Spark 大数据处理最佳实践
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark 大数据处理最佳实践相关的知识,希望对你有一定的参考价值。
开源大数据社区 & 阿里云 EMR 系列直播 第十一期
主题:Spark 大数据处理最佳实践
讲师:简锋,阿里云 EMR 数据开发平台 负责人
内容框架:
- 大数据概览
- 如何摆脱技术小白
- Spark SQL 学习框架
- EMR Studio 上的大数据最佳实践
直播回放:进入链接https://developer.aliyun.com/live/247072
一、大数据概览
- 大数据处理 ETL (Data → Data)
- 大数据分析 BI (Data → Dashboard)
- 机器学习 AI (Data → Model)
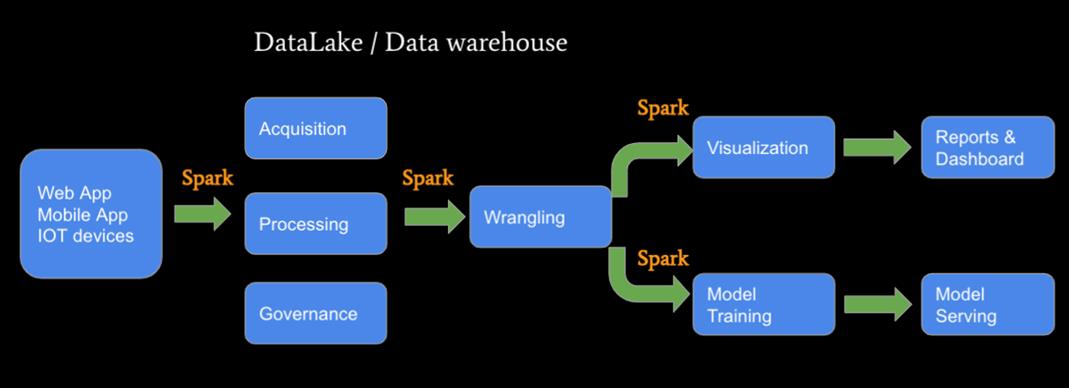
二、如何摆脱技术小白
什么是技术小白?
- 只懂表面,不懂本质
比如:只懂得参考别人的 Spark 代码,不懂得 Spark 的内在机制,不懂得如何调优 Spark Job
