一文读懂布隆过滤器
Posted 鱼翔空
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一文读懂布隆过滤器相关的知识,希望对你有一定的参考价值。
什么是布隆过滤器?
布隆过滤器(Bloom Filter)是1970年由布隆提出的本质上布隆过滤器是一种数据结构,比较巧妙的概率型数据结构,特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”。
特点:
-
二进制数组+随机hash
-
空间效率和查询效率都优于一般算法 O(1)
-
有一定的误识别率(散列冲突)
-
删除困难(重合)
-
高并发场景下,防止缓存穿透;
数据结构
如何快速定位一个元素是否存在?
我们通过redis的全局hash表或者hashMap就能解决这个问题;
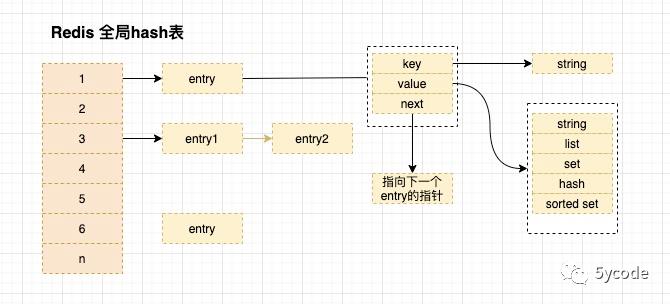
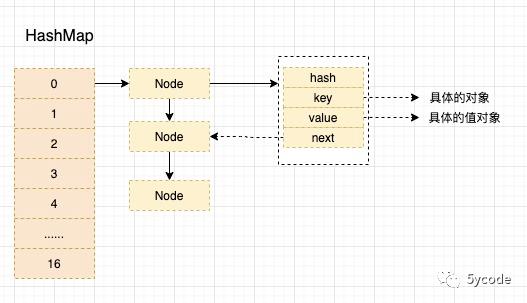
看上面的数据结构,两个数据结构差不多,如果检索的是一个邮箱地址,或者是url,再或者是一个商品id;
我们看下:
-
占用空间大 除了hash,key存储的是具体的值
-
数据结构复杂,引用较多
我们看下布隆过滤器的数据结构:
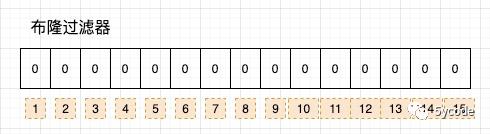
一串1个bit的数组(1,2,3,4 只是标注的辅助理解的)
所以占用的空间为:总数/8/1024/1024(MB)
实现原理
我们看下具体是怎么实现的 当一个元素被加入集合时,通过n个散列函数,将这个元素映射到bit数组中的n个点,并且把对应的位置改为1。
为什么这么做呢?
-
通过散列函数进行hash的时候,会有一定的概率的散列冲突,可以想下为什么hashmap的Node是链表或红黑树;
-
多个散列函数是为了降低冲突,减少误判;
插入:如果散列值对应的位置为0,则改为1,如果已经是1,则不动
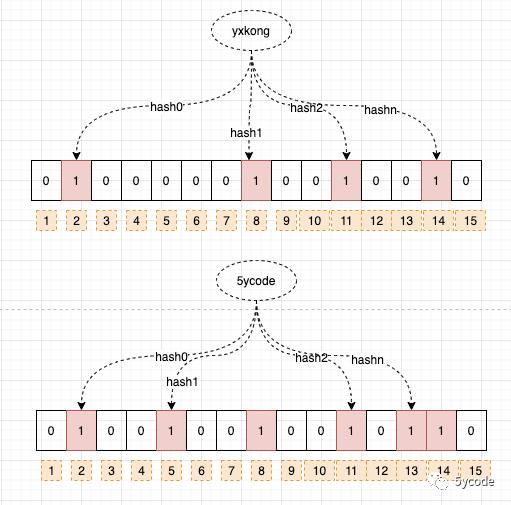
查询: 经过n个散列函数,获取到对应的bit位置,只要有一个不为1,则认为不存在
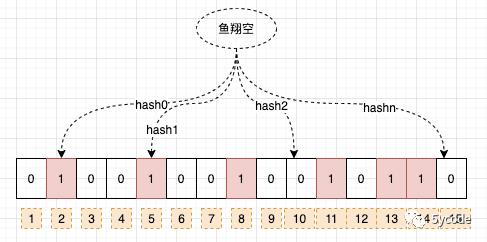
这里就存在一个问题:命中的,不一定存在(可能是别人写的),未命中的一定不存在 这也造成BloomFilter删除一个key很难;
应用案例
-
Google 著名的分布式数据库 Bigtable 使用了布隆过滤器来查找不存在的行或列,以减少磁盘查找的IO次数
-
Squid 网页代理缓存服务器在 cache digests 中使用了也布隆过滤器
-
Venti 文档存储系统也采用布隆过滤器来检测先前存储的数据
-
Google Chrome浏览器使用了布隆过滤器加速安全浏览服务
-
SPIN 模型检测器也使用布隆过滤器在大规模验证问题时跟踪可达状态空间
-
Google Chrome浏览器使用了布隆过滤器加速安全浏览服务
-
高并发情况下,防止缓存穿透
如何使用?
