爬虫入门(给我爬!快!)
Posted mid2dog
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫入门(给我爬!快!)相关的知识,希望对你有一定的参考价值。
前言
小小爬虫,我……我特喵这是什么好玩的东西!

520,python陪我过,淦。
你好,我是你亲友为你点的520祝福青蛙,现在我要开始叫了:寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡寡

导入库
import requests
from bs4 import BeautifulSoup
伪装头
headers = 'user-agent': 'Mozilla/5.0'
爬取主体部分
从豆瓣网看,第一页start的参数是0,第二页参数是从25开始

由此可知,这应该是每一页开头所代表的第一个电影编号。
所以我们只要用for循环就能弄出所有页的电影咯
当然在for循环之前我们先找好存储数据的地方,用一个列表来存储。
movie_list = []
TOP250,每页25条,十页,所以是十个循环
for i in range(0,10):
link = 'https://movie.douban.com/top250?start=' + str(i * 25)
r.encoding = r.apparent_encoding#防止中文乱码
r = requests.get(link, headers=headers, timeout= 10) #请求页面,获取信息
soup = BeautifulSoup(r.text, "lxml")#熬成soup(解析)
然后我们可以从网页代码中看到需要爬取的内容在class=info的里面
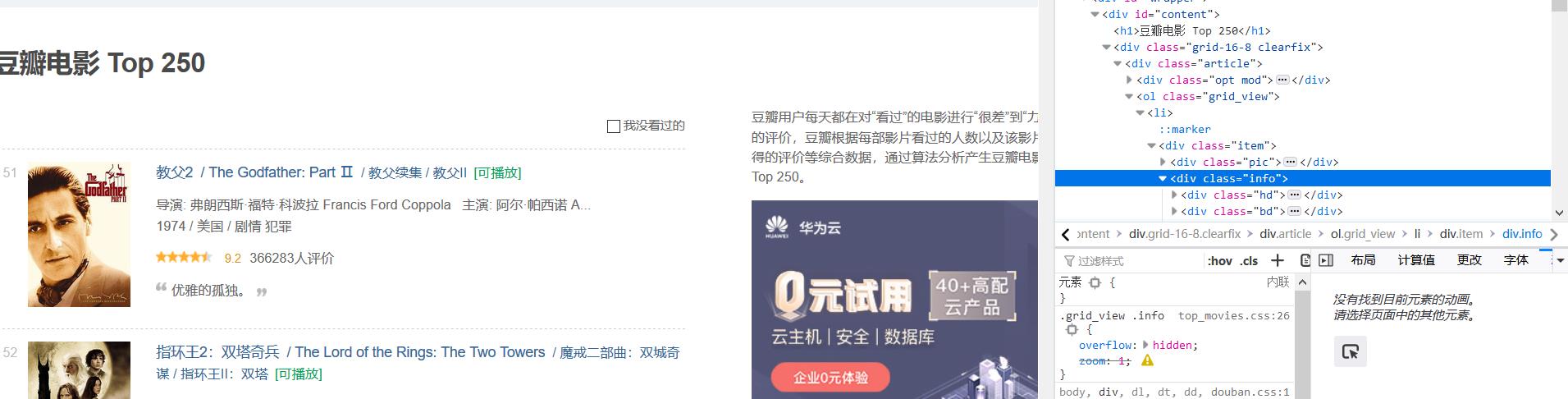
同时在标签 div中
所以就可以用find_all函数来直接指向这里
div_list = soup.find_all('div', class_='info')
而我们可以看到,有很多个这样的标签,每一个都代表所存的电影信息
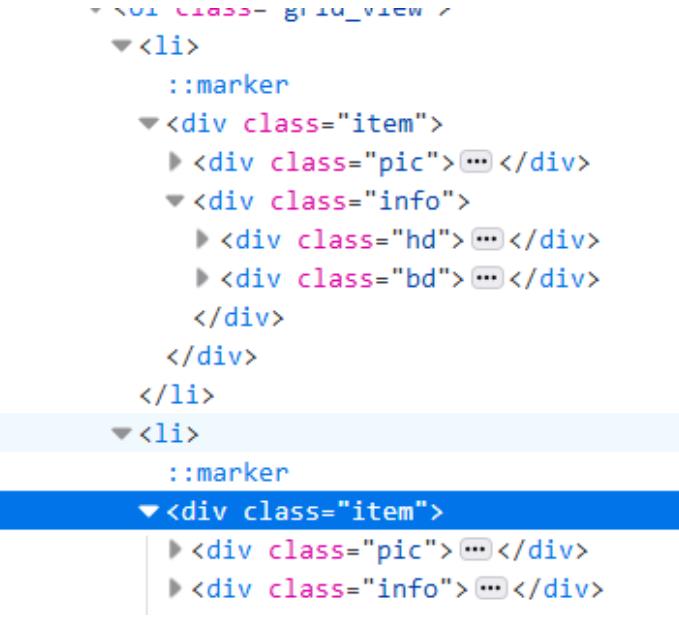
所以实际上我们爬取得到的div_list实际上是一个列表!
里面每一个电影的所有信息都以一个个列表内容存储,如果我们需要每一个都提取出来,就需要遍历这个列表。来个for循环吧!
for each in div_list:
提取标题
title = each.find('div', class_='hd').a.span.text.strip()