摆脱技术小白的药方
- 懂得运行机制
- 学会配置
- 学会看 Log
懂得运行机制:Spark SQL Architecture
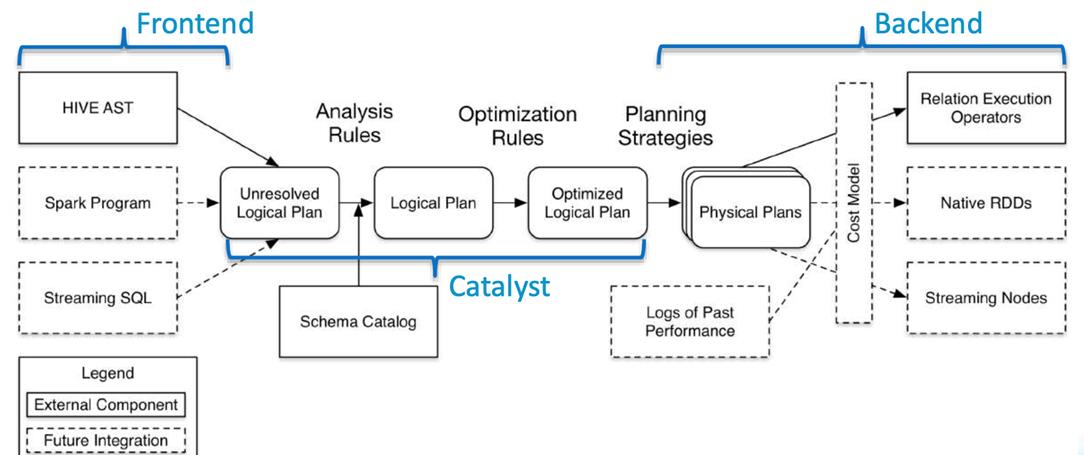
学会配置:如何配置 Spark App
- 配置 Driver
• spark.driver.memory
• spark.driver.cores
- 配置 Executor
• spark.executor.memory
• spark.executor.cores
- 配置 Runtime
• spark.files
• spark.jars
- 配置 DAE
- …..........
参考网址:https://spark.apache.org/docs/latest/configuration.html
学会看 Log:Spark Log
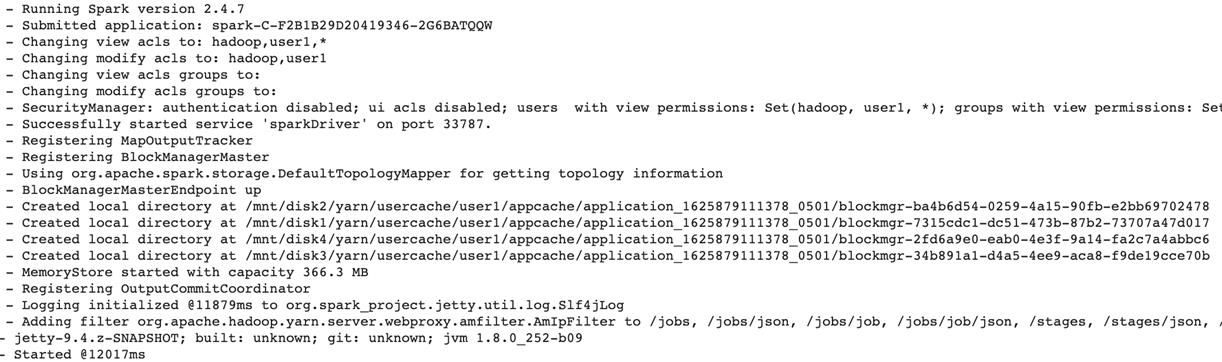
三、Spark SQL 学习框架
Spark SQL 学习框架( 结合图形/几何)
1. Select Rows


