Windows 10 下 Pytorch 的安装与环境配置
Posted 荣仔!最靓的仔!
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Windows 10 下 Pytorch 的安装与环境配置相关的知识,希望对你有一定的参考价值。
目 录
2.5.2 方法二:下载 pytorch 的 whl 文件到本地安装(速度较快)
1 前期准备工作
前期应该了解电脑的系统类型、python 版本信息以及拥有一款好用的 IDE(如:Pycharm 等)
下面展示的我电脑上的相关信息:
- 系统类型:64位操作系统(×64)
- (Anaconda)python版本:3.7
- Pycharm 版本:PyCharm Community Edition 2020.2.3 x64
Anaconda 下载地址:https://www.anaconda.com/download/
Pycharm 下载地址:https://www.jetbrains.com/pycharm/
2 Pytorch 的安装与环境配置
2.1 查看并创建新的 conda 环境
第一步:打开 Anaconda Prompt(Anaconda)
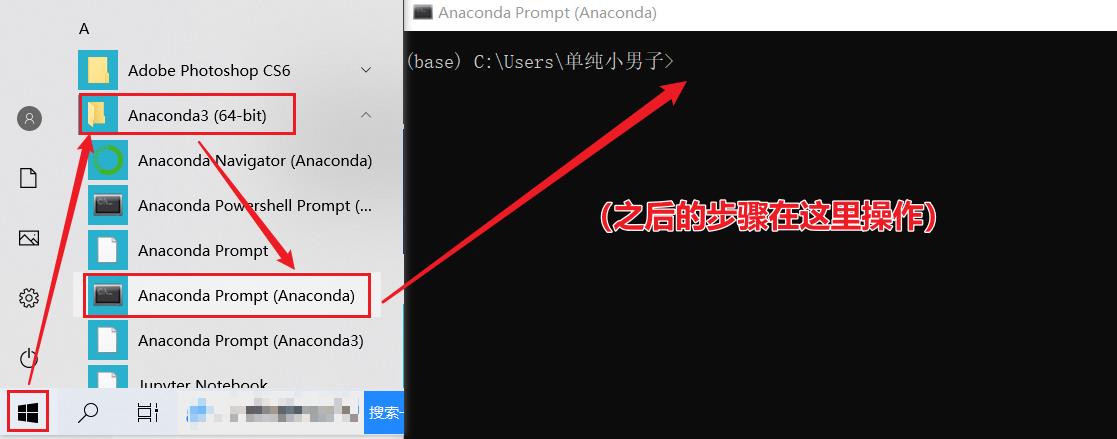
第二步:查看已有的 conda 环境

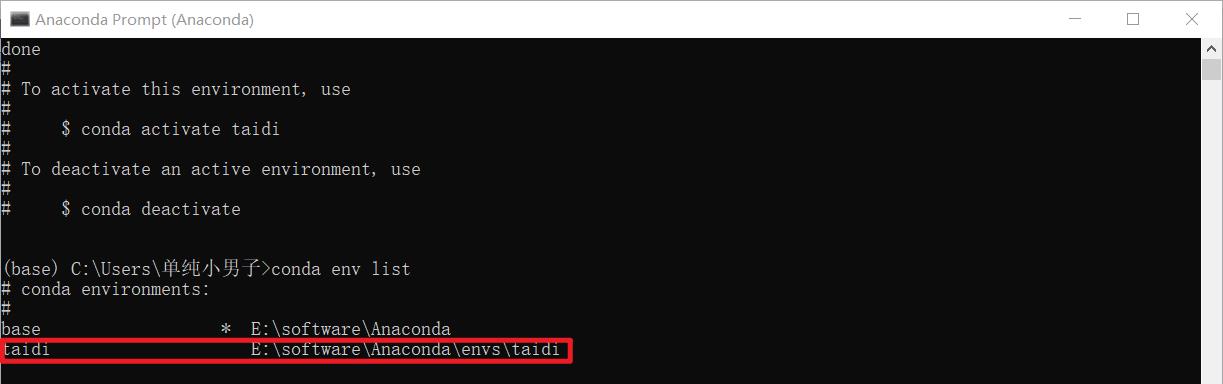
第三步:创建新的 conda 环境 taidi

回车运行,创建好新的 conda 环境后的示例图如下
2.2 部署新的 conda 环境到 Pycharm
在 Pycharm 的Settings 中添加新的 Conda 环境
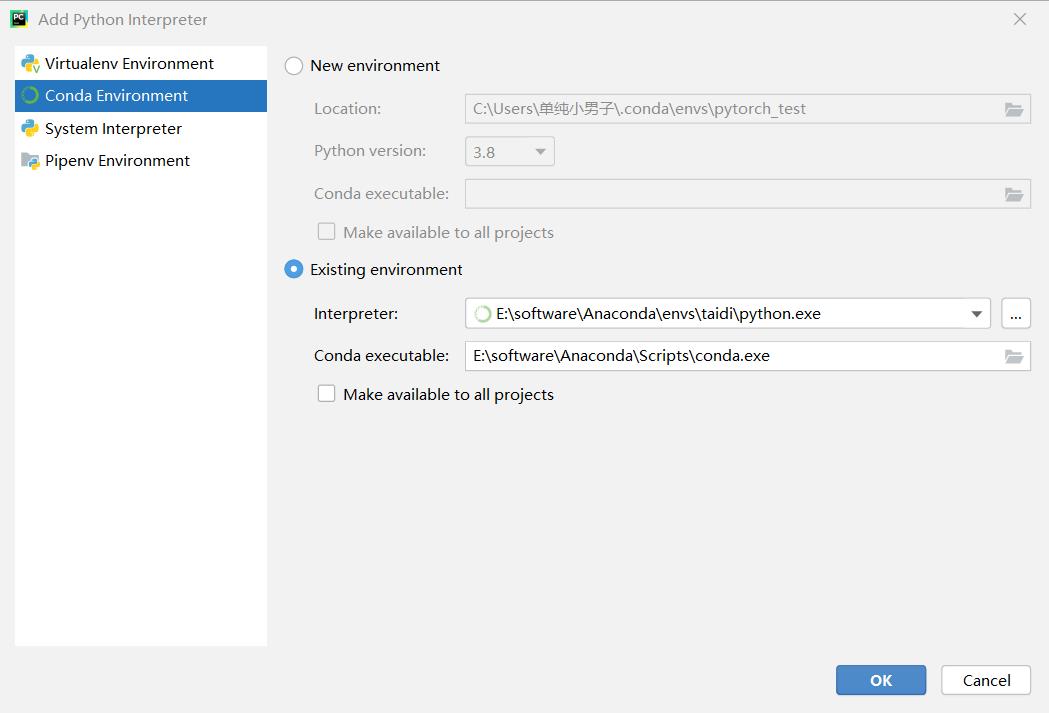

这时我们发现在测试代码中一些包库下面有红色波浪线,说明这些库还没有导入,那么下一步就导入这些库。

