亿万级信令服务演化
Posted anyRTC
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了亿万级信令服务演化相关的知识,希望对你有一定的参考价值。
一、从0到1
2020.7.31 anyRTC的信令服务1.0正式发布,这一天距离项目启动日仅过去1个半月左右。在这么短的时间里我们都做了什么事情?
1,消息流模式
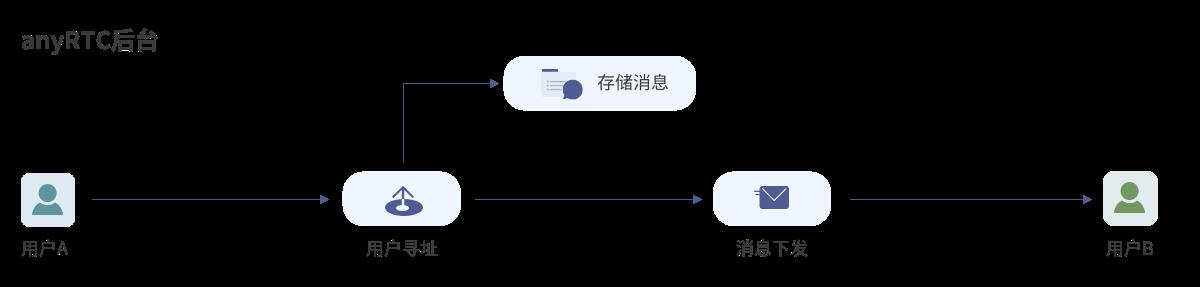
我们的定位就是稳定可靠、低延时、高并发的全球信令服务,与传统的即时通讯(IM)服务不同,信令服务主要构建实时应用场景,更专注于高并发和低延时。
消息流模式是用户A需要向B发送一条消息,首先服务会对B做用户寻址,然后将消息路由到用户B所在区域,最后发送给B。
2,数据协议
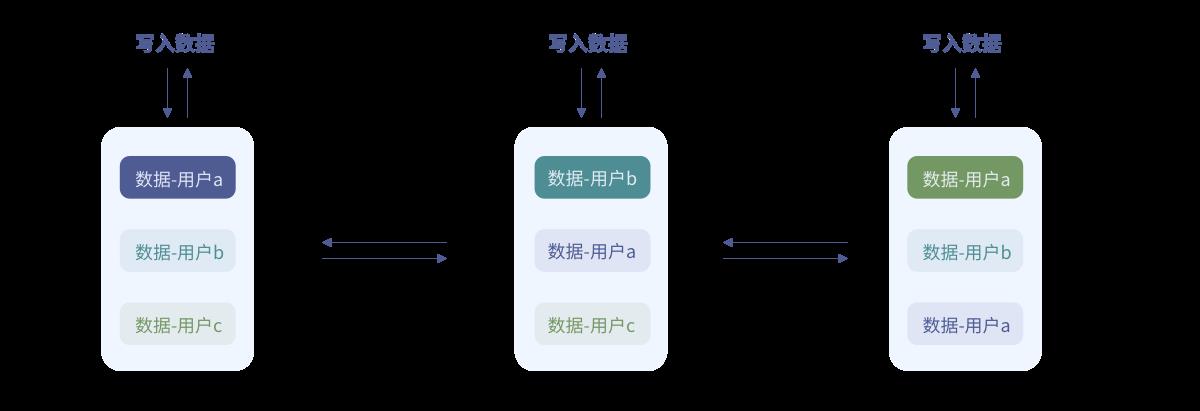
由于不需要存储帐户、联系人等业务数据,因此协议的设计可以大幅简化。但是在设计的一开始,我们也走了弯路。方案初期参考传统的即时通讯的设计,客户端记录一个本地数据的备份,需要同步数据时,将备份的数据传到服务端,服务端通过计算服务器数据与传上来的备份数据的差异,将差异数据发给客户端,客户端再保存差异数据完成同步。不过这个方案有两个问题:一是备份的数据量会随着客户端数据的增多变得越来越大,同步时流量开销大;二是客户端每次同步都要计算差异数据,会带来额外的性能开销和实现复杂度,同时影响了数据到达的实时性。后来我们设计了新的协议,我们称之为RSync(路由同步)协议。
RSync协议的原理为发出的信令消息有三个状态,0:未送达,1:已发出,2:已收到;消息的这三个状态只有状态2需要接收端Ack,既保证了不会丢失数据,又兼顾了信令消息送达的速度;而服务与服务之间只负责消息的分发路由。
3,双活+多数据中心架构
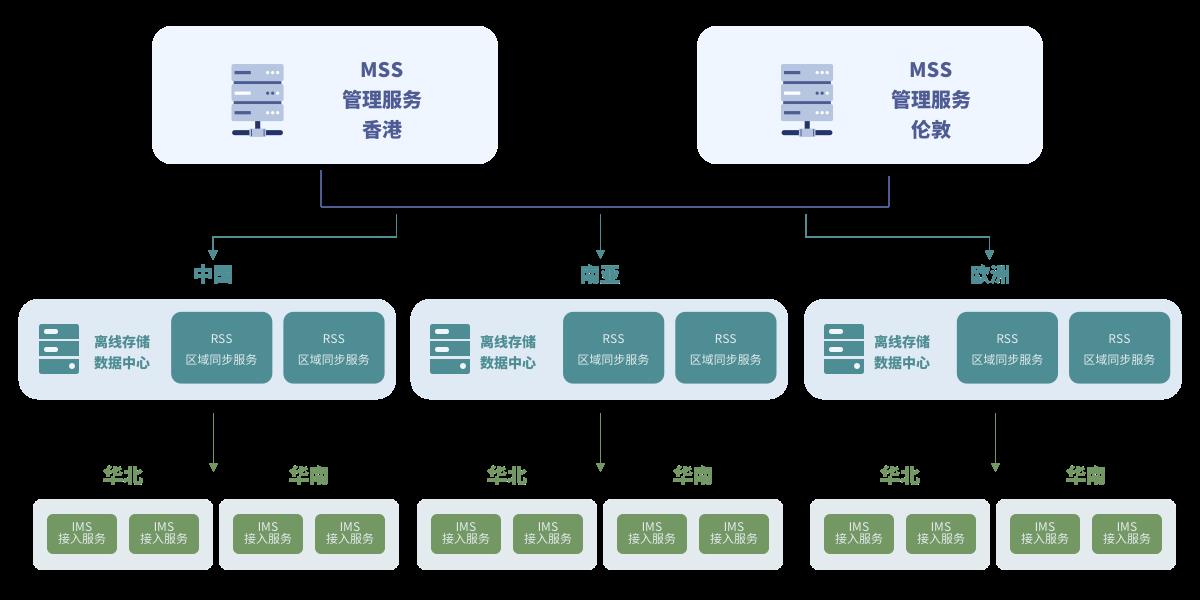
双活:
我们的双活是Master-Master架构,没有主从的区分,双活能够同时提供业务服务能力;既实现了容灾的功能,又增加了系统的整体吞吐量。比如MSS管理服务,我们分别在香港和伦敦两地分别部署了一套,负责全球各地数据中心之间的数据分发。同时每个数据中心都会部署两套RSS服务;而IMS接入服务则是一地多套部署。