2. Select Columns

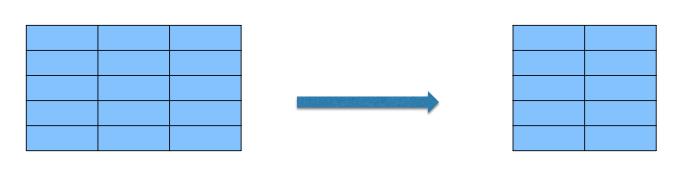
3. Transform Column


4. Group By / Aggregation


5. Join

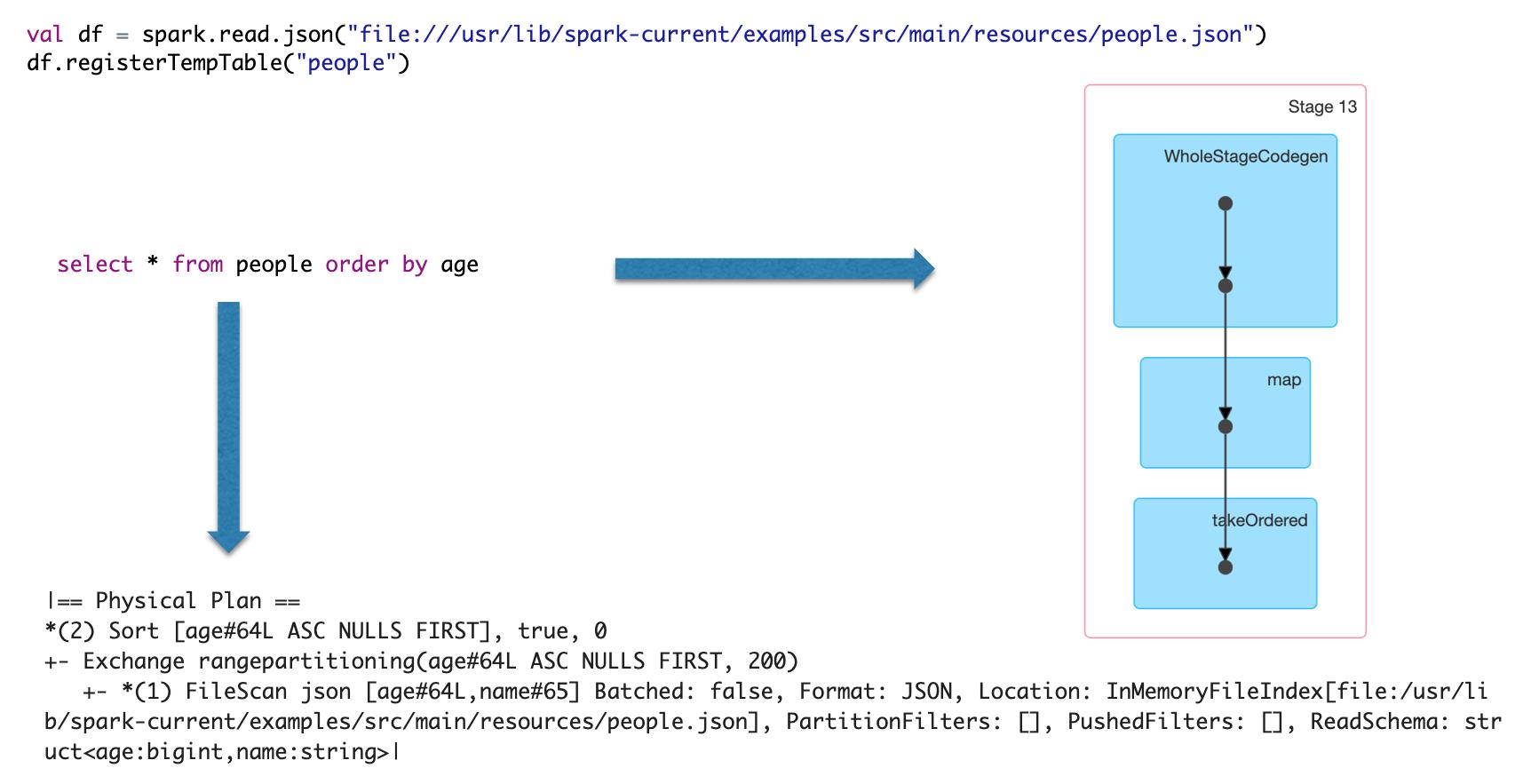
Spark SQL 执行计划
1. Spark SQL - Where

2. Spark SQL - Group By

3. Spark SQL - Order by
四、EMR Studio 实践
EMR Studio 特性:
- 兼容开源组件
- 支持连接多个集群
- 适配多个计算引擎
- 交互式开发 + 作业调度无缝衔接
- 适用多种大数据应用场景
- 计算存储分离
1. 兼容开源组件
- EMR Studio 在开源软件 Apache Zeppelin,Jupyter Notebook, Apache Airflow 的基础上优化了做了优化和增强。

