0.0.1:6379> sadd school zfpx2
(integer) 1
redis 127.0.0.1:6379> sadd school zfpx2
(integer) 0
redis 127.0.0.1:6379> smembers school
1) "zfpx1"
2) "zfpx2"
|
注意:以上实例中 zfpx1 添加了两次,但根据集合内元素的唯一性,第二次插入的元素将被忽略。 集合中最大的成员数为 232 – 1 (4294967295, 每个集合可存储40多亿个成员)。
⑸ sorted sets/zset
Redis zset 和 set 一样也是string类型元素的集合,且不允许重复的成员。 不同的是每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序。
zset的成员是唯一的,但分数(score)却可以重复。可以通过 zadd 命令(格式如下) 添加元素到集合,若元素在集合中存在则更新对应score
|
1
|
zadd key score member
|
实例:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
redis 127.0.0.1:6379> zadd school 0 zfpx1
(integer) 1
redis 127.0.0.1:6379> zadd school 2 zfpx2
(integer) 1
redis 127.0.0.1:6379> zadd school 0 zfpx3
(integer) 1
redis 127.0.0.1:6379> zadd school 1 zfpx4
(integer) 0
redis 127.0.0.1:6379> ZRANGEBYSCORE school 0 100
1) "zfpx1"
2) "zfpx3"
3) "zfpx4"
4) "zfpx2"
|
1.2 性能
Redis数据库完全在内存中,因此处理速度非常快,每秒能执行约11万集合,每秒约81000+条记录(测试数据的可参考这篇《Redis千万级的数据量的性能测试》)。
Redis的数据能确保一致性——所有Redis操作是原子性(Atomicity,意味着操作的不可再分,要么执行要么不执行)的,这保证了如果两个客户端同时访问的Redis服务器将获得更新后的值。
1.3 持久化
通过定时快照(snapshot)和基于语句的追加(AppendOnlyFile,aof)两种方式,redis可以支持数据持久化——将内存中的数据存储到磁盘上,方便在宕机等突发情况下快速恢复。
1.4 CAP类别
属于CP类型(了解更多)。
2. Node下的使用
node 下可使用 node_redis 来实现 redis 客户端操作:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
var redis = require("redis"),
client = redis.createClient();
// if you\'d like to select database 3, instead of 0 (default), call
// client.select(3, function() { /* ... */ });
client.on("error", function (err) {
console.log("Error " + err);
});
client.set("string key", "string val", redis.print);
client.hset("hash key", "hashtest 1", "some value", redis.print);
client.hset(["hash key", "hashtest 2", "some other value"], redis.print);
client.hkeys("hash key", function (err, replies) {
console.log(replies.length + " replies:");
replies.forEach(function (reply, i) {
console.log(" " + i + ": " + reply);
});
client.quit();
});
|
3. 优缺点
优势
1. 非常丰富的数据结构;
2. Redis提供了事务的功能,可以保证一串 命令的原子性,中间不会被任何操作打断;
3. 数据存在内存中,读写非常的高速,可以达到10w/s的频率。
缺点
1. Redis3.0后才出来官方的集群方案,但仍存在一些架构上的问题(出处);
2. 持久化功能体验不佳——通过快照方法实现的话,需要每隔一段时间将整个数据库的数据写到磁盘上,代价非常高;而aof方法只追踪变化的数据,类似于mysql的binlog方法,但追加log可能过大,同时所有操作均要重新执行一遍,恢复速度慢;
3. 由于是内存数据库,所以,单台机器,存储的数据量,跟机器本身的内存大小。虽然redis本身有key过期策略,但是还是需要提前预估和节约内存。如果内存增长过快,需要定期删除数据。
适用场景
适用于数据变化快且数据库大小可遇见(适合内存容量)的应用程序。更具体的可参照这篇《Redis 的 5 个常见使用场景》译文。
MongoDB
MongoDB 是一个高性能,开源,无模式的文档型数据库,开发语言是C++。它在许多场景下可用于替代传统的关系型数据库或键/值存储方式。
1.特点
1.1 数据格式
在 MongoDB 中,文档是对数据的抽象,它的表现形式就是我们常说的 BSON(Binary JSON )。
BSON 是一个轻量级的二进制数据格式。MongoDB 能够使用 BSON,并将 BSON 作为数据的存储存放在磁盘中。
BSON 是为效率而设计的,它只需要使用很少的空间,同时其编码和解码都是非常快速的。即使在最坏的情况下,BSON格式也比JSON格式再最好的情况下存储效率高。
对于前端开发者来说,一个“文档”就相当于一个对象:
|
1
|
{“name":"mengxiangyue","sex":"nan"}
|
对于文档是有一些限制的:有序、区分大小写的,所以下面的两个文档是与上面不同的:
|
1
2
|
{”sex“:"nan","name":"mengxiangyue"}
{"Name":"mengxiangyue","sex":"nan"}
|
另外,对于文档的字段 MongoDB 有如
以上是关于主流 NoSQL 数据库对比的主要内容,如果未能解决你的问题,请参考以下文章