我们在浏览商品的时候,正常逻辑如下:
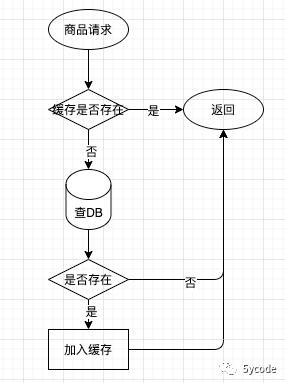
我们会经常遇到如下情况:黑客的DDOS,或者友商的… 然后缓存穿透,直接能把数据库拉垮。
然后我们这么做,根据误判率,我们能将垃圾流量拦截掉(1-误判率)
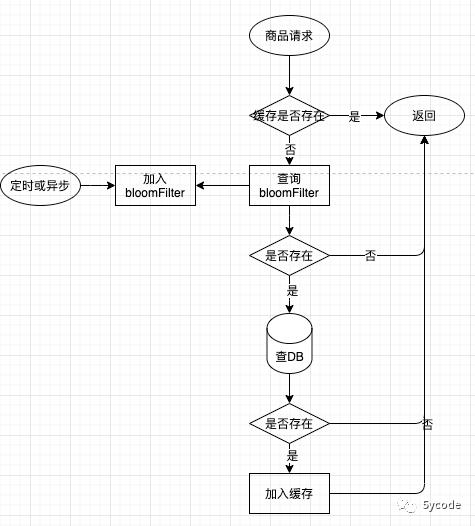
如何实现?
内存实现
guava已经实现了BloomFilter
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>29.0-jre</version>
</dependency>
public class BloomFilterTest {
//布隆过滤器的长度
private int length = 1000000;
private BloomFilter<Integer> bloomFilter;
@Before
public void init(){
//误判率,分别设置 百一 千一 万一
double fpp = 0.001;
bloomFilter = BloomFilter.create(Funnels.integerFunnel(), length, fpp);
}
@Test
public void test(){
for (int i = 0; i < length; i++) {
bloomFilter.put(i);
}
int count = 0;
long start = System.currentTimeMillis();
/**
* 设置size个不在bloomFilter中的值进行测试
*/
int size = 1000;
for (int i = length ; i < length + size; i++) {
if (bloomFilter.mightContain(i)) {
count++;
}
}
System.out.println(String.format("误判的数量:%d", count ));
System.out.println(String.format("执行%d 毫秒", (System.currentTimeMillis()-start)));
}
}
redis实现
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.16.0</version>
</dependency>
public class BloomFilterTest {
//布隆过滤器的长度
private int length = 10000;
private BloomFilter<Integer> bloomFilter;
//误判率,分别设置 百一 千一 万一
private double fpp = 0.001;
@Test
public void redis(){
Config config = new Config();
config.useMasterSlaveServers().setMasterAddress("redis://192.168.161.219:6380");
RedissonClient redisson = Redisson.create(config);
RBloomFilter<String> bloomFilter = redisson.getBloomFilter("bloomFilter");
System.out.println("1");
/**
* 初始化布隆过滤器,并添加所有的元素到过滤器
*/
bloomFilter.tryInit(length,fpp);
System.out.println("2");
for (int i = 0; i < length; i++) {
System.out.println(i);
bloomFilter.add(i+"");
}
System.out.println("3");
int count = 0;
long start = System.currentTimeMillis();
/**
* 设置size个不在bloomFilter中的值进行测试
*/
int size = 1000;
for (int i = length ; i < length + size; i++) {
if (bloomFilter.contains(i+"")) {
count++;
}
}
System.out.println(String.format("误判的数量:%d", count ));
System.out.println(String.format("执行%d 毫秒", (System.currentTimeMillis()-start)));
}
}
建议使用本地内存,1亿的数据内存占用 1亿/8/1024/1024=11.92mb,可以单独做一个bloomfilter的服务,比redis快多了
如何解决不能删除的问题?
-
使用Counting Bloom Filter (将1bit扩展为1字节,可以存127,这就翻了8倍,如果过大会占用空间较多)
-
数据量小:定期创建新的布隆过滤器替换老的
-
数据量大:切片,分成几个布隆过滤器,对应的范围的删除先记录,然后定期创建对应的范围布隆过滤器;
-
不删除,只标记为失效,通过业务逻辑处理,比如商品,命中以后展示时显示已下架;
如果觉得对你有帮助,请关注公众号:5ycode,后续会不断更新哦

以上是关于一文读懂布隆过滤器的主要内容,如果未能解决你的问题,请参考以下文章
布隆过滤器同态加密PKI体系……一文告诉你密码学在区块链中能做什么!
BloomFilter怎么用?使用布隆过滤器来判断key是否存在?