给我爬!3天掌握Scrapy
Posted 二哥不像程序员
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了给我爬!3天掌握Scrapy相关的知识,希望对你有一定的参考价值。
大家好,欢迎来到二哥的爬虫频道,本次二哥准备爆更三天给大家带来Scrapy教程,记得三连呦~
一、认识Scrapy
Scrapy是一个为了爬取网站数据,提供结构性数据而编写的应用框架,使用Scrapy时,我们使用少量的代码就能实现快速的抓取。
Scrapy爬取流程
Scrapy的爬取流程图如下所示:
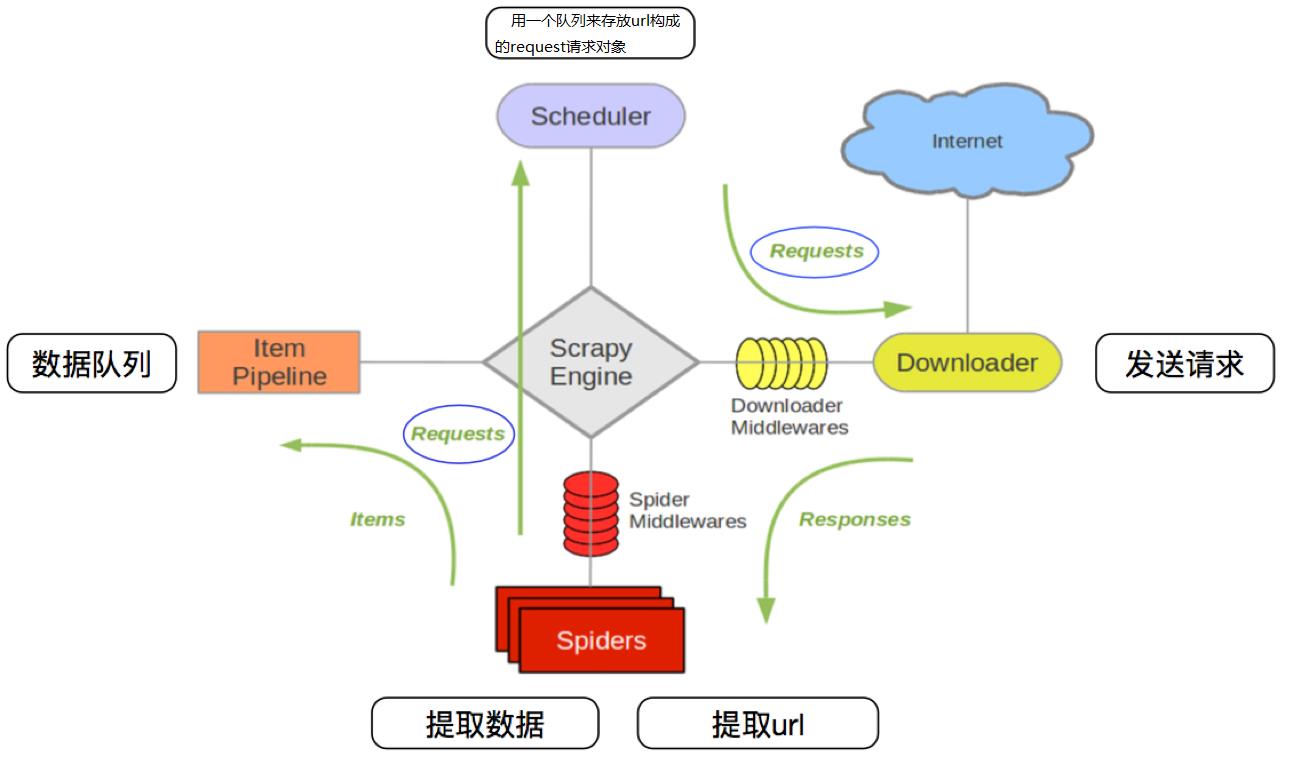
Scrapy的三个重要内置对象
- request请求对象
- response响应对象
- item数据对象
流程图解释
- 引擎(Scrapy Engine):负责数据和信号在整个系统中的传递(核心)
- 调度器(Scheduler):实现一个队列,存放引擎发过来的requests请求对象
- 下载器(Downloader):发送引擎发过来的requests请求,下载网页内容, 并将网页内容返回
- 爬虫(Spider):处理引擎发过来的response,提取自己想要的信息;提取url,并交给引擎
- 管道(Pipeline):处理引擎传递过来的数据,进行数据持久化(例:存储数据到表格/数据库中)
- 下载中间件(Downloader Middleware):可以自定义的下载扩展,比如设置User_Agent, Proxy
- 爬虫中间件(Spider Middleware):可以自定义request请求和进行response过滤,类似下载中间件
Scrapy的工作流程如下
- 爬虫——>URL(Requests)——> 爬取中间件——>引擎——>调度器
对应图中(中间的绿色直线):Spiders将需要发送请求的Requests经过ScrapyEngine交给Scheduler
- 调度器——>Requests——>引擎——>下载中间件——>下载器
对应图中(右上角的绿色线):Scheduler处理后经过ScrapyEngine,Downloader Middlewares交给Downloader
- 下载器——>Reponses——>下载中间件——>引擎——>爬虫中间件——爬虫
对应图中(右下角的绿色线):Downloader向互联网发送请求,接收Reponses后经过ScrapyEngine,Spider Middlewares交给Spiders
- 爬虫——>Reponses——>引擎——>管道(保存数据)
Spiders处理返回到的Reponses,提取数据将数据通过ScrapyEngine交给ItemPipeline进行数据保存
- 当新的URL请求出现时,重复执行1234的过程,知道没有请求。
二、使用Scrapy
创建Scrapy项目
- 安装模块:pip install scrapy
- 创建Scrapy项目:scrapy startproject 文件夹名称
创建完成后会生成如下图所示的文件目录:
