TensorFlow实现自注意力机制(Self-attention)
Posted 盼小辉丶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TensorFlow实现自注意力机制(Self-attention)相关的知识,希望对你有一定的参考价值。
TensorFlow实现自注意力机制(Self-attention)
自注意力机制(Self-attention)
自注意力机制 (Self-attention) 随着自然语言处理 (Natural Language Processing, NLP) 模型(称为“Transformer”)的引入而变得流行。在诸如语言翻译之类的NLP应用程序中,模型通常需要逐字阅读句子以理解它们,然后再产生输出。Transformer问世之前使用的神经网络是递归神经网络 (Recurrent Neural Network, RNN) 或者其变体,例如长短期记忆网络 (Long Short-Term Memory, LSTM)。 RNN 具有其内部状态,能够更好的处理序列信息,例如句子中前面的单词输入和后面的单词输入是有关系的。但是 RNN 也具有其缺陷,例如当单词数量增加时,那么第一个单词的梯度就可能消失。也就是说,随着RNN读取更多单词,句子开头的单词逐渐变得不那么重要。
Transformer 的处理方式有所不同。它会一次读取所有单词,并权衡每个单词的重要性。因此,更多的注意力集中在更重要的单词上,因此也称为注意力。
而自注意力机制是注意力机制的变体,其减少了对外部信息的依赖,更擅长捕捉数据或特征的内部相关性。自注意力是最新的NLP模型 (例如BERT和GPT-3) 的基石。
计算机视觉中的自注意力
首先简单回顾下卷积神经网络 (Convolutional Neural Networks, CNN) 的要点:CNN 主要由卷积层组成。对于卷积核大小为 3×3 的卷积层,它仅查看输入激活中的 3×3 = 9 个特征(也可以将此区域称为卷积核的感受野)以计算每个输出特征,它并不会查看超出此范围的像素。为了捕获超出此范围的像素,我们可以将核大小略微增加到 5×5 或 7×7,但与特征图大小相比感受野仍然很小。
我们必须增加网络的深度,以使卷积核的感受野足够大以捕获我们想要的内容。与RNN一样,输入特征的相对重要性随着我们在网络层中的移动而下降。因此,我们可以利用自注意力来观察特征图中的每个像素,并注意力集中在更加重要的像素上。
现在,我们将研究自注意力机制的工作原理。自注意力的第一步是将每个输入特征投影到三个向量中,这些向量称为键 (key),查询 (query) 和值 (value),虽然这些术语在计算机视觉中较少出现,但是首先介绍有关这些术语的知识,以便可以更好地理解自注意力,Transformer或NLP有关的文献:
- 值 (value) 表示输入特征。我们不希望自注意力模块查看每个像素,因为这在计算上过于昂贵且不必要。相反,我们对输入激活的局部区域更感兴趣。因此,值在激活图尺寸(例如,它可以被下采样以具有较小的高度和宽度)和通道的数目方面都减小了来自输入特征的维数。 对于卷积层激活,通过使用1x1卷积来减少通道数,并通过最大池化或平均池化来减小空间大小。
- 键和查询 (Keys and queries) 用于计算自注意图中特征的重要性。为了计算位置
x
x
x 处的输出特征,我们在位置
x
x
x 处进行查询,并将其与所有位置处的键进行比较。
为了进一步说明这一点,假设我们有一个肖像画,当网络处理肖像的一只眼睛时,它将首先进行查询,该查询具有“眼睛”的语义含义,并使用肖像的其他区域的键进行检查。如果其他区域的键之一是眼睛,那么网络知道其找到了另一只眼睛,这就是网络要注意的区域,以便网络可以进一步的处理。
更一般的,使用数学方程表达:对于特征 0 0 0,我们计算向量 q 0 × k 0 , q 0 × k 1 , q 0 × k 2 , q 0 × k N − 1 q_0×k_0, q_0×k_1, q_0×k_2, q_0×k_{N-1} q0×k0,q0×k1,q0×k2,q0×kN−1。然后使用 s o f t m a x softmax softmax 将向量归一化,因此它们的总和为 $1.0,这就是是我们要求的注意力得分。将注意力得分用作权重以执行值的逐元素乘法,以获取注意力输出。
下图说明了如何从查询中生成注意力图:

上图红,最左边一列的图是带有点标记的查询 (queries) 的图像。接下来的五个图像显示了通过查询获得的注意力图。顶部的第一个注意力图查询兔子的一只眼睛;注意图的两只眼睛周围有更多白色区域(指示重要区域),其他区域接近全黑(重要性较低)。