这代码意思就是找到class=”hd“,因为标题内容在class=“hd"里面。
然后往下就等于找一棵树的子节点,下面a和span都是标签名
然后.text是提取text中的内容,也就是我们要的标题内容。
同理,爬取导演主演那一堆。。
info = each.find('div', class_='bd').p.text.strip()
但这时候运行会出现一些问题
出现了很多\\xa0

\\xa0表示不间断空白符
我们可以用这条语句将这些东西都转变成空格
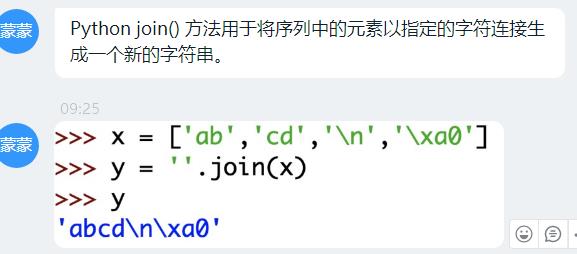
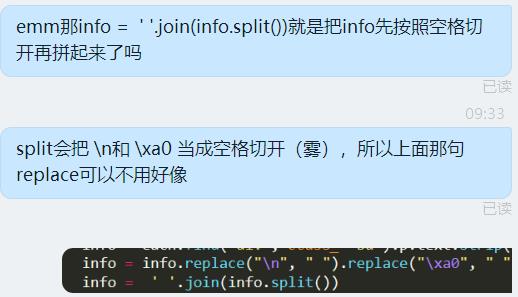
info = info.replace("\\n", " ").replace("\\xa0", " ")
然后再用info = ’ '.join(info.split())组合起来,这样就去掉了多的空格
不过慎用,因为这会去掉所有空格。
但在实践的过程中发现,不用写替换语句,直接写info = ’ '.join(info.split())得到的效果和加上替换语句的效果相同。。。
似乎是split功能过于强大把\\n和\\xa0直接去掉了?好霸道。
汲取一波营养!
同理获取剩下的一些评分和人数什么的
rating = each.find(‘span’, class_=‘rating_num’).text.strip()
num_rating = each.find(‘div’, class_=‘star’).contents[7].text.strip()
什么?你问我为什么是contents[7]?

数这个<>
同理如果contents[3]的话就是评分9.7,嗯哼
然后是评语
try:
quote = each.find('span', class_='inq').text.strip()
except:
quote = ""
然后就是整合起来了
movie_list.append([title, info, rating, num_rating, quote])
最后存入csv文件(一种神奇的格式,既可以用txt打开又能用表格打开)
记得先导入csv库 import csv
with open('test.csv','w',newline='',encoding='utf-8')as f:
f_csv = csv.writer(f)
for data in movie_list:
f_csv.writerow(data)
乱码可以用notepad打开转成ANSI编码,然后就好嘞。
如果还是乱码加一行这个,详情可见
https://blog.csdn.net/Coding___Man/article/details/86552737
import codecs
with open('test.csv', 'ab+') as fileopen:
fileopen.write(codecs.BOM_UTF8) # 为了防止在windows下直接打开csv文件出现乱码
整体代码如下:
import requests
from bs4 import BeautifulSoup
import codecs
import csv
headers = 'user-agent': 'Mozilla/5.0'
movie_list = []
for i in range(0,10):
link = 'https://movie.douban.com/top250?start=' + str(i * 25)
r = requests.get(link, headers=headers, timeout= 10)
r.encoding = r.apparent_encoding#防止中文乱码
soup = BeautifulSoup(r.text, "lxml")
div_list = soup.find_all('div', class_='info')
for each in div_list:
title = each.find('div', class_='hd').a.span.text.strip()
info = each.find('div', class_='bd').p.text.strip()
info = ' '.join(info.split())
rating = each.find('span', class_='rating_num').text.strip()
num_rating = each.find('div', class_='star').contents[7].text.strip()
try:
quote = each.find('span', class_='inq').text.strip()
except:
quote = ""
movie_list.append([title, info, rating, num_rating, quote])
with open('test.csv', 'ab+') as fileopen:
fileopen.write(codecs.BOM_UTF8) # 为了防止在windows下直接打开csv文件出现乱码
with open('test.csv','w',newline='',encoding='utf-8')as f:
f_csv = csv.writer(f)
for data in movie_list:
f_csv.writerow(data)
print("ok")
效果图:

以上是关于爬虫入门(给我爬!快!)的主要内容,如果未能解决你的问题,请参考以下文章