多数据中心:
在中国、日本、新加坡、孟买、法兰克福、洛杉矶等地均部署了数据中心,这样能更好的为本地化的APP提供服务。随着中国的业务和出海业务的发展,未来还会在更多的地域进行数据中心部署。
4,RPC - TXP组件
anyRTC基于微服务设计理念,每个服务都是相对独立的业务模块。服务与服务之间的数据交互使用RPC组件来进行,一开始我们使用了开源的ZMQ组件,看中的是ZMQ精简的设计以及优良的性能表现;但在实际业务上线后,经过后台监控发现,在全球部署的业务场景下,跨国通信这块的性能往往达不到我们的要求。因此我们开发了一套TXP协议组件,使用UDP实现的一个快速可靠协议,相比于TCP的传输速率提高了40%左右,特别是在跨国垮运营商等一些高延时高丢包的场景下,性能优势更为显著。
二、解决核心问题
1,C10K
任何一个高并发的服务都会面临C10K问题。C10K的核心问题就是面临大规模的Tcp连接时如何保证每一个用户与服务之间的数据交互实时性,和经济的系统资源开销。
当然现在很多开源的项目都有C10K问题的解决方案。anyRTC的后台服务结合自身的业务特征,定制了适合自己的业务模型的方案;anyRTC都是基于Linux的C++服务,同时我们还支持UDP的连接,UDP的连接本身就没有C10K问题;而TCP连接使用epoll来适用于大规模的应用场景。
2,数据一致性
用户位置不确定性:
一个APP的应用的用户遍布全球,同时一个用户也可以全世界到处跑,那是否允许用户就近接入服务就对业务处理流程有很大影响。我们的设计是必须就近接入,信令服务和即时消息服务不同,信令服务更追求消息到达的速度,同时系统不记录用户的业务数据,因为我们不限定用户使用的区域,所以就近接入是最优的方案。但是允许就近接入,就必须保证数据一致性不影响业务,也就意味着用户数据需要全局同步。
数据中心如何同步:
用户数据全局同步是一个很大的系统开销,所以必须对所有的业务模块进行细分再细分,找到必须要全局同步的业务模块,比如说群消息;一个人在群里发了一条消息,必须保证全球任一数据中心的群内用户都要收到此消息。