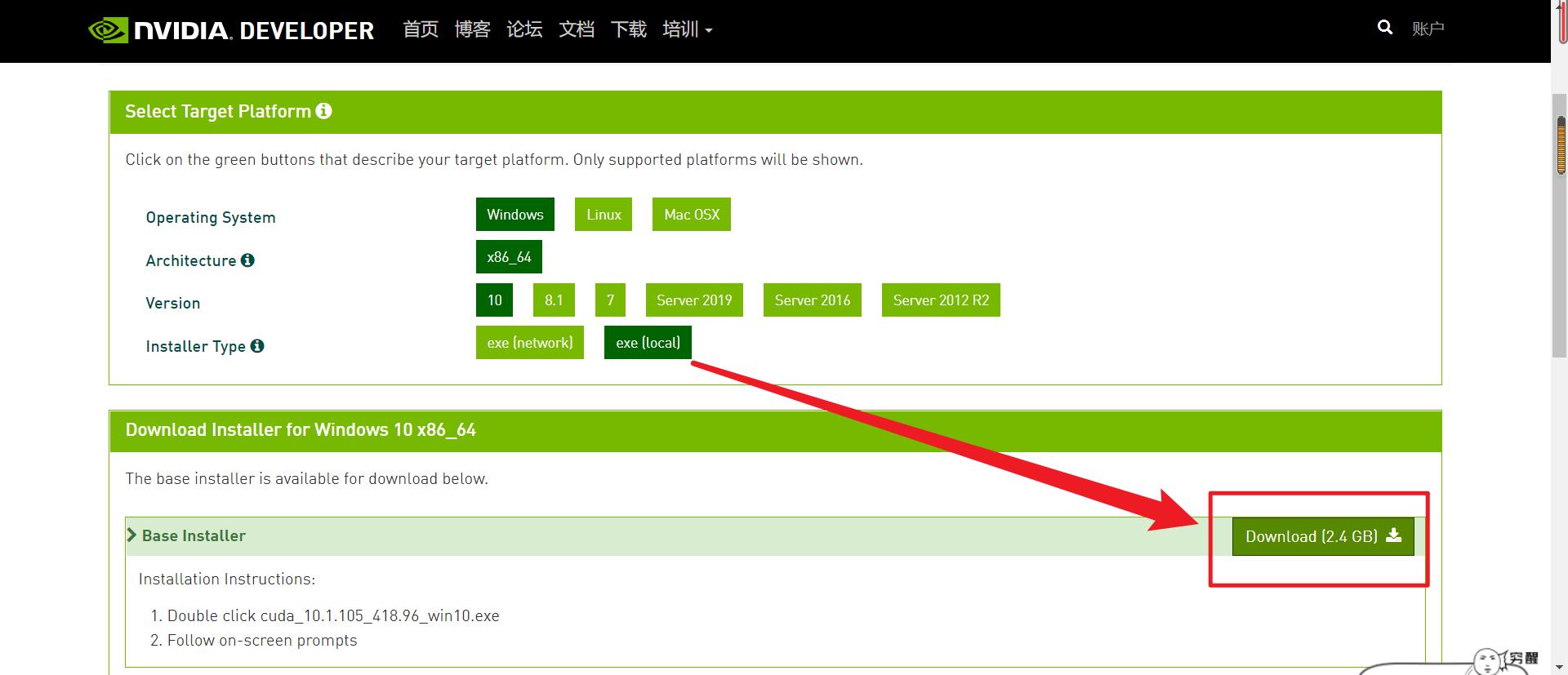
2.3 安装 cuda
对应我电脑的 python 环境,我选择安装 cuda 10.1 版本,当然读者可根据自己需要对应安装不同版本的 cuda。
cuda下载路径:https://developer.nvidia.com/cuda-10.1-download-archive-base
解压
![]()

2.4 下载安装 cuDNN
在官网选择与 cuda 版本对应的 cuDNN。
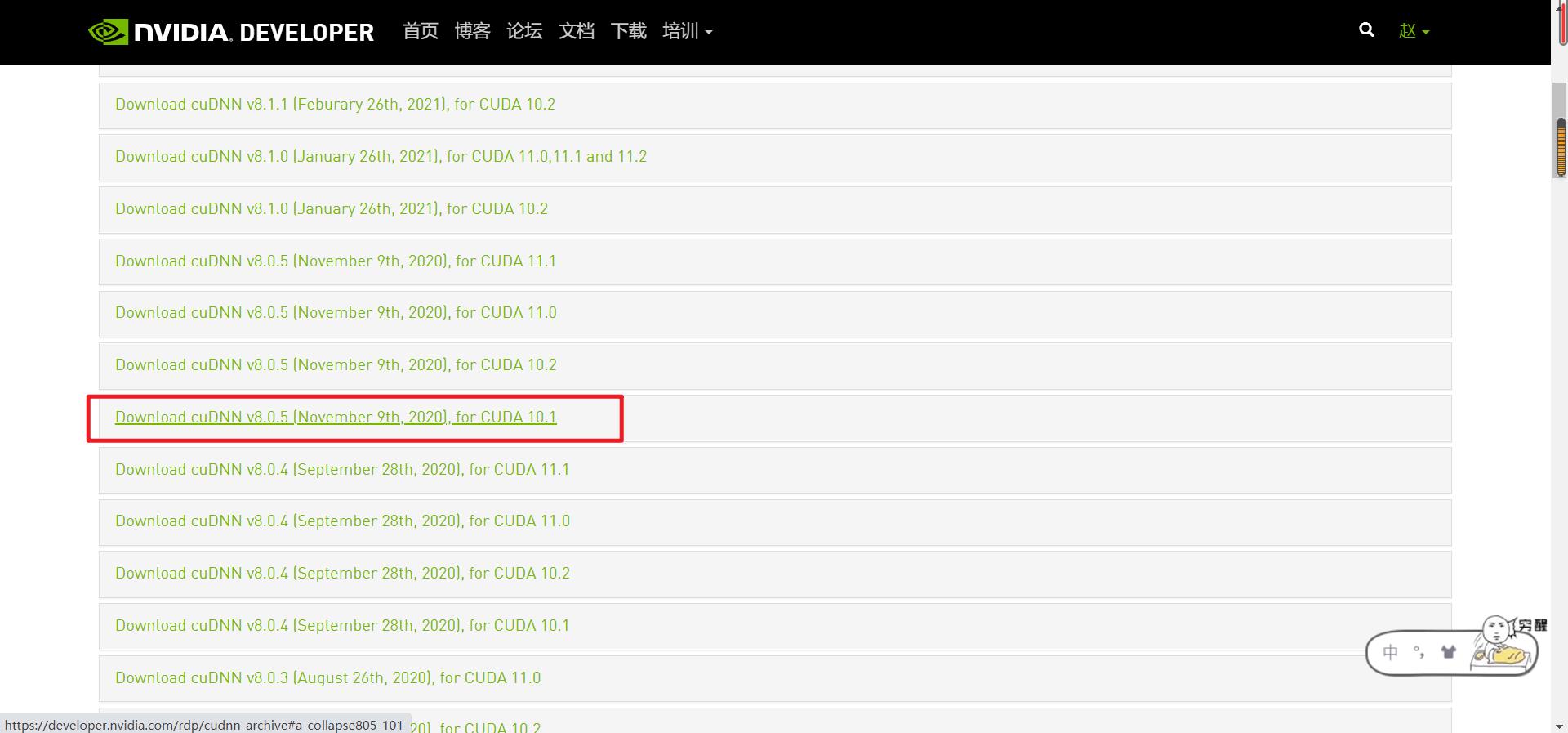
将下载好的 cuDNN 应用程序放到桌面,双击图标运行

等待初始化安装完成
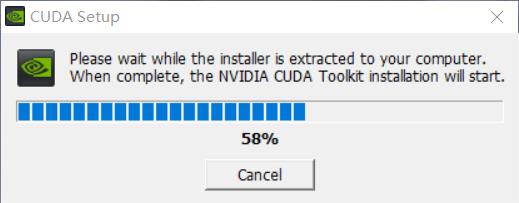
接下来的操作就依次按照下图所示进行就好:

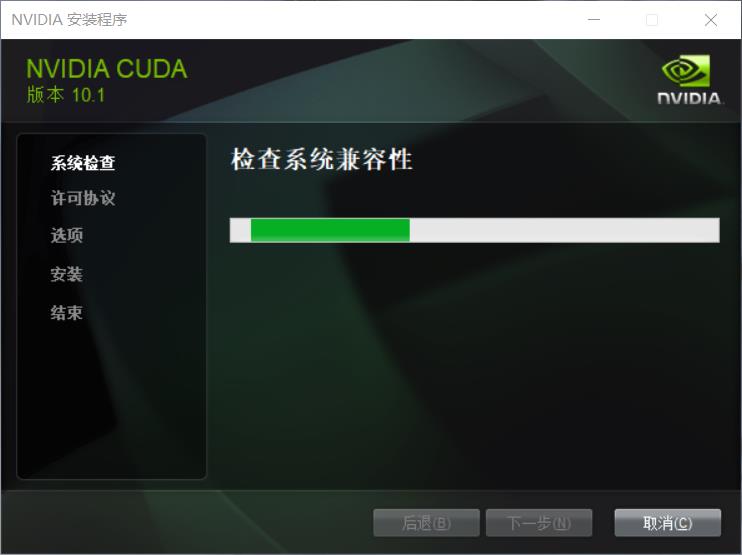
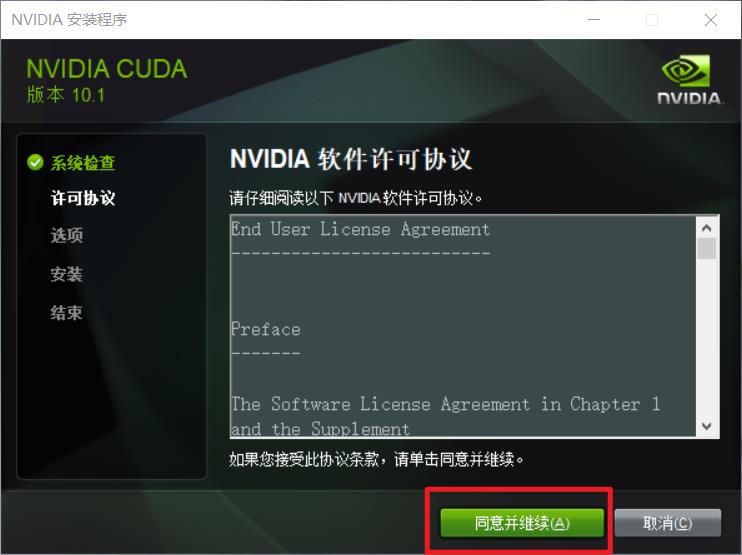

安装好后进入本地路径 C:\\Program Files\\NVIDIA GPU Computing Toolkit\\CUDA\\v10.1 即可看到 CUDA 文件信息
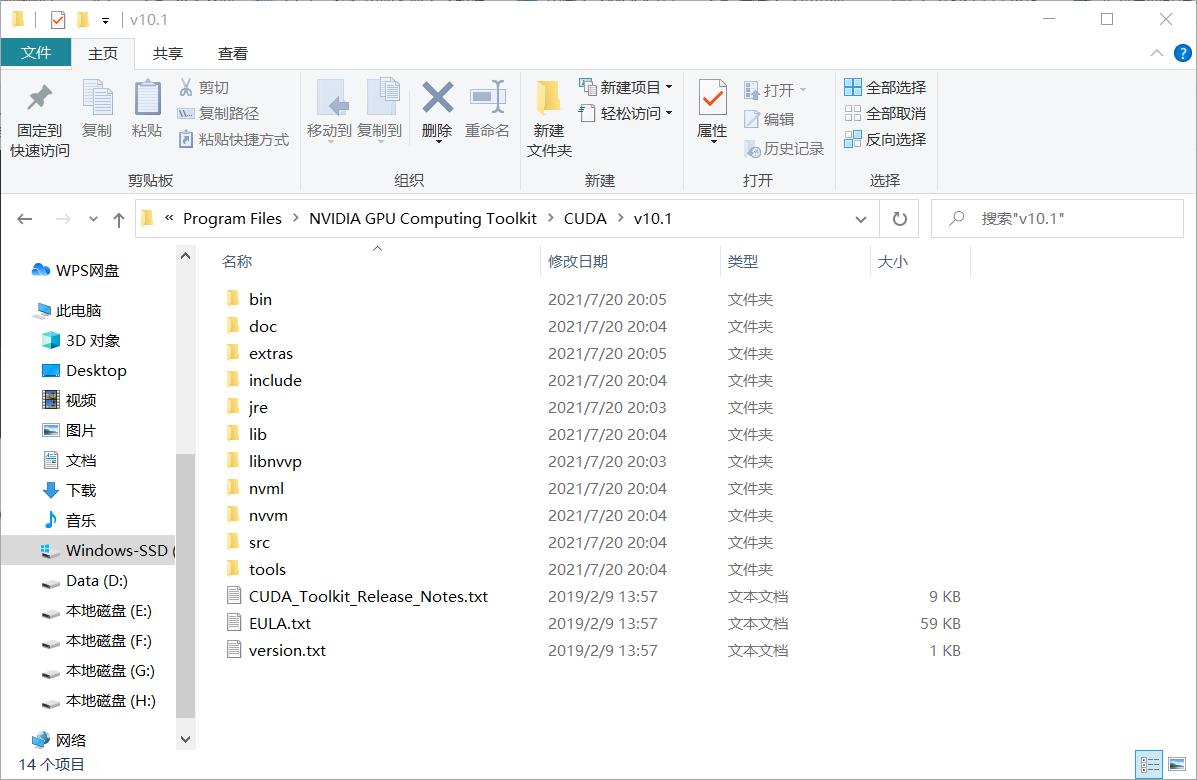
接下来将前面解压出的文件全部复制粘贴到 C 盘目录下的 CUDA 文件夹中
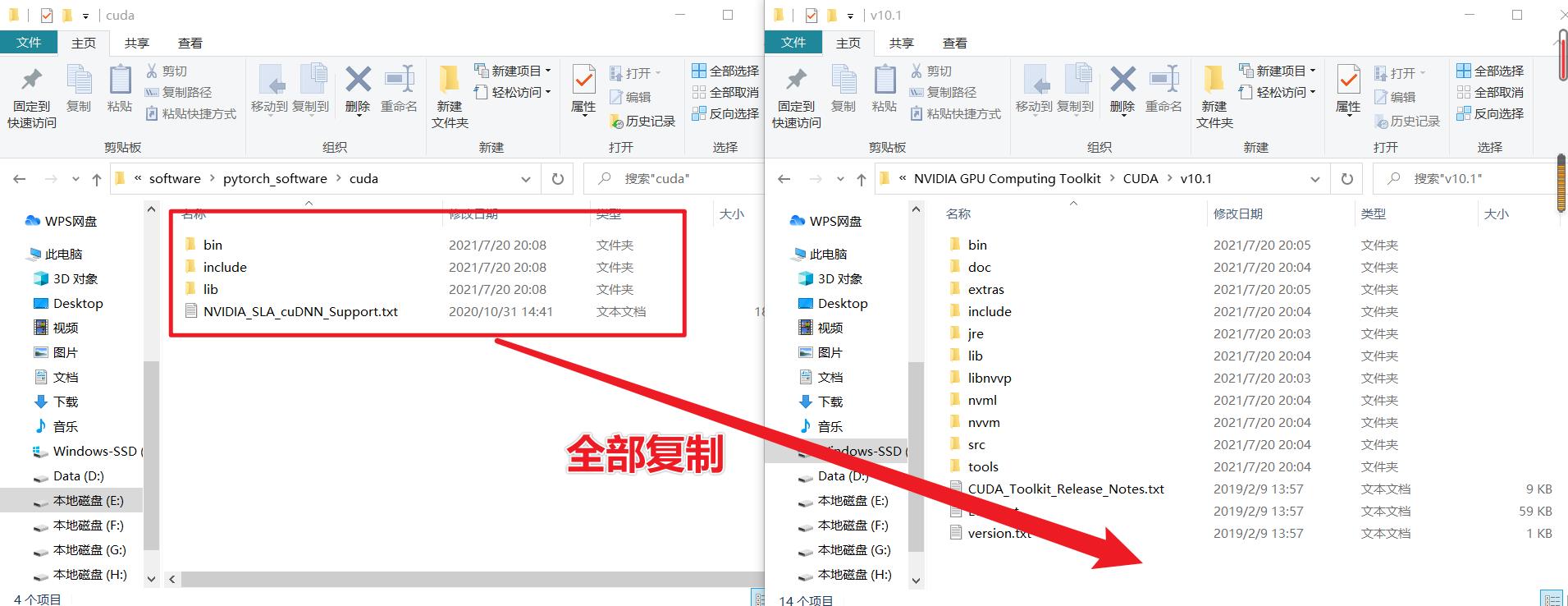
2.5 下载安装 pytorch
进入pytorch官网:https://pytorch.org/get-started/previous-versions/
2.5.1 方法一:利用官网找到的命令行语句 (速度较慢)
可以选用 conda 安装也可以选用 pip 安装(注意 CUDA 版本要对应)

接下来要将上图所示对应代码复制粘贴到 pycharm Terminal 中