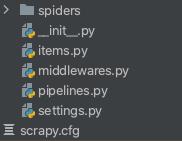
- scrapy.cfg:项目的配置文件
- items.py:项目的目标文件
- pipelines.py:项目的管道文件
- settings.py:项目的设置文件
- spiders:存储爬虫代码
创建爬虫
创建好了项目之后,我们还需要创建爬虫让我们能够在里面编写爬虫代码,步骤如下。
- cd到创建的文件夹下
- 执行:scrapy genspider +<爬虫名字> + <爬取的域名>
举例:
cd Sp_1
scrapy genspider Cars_data 12365auto.com
执行完成后会在spiders文件夹下出现爬虫文件,文件内的格式如下:
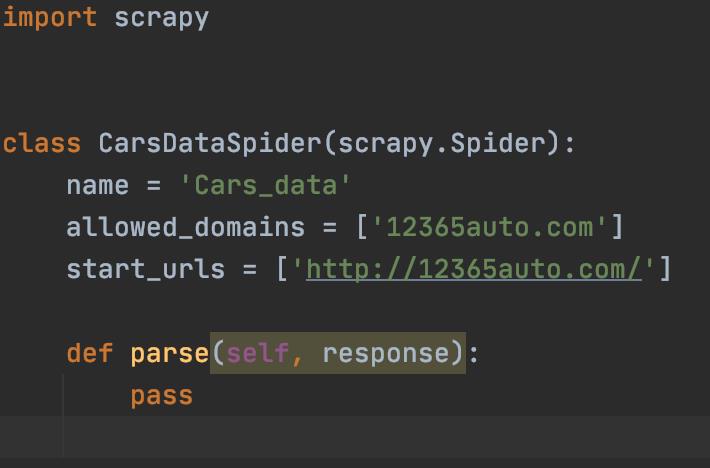
编写爬虫
至此我们的准备工作就做好了,接下来就可以开始完善爬虫了。
完善代码(这里举一个最简单的小例子)
import scrapy
class CarsDataSpider(scrapy.Spider):
name = 'Cars_data'
allowed_domains = ['12365auto.com']
start_urls = ['http://12365auto.com/']
# 解析数据
def parse(self, response):
name_car = response.xpath(".//div[@class='in_cxsx_b'][1]/div[@class='in_wxc'][1]/dl[1]/dt/a/text()")
item = {}
item['name'] = name_car.extract()
yield item
在进行parse的时候,我们可以直接使用scrapy中的response对象进行Xpath。
需要注意的是response.xpath方法的返回结果是一个类似list的类型,其中包含的是selector对象,操作和列表一样,但是获取结果的时候有一些额外的方法。
extract():返回一个包含有字符串的列表
extract_first():返回列表中的第一个字符串,列表为空没有返回None
代码最后需要使用yield函数让整个函数变成一个生成器
此时我们可以尝试进行数据爬取了,在Terminal运行如下命令:
scrapy crawl name
注意:name是你创建爬虫的名字,也就是爬虫文件中name=""中的内容
看到没有报错的长串输出就证明运行成功了。
保存数据
保存数据的时候我们主要会使用pipeline来进行。
- 开启pipeline
找到类似如下的代码取消注释(初始位置在65行左右):
ITEM_PIPELINES = {
'Sp_1.pipelines.Sp1Pipeline': 300,
}
- 运行
最终在terminal中运行如下脚本即可保存文件为Json
scrapy crawl dmoz -o items.json

以上是关于给我爬!3天掌握Scrapy的主要内容,如果未能解决你的问题,请参考以下文章