anyRTC设计了一个数据管理服务,对全球用户进行区域划分,每个区域的数据中心可以把数据分发到管理服务,管理服务对数据进行全局分发,避免每个数据中心进行数据直接交互。同时配合离线存储服务,就可以既保证区域数据中心的业务精简化,又保证了系统的数据完整性。
三、快速迭代
随着业务的增长,需求也在增多;如何避免做出华而不实的过度设计,往往需要经过几轮思考、讨论、推翻的迭代过程。
1,简化需求:
聚焦核心功能点,剥离实际业务的干扰。由于很多用户还不是非常理解我们的信令服务和即时通讯服务到底有什么不同;所以在面临需求时,我们要做到需求与功能点相匹配,避免过度设计,将真实业务还给用户。
2,微服务:
我们将系统分拆为接入服务,区域路由服务,管理服务,日志服务,数据服务,统计服务,运维服务、上报服务等各种微服务,这样可以保证功能迭代的速度。
3,兼容老版本:
这是大多数业务系统升级都会面临到的问题;与APP不同,我们是提供服务能力,不能够随时要求每个客户去升级SDK模块,我们在设计初期就采用了重服务端、轻客户端的方案,这样在系统升级后,不会要求每个客户端去升级SDK,对老版本用户更加友好。
四、多区容灾
传统的数据中心级灾备方案是“两地三中心”,即同城有两个互备的数据中心,异地再建设一个灾备中心,这三个数据中心平时很可能只有一个在提供在线服务,故障时再将业务流量切换到其他数据中心。这里的主要问题是灾备数据中心无实际业务流量,在主数据中心故障时未必能正常切换到灾备中心,并且在平时大量的备份资源不提供服务,也会造成大量的资源浪费。
多区容灾的核心是多个数据园区同时提供服务,因此即便某园区整体故障,那另外几个园区的业务流量也只会各增加一定比例。反过来说,只需让每个园区的服务器资源跑在容量上限的(N-1)/N,保留1/N的容量即可提供无损的容灾能力,而传统“两地三中心”则有多得多的服务器资源被闲置。此外,在平时多个园区同时对外服务,因此我们在故障时,可以随时将流量切换到其他园区。
一个系统不能只有容灾,必须有业务监控才能更好的避免故障。
产品刚上那段时间后台故障很多。比故障更麻烦的是,因为监控的缺失,经常有些故障我们没法第一时间发现,造成故障影响面被放大。