值得注意的是,若命令行前的小括号内不是 taidi,需要首先执行下面语句切换到 taidi 环境中
conda activate taidi正确的情况如下图所示
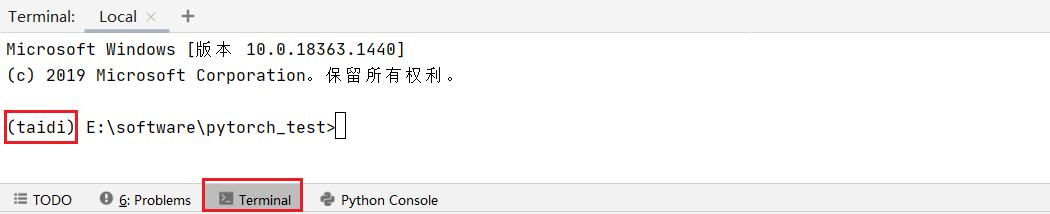
将命令行语句粘贴过来回车运行,等待安装完成即可。
2.5.2 方法二:下载 pytorch 的 whl 文件到本地安装(速度较快)
![]()
注:① 文件路径尽量选用绝对路径,可有效避免报错
② 为加快安装速度,避免报“超时”错误,亦可输入下面命令语句(原理:换源)
python -m pip install -i http://pypi.tuna.tsinghua.edu.cn/simple --trusted-host pypi.tuna.tsinghua.edu.cn 空格后紧跟下载本地路径若出现如下图所示的内容,pytorch 大概率是安装成功啦
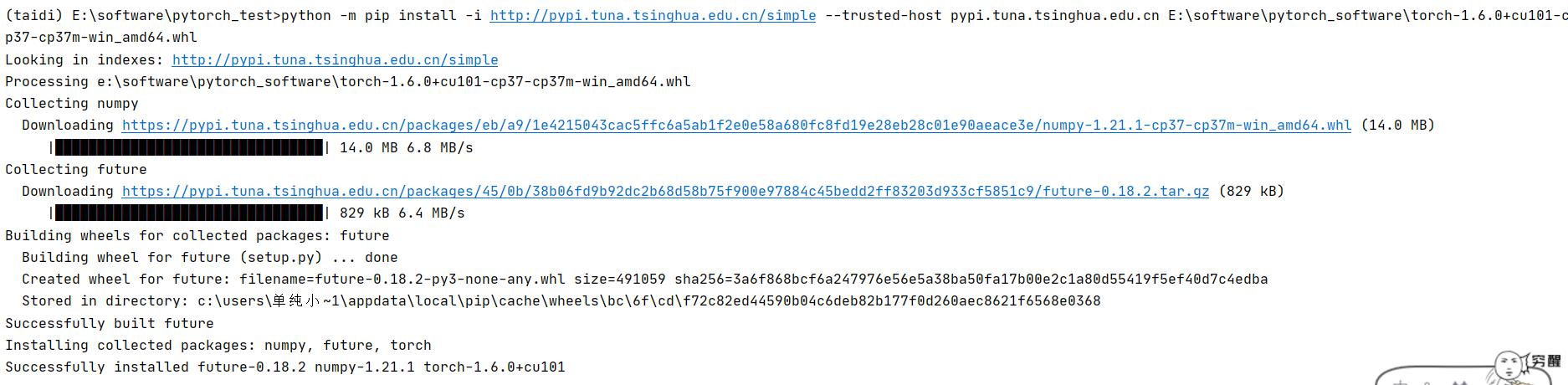
2.6 安装 torchvision
直接执行下面语句到 pycharm taidi 环境下的命令行即可
python -m pip install -i http://pypi.tuna.tsinghua.edu.cn/simple --trusted-host pypi.tuna.tsinghua.edu.cn torchvision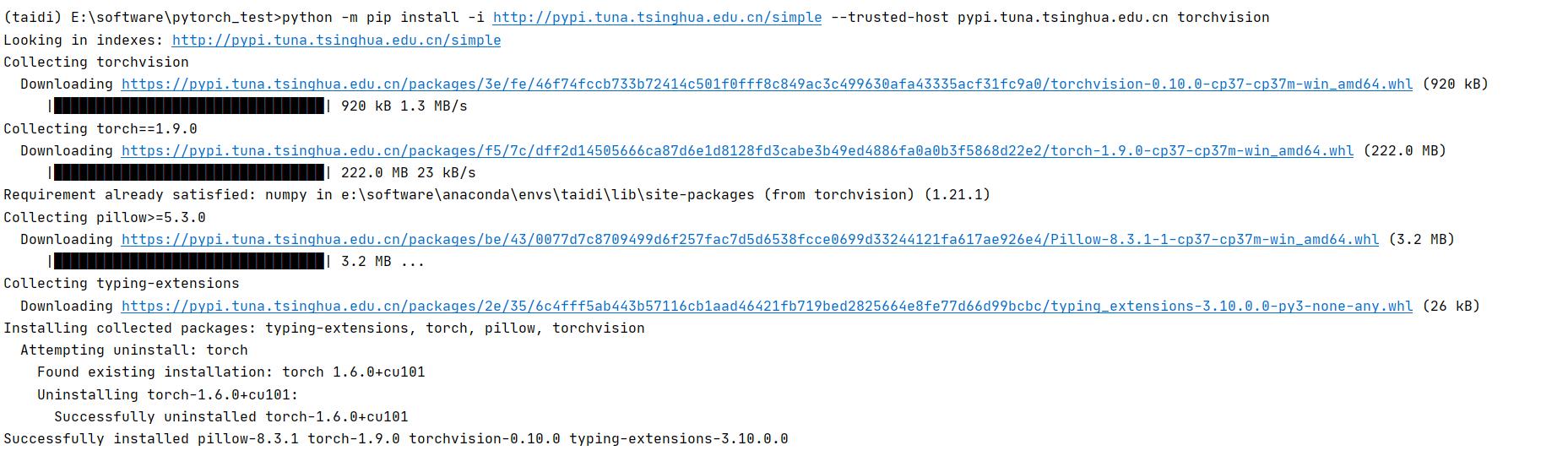
3 测试
3.1 测试示例代码
from __future__ import print_function
import argparse
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.autograd import Variable