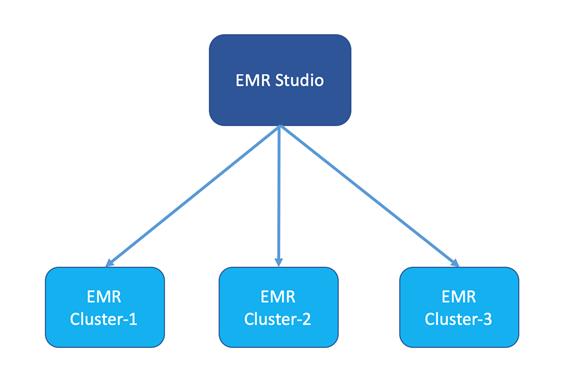
2. 支持连接多个集群
- 一个 EMR Studio 可以连接多个 EMR 计算集群,您可以很方便地切换计算集群,提交作业到不同的计算集群上运行。
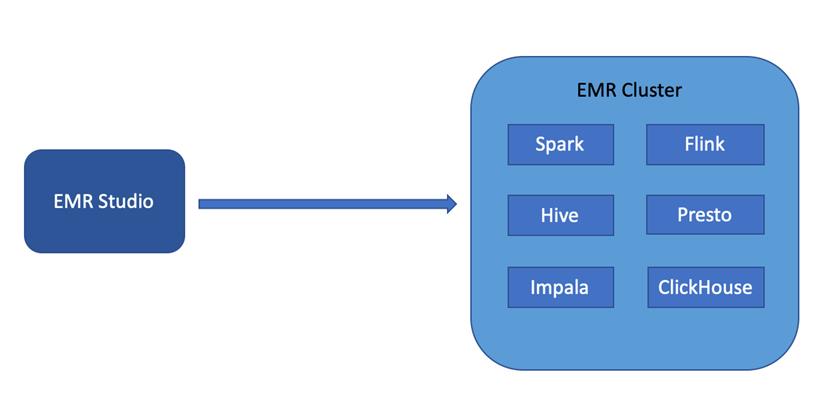
3. 适配多个计算引擎
- 自动适配 Hive、Spark、Flink、Presto、Impala 和 Shell 等多个计算引擎,无需复杂配置,多个计算引擎间协同工作
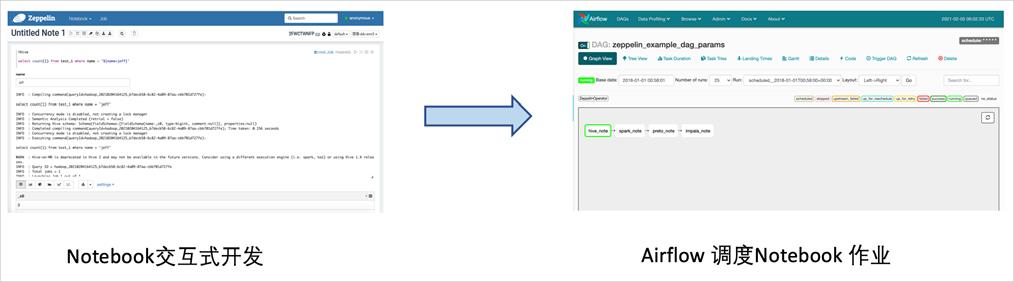
4. 交互式开发 + 作业调度无缝衔接
Notebook + Airflow : 无缝衔接开发环节和生产调度环节
- 利用交互式开发模式可以快速验证作业的正确性.
- 在 Airflow 里调度 Notebook 作业,最大程度得保证开发环境和生产环境的一致性,防止由于开发阶段和生产阶段环境不一致而导致的问题。
5. 适用多种大数据应用场景
- 大数据处理 ETL
- 交互式数据分析
- 机器学习
- 实时计算
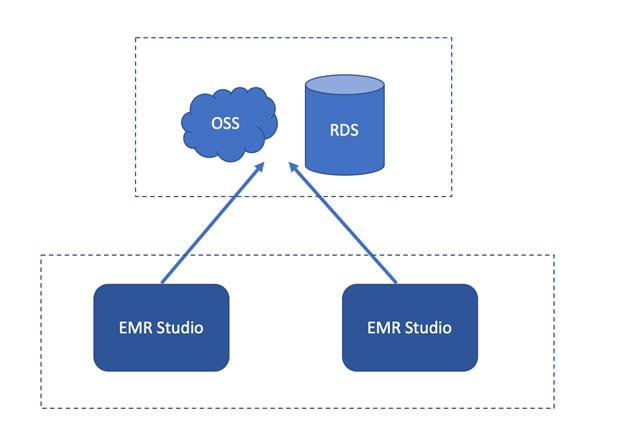
6. 计算存储分离
- 所有数据都保存在 OSS 上,包括:
• 用户 Notebook 代码
• 调度作业 Log
- 即使集群销毁,也可以重建集群轻松恢复数据
EMR Studio Demo 演示:
参考文档:https://help.aliyun.com/document_detail/208107.html?spm=a2c4g.11186623.6.845.6cfc24577t1RbI
本文为阿里云原创内容,未经允许不得转载。
以上是关于Spark 大数据处理最佳实践的主要内容,如果未能解决你的问题,请参考以下文章
阿里大数据云原生化实践,EMR Spark on ACK 产品介绍