有多种实现自注意力的方法。下图显示了 SAGAN 中的所使用的注意力模块,其中 θ θ θ, φ φ φ 和 g g g 对应于键,查询和值:
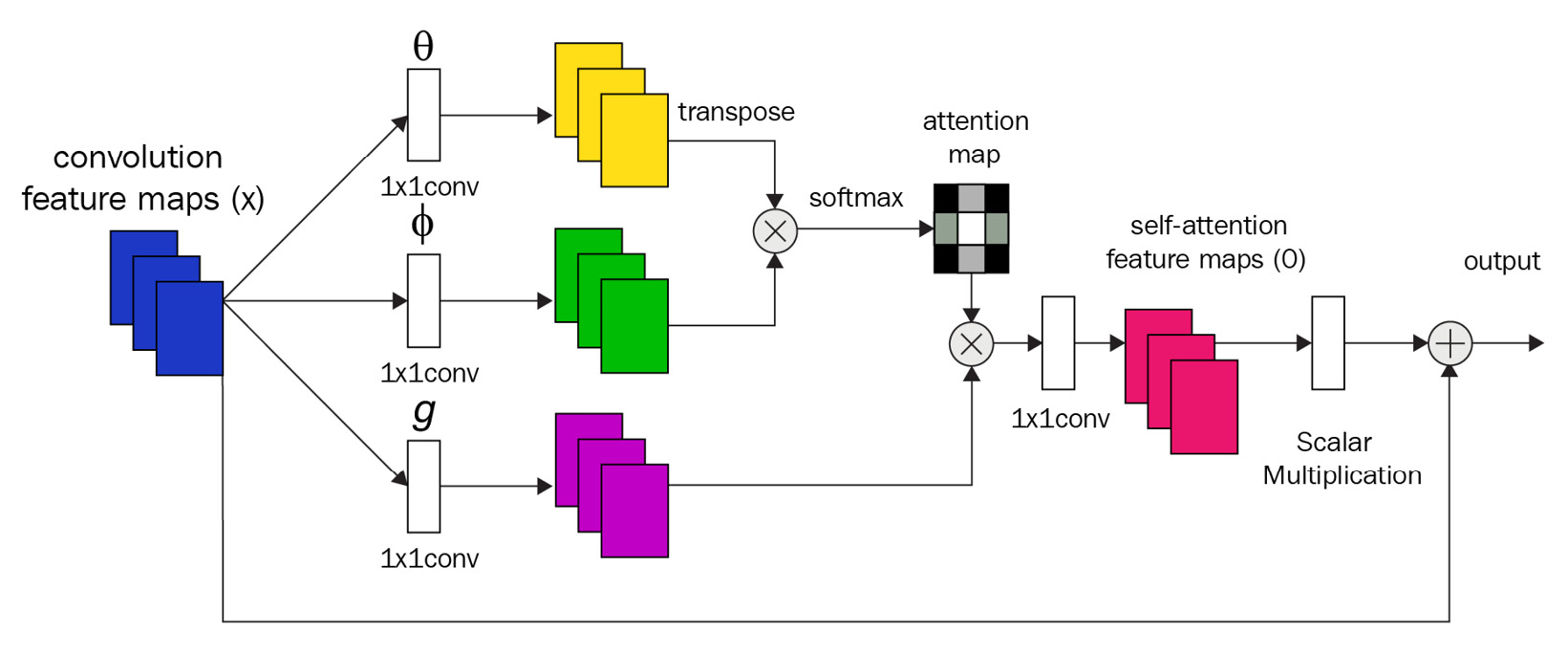
深度学习中的大多数计算都是为了提高速度性能而矢量化的,而对于自注意力也没有什么不同。如果为简单起见忽略 batch 维度,则 1×1 卷积后的激活将具有 (H, W, C) 的形状。第一步是将其重塑为形状为 (H×W, C) 的2D矩阵,并使用
θ
θ
θ 与
φ
φ
φ 的矩阵相乘来计算注意力图。在SAGAN中使用的自注意力模块中,还有另一个1×1卷积,用于将通道数恢复到与输入通道数相同的数量,然后使用可学习的参数进行缩放操作。
Tensorflow实现自注意力模块
首先在自定义层的build()中定义所有 1×1 卷积层和权重。这里,使用频谱归一化函数作为卷积层的核约束:
class SelfAttention(Layer):
def __init__(self):
super(SelfAttention, self).__init__()
def build(self, input_shape):
n,h,w,c = input_shape
self.conv_theta = Conv2D(c//8, 1, padding='same', kernel_constraint=SpectralNorm(), name='Conv_Theta')
self.conv_phi = Conv2D(c//8, 1, padding='same', kernel_constraint=SpectralNorm(), name='Conv_Phi')
self.conv_g = Conv2D(c//8, 1, padding='same', kernel_constraint=SpectralNorm(), name='Conv_g')
self.conv_attn_g = Conv2D(c//8, 1, padding='same', kernel_constraint=SpectralNorm(), name='Conv_AttnG')
self.sigma = self.add_weight(shape=[1], initializer='zeros', trainable=True, name='sigma')
需要注意的是:
- 内部的激活可以减小尺寸,以使计算运行更快。
- 在每个卷积层之后,激活由形状 (H, W, C) 被重塑为形状为 (H*W, C) 的二维矩阵。然后,我们可以在矩阵上使用矩阵乘法。
接下来在 call() 函数中将各层进行连接,用于执行自注意力操作。首先计算 θ \\theta θ, φ φ φ 和 g g g:
def call(self, x):
n, h, w, c = x.shape
theta = self.conv_theta(x)
theta = tf.reshape(theta, (-1, self.n_feats, theta.shape[-1]))
phi = self.conv_phi(x)
phi = tf.nn.max_pool2d(phi, ksize=2, strides=2, padding='VALID')
phi = tf.reshape(phi, (-1, self.n_feats//4, phi.shape[-1]))
g = self.conv_g(x)
g = tf.nn.max_pool2d(g, ksize=2, strides=2, padding='VALID')
g = tf.reshape(g, (-1, self.n_feats//4, g.shape[-1]))
然后,将按以下方式计算注意力图:
attn = tf.matmul(theta, phi, transpose_b=True)
attn = tf.nn.softmax(attn)
最后,将注意力图与查询 g g g 相乘,并产生最终输出:
attn_g = tf.matmul(attn, g)
attn_g = tf.reshape(attn_g, (-1, h, w, attn_g.shape[-1]))
attn_g = self.conv_attn_g(attn_g)
output = x + self.sigma * attn_g
return output
以上是关于TensorFlow实现自注意力机制(Self-attention)的主要内容,如果未能解决你的问题,请参考以下文章
Sklearn 与 TensorFlow 机器学习实用指南第二版
深度学习 CNN中的混合域注意力机制(DANet,CBAM),附Tensorflow完整代码