# Training settings
parser = argparse.ArgumentParser(description='PyTorch MNIST Example')
parser.add_argument('--batch-size', type=int, default=64, metavar='N',
help='input batch size for training (default: 64)')
parser.add_argument('--test-batch-size', type=int, default=1000, metavar='N',
help='input batch size for testing (default: 1000)')
parser.add_argument('--epochs', type=int, default=10, metavar='N',
help='number of epochs to train (default: 10)')
parser.add_argument('--lr', type=float, default=0.01, metavar='LR',
help='learning rate (default: 0.01)')
parser.add_argument('--momentum', type=float, default=0.5, metavar='M',
help='SGD momentum (default: 0.5)')
parser.add_argument('--no-cuda', action='store_true', default=False,
help='disables CUDA training')
parser.add_argument('--seed', type=int, default=1, metavar='S',
help='random seed (default: 1)')
parser.add_argument('--log-interval', type=int, default=10, metavar='N',
help='how many batches to wait before logging training status')
args = parser.parse_args()
args.cuda = not args.no_cuda and torch.cuda.is_available()
torch.manual_seed(args.seed) # 为CPU设置种子用于生成随机数,以使得结果是确定的
if args.cuda:
torch.cuda.manual_seed(args.seed) # 为当前GPU设置随机种子;如果使用多个GPU,应该使用torch.cuda.manual_seed_all()为所有的GPU设置种子。
kwargs = {'num_workers': 1, 'pin_memory': True} if args.cuda else {}
"""加载数据。组合数据集和采样器,提供数据上的单或多进程迭代器
参数:
dataset:Dataset类型,从其中加载数据
batch_size:int,可选。每个batch加载多少样本
shuffle:bool,可选。为True时表示每个epoch都对数据进行洗牌
sampler:Sampler,可选。从数据集中采样样本的方法。
num_workers:int,可选。加载数据时使用多少子进程。默认值为0,表示在主进程中加载数据。
collate_fn:callable,可选。
pin_memory:bool,可选
drop_last:bool,可选。True表示如果最后剩下不完全的batch,丢弃。False表示不丢弃。
"""