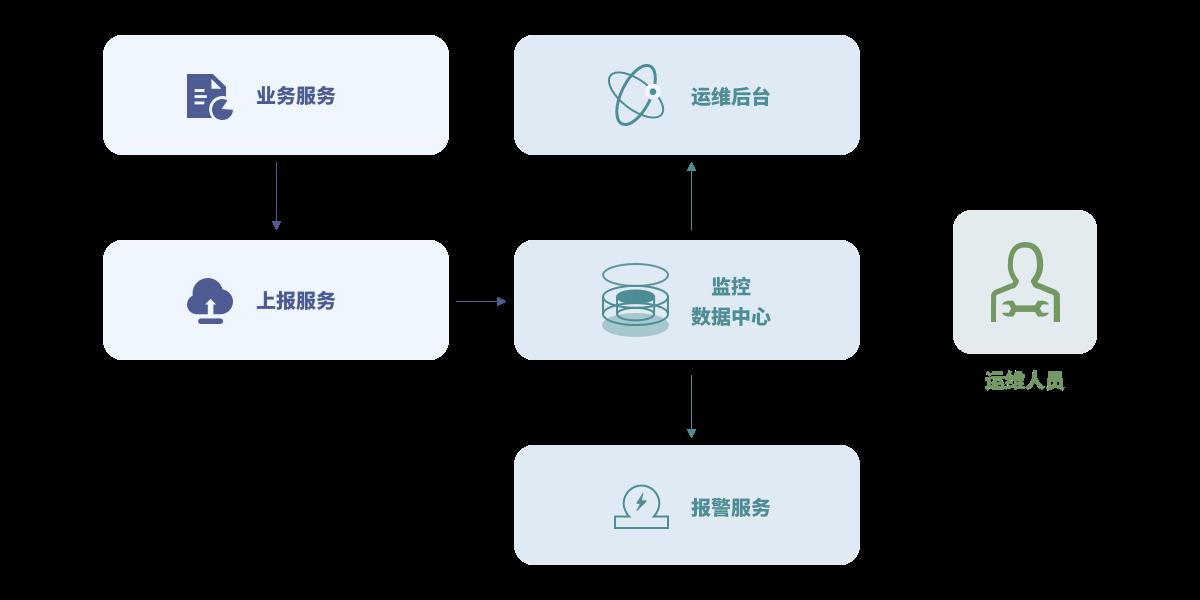
1,故障分析
每个故障不分大小,开发人员需要彻底复盘故障过程,然后商定解决方案,补充出一份详细的技术报告。这份报告侧重于:如何避免同类型故障再次发生、提高故障主动发现能力、缩短故障响应和处理过程。
2,监控告警体系
监控体系实现思路非常简单,允许业务代码在共享内存中对某个监控ID进行设置或累加报警阈值的功能。每台机器上的上报服务会定时将所有ID-阈值上报到监控中心,监控中心对数据汇总入库后就可以通过统一的监控页面输出监控曲线,并通过预先配置的监控规则产生报警。
五、项目依赖:
由于我们需要对信令服务做非常多的特殊处理,比如数据同步协议,数据一致性,异常恢复等等。所以anyRTC的信令服务并未直接使用任何第三方的服务。但是我们很多的设计理念都是参考了许多的成熟案例,比如redis中的集群数据一致性设计;ZooKeeper的一些分布式服务调度理念等。
减少第三方服务的依赖的好处就是对系统环境的要求很低,可以快速上线服务,降低系统部署的复杂度,也会减小运维和升级成本。
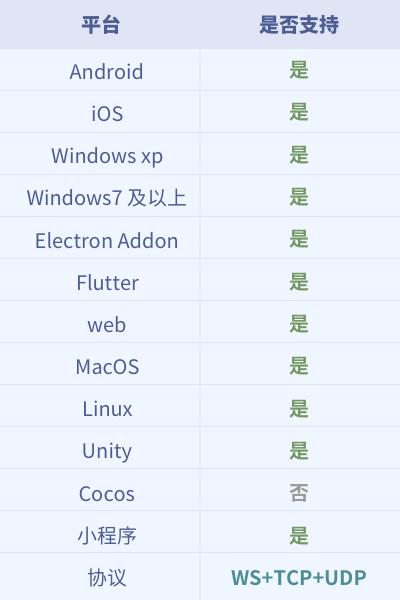
六、客户端能力
七、适用的场景
1,语音聊天室
麦位控制:麦位控制、排麦
房间管理:房间人数、房间名单、房间进出通知
2,视频聊天
呼叫邀请:发送和接收呼叫邀请
用户管理:用户在线状态、用户信息
3,直播聊天室
房间管理:房间人数、房间名单、房间进出通知
互动控制:收发题目、连麦申请
4,在线教育
白板:画笔轨迹
课堂管理:学生名单、课堂公告、举手发言
信令控制:课件控制、举手发言、麦克风禁言
课堂录制:提供历史消息随时回放课堂聊天内容与白板内容
5,物联网
智能家居控制信令
智能车载远程控制
智能手表收发消息
虚拟现实(Virtual Reality,VR)/增强现实(Augmented Reality, AR) 实时标注
6,IM信令通道
消息发送
消息同步
在线状态维护
音视频呼叫
以上是关于亿万级信令服务演化的主要内容,如果未能解决你的问题,请参考以下文章