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=args.batch_size, shuffle=True, **kwargs)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=args.batch_size, shuffle=True, **kwargs)
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5) # 输入和输出通道数分别为1和10
self.conv2 = nn.Conv2d(10, 20, kernel_size=5) # 输入和输出通道数分别为10和20
self.conv2_drop = nn.Dropout2d() # 随机选择输入的信道,将其设为0
self.fc1 = nn.Linear(320, 50) # 输入的向量大小和输出的大小分别为320和50
self.fc2 = nn.Linear(50, 10)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 2)) # conv->max_pool->relu
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2)) # conv->dropout->max_pool->relu
x = x.view(-1, 320)
x = F.relu(self.fc1(x)) # fc->relu
x = F.dropout(x, training=self.training) # dropout
x = self.fc2(x)
return F.log_softmax(x)
model = Net()
if args.cuda:
model.cuda() # 将所有的模型参数移动到GPU上
optimizer = optim.SGD(model.parameters(), lr=args.lr, momentum=args.momentum)
def train(epoch):
model.train() # 把module设成training模式,对Dropout和BatchNorm有影响
for batch_idx, (data, target) in enumerate(train_loader):
if args.cuda:
data, target = data.cuda(), target.cuda()
data, target = Variable(data), Variable(
target) # Variable类对Tensor对象进行封装,会保存该张量对应的梯度,以及对生成该张量的函数grad_fn的一个引用。如果该张量是用户创建的,grad_fn是None,称这样的Variable为叶子Variable。
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target) # 负log似然损失
loss.backward()
optimizer.step()
if batch_idx % args.log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
def test(epoch):
model.eval() # 把module设置为评估模式,只对Dropout和BatchNorm模块有影响
test_loss = 0
correct = 0
for data, target in test_loader:
if args.cuda:
data, target = data.cuda(), target.cuda()
data, target = Variable(data, volatile=True), Variable(target)
output = model(data)
test_loss += F.nll_loss(output, target).item() # Variable.data
pred = output.data.max(1)[1] # get the index of the max log-probability
correct += pred.eq(target.data).cpu().sum()
test_loss = test_loss
test_loss /= len(test_loader) # loss function already averages over batch size
print('\\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
if __name__ == '__main__':
for epoch in range(1, args.epochs + 1):
train(epoch)
test(epoch)
3.2 测试结果
不报错说明安装成功。如下图所示,是在训练模型的过程截图。
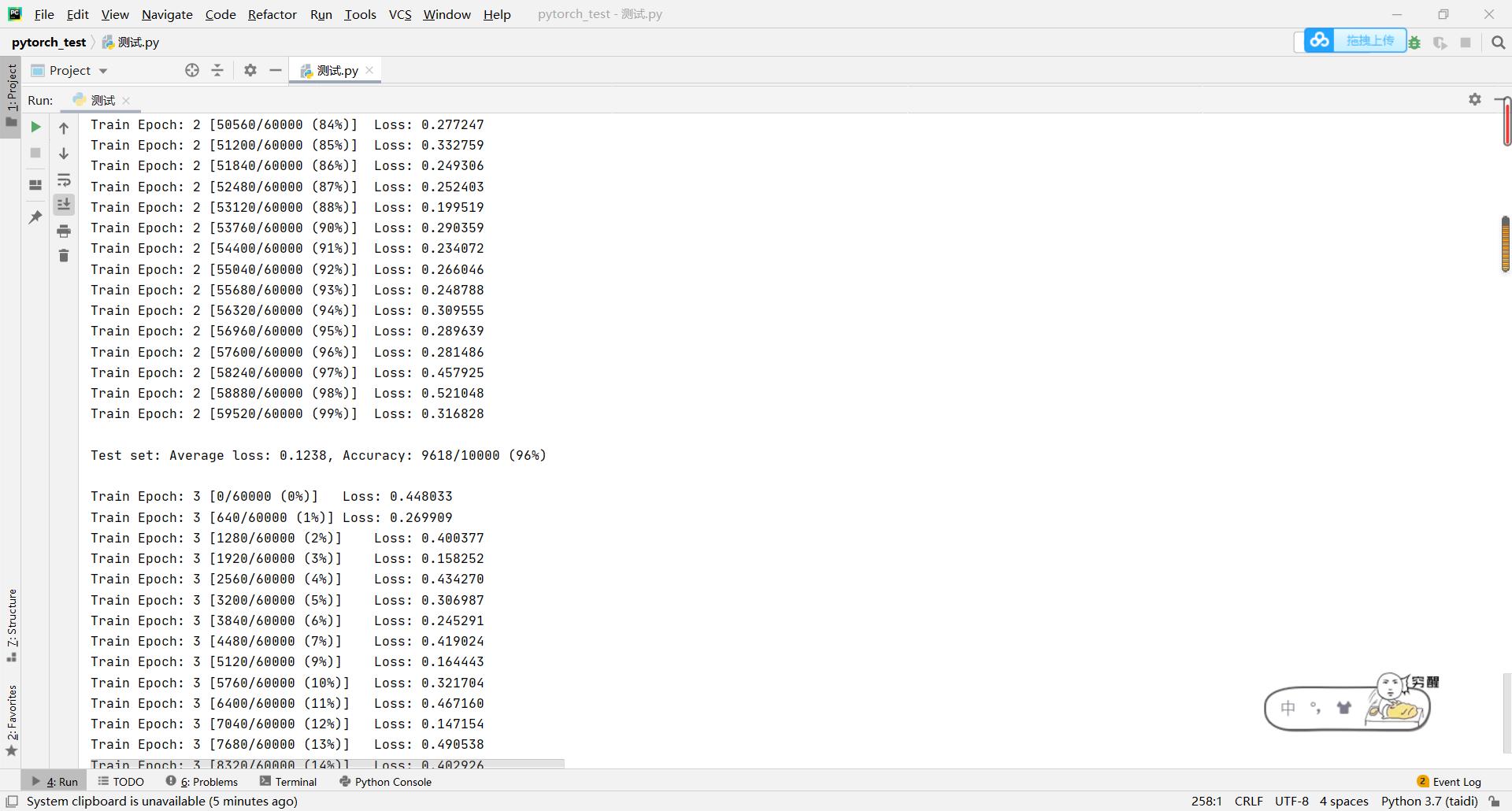
大家在施行过程中若发现什么问题可随时联系,也可在下方评论区留下你的问题
若发现新的更简便方法我也会随时更新的
欢迎大家交流评论,一起学习
希望本文能帮助您解决您在这方面遇到的问题
感谢阅读
END
版权声明:本文为CSDN博主「荣仔!最靓的仔!」的原创文章,遵循 CC 4.0 BY-SA 版权协议。
转载请在醒目位置附上原文出处链接及本声明。以上是关于Windows 10 下 Pytorch 的安装与环境配置的主要内容,如果未能解决你的问题,请参考以下文章
如何在windows10环境下安装Pytorch-0.4.1版本
Windows 10系统在Anaconda下安装GPU版Pytorch
教程:Windows10下如何安装使用多版本Tensorflow2.x/Pytorch/paddlepaddle的GPU版本[和CUDA的安装及问题详解]亲测可行详细和持续更新