Python爬虫入门教程!全网最全反爬虫系列
Posted 不加班的程序员丶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫入门教程!全网最全反爬虫系列相关的知识,希望对你有一定的参考价值。
今天我们来一起了解一下什么是爬虫 什么是反爬虫。在了解什么是反爬虫手段之前,我们首先来看一看爬虫到底是什么?

名词解释
- 爬虫 —— 使用任何技术手段批量获取网站信息的一种方式,关键在批量。
- 反爬虫 —— 使用任何技术手段,阻止别人批量获取自己网站信息的一种方式。关键也在于批量。
- 误伤 —— 在反爬虫的过程中,错误的将普通用户识别为爬虫。误伤率高的反爬虫策略,效果再好也不能用。
- 拦截 —— 成功地阻止爬虫访问。通常来说,拦截率越高的策略,误伤率就越高,因此要做权衡。
- 资源 —— 机器成本与人力成本的总和。
什么是爬虫
在现在社会,网络上充斥着大量有用的数据,我们用上一些技术手段,就可以获取到大量的有价值数据。这里的"技术手段"就是指网络爬虫。
从功能上来讲,爬虫一般分为数据采集,处理,储存三个部分。
爬虫就是自动获取网页内容的程序,就像搜索引擎,Google等,每天都运行着庞大的爬虫系统,从全世界的网站中爬取数据,供用户检索时使用。但是也有恶意的爬虫,恶意的爬虫不仅会占用大量的网站流量,造成有真正需求的用户无法进入网站,影响网站或app的正常运行。

Python非常适合用来开发网页爬虫,理由如下:
1、抓取网页本身的接口
python抓取网页文档的接口更简洁;相比其他动态脚本语言,如shell,python的urllib包提供了较为完整的访问网页文档的API。
很多网站对于生硬的爬虫抓取都是封杀的。这是我们需要模拟user agent的行为构造合适的请求,譬如模拟用户登陆、模拟session/cookie的存储和设置。在python里都有非常优秀的第三方包帮你搞定,如Requests,mechanize
2、网页抓取后的处理
抓取的网页通常需要处理,比如过滤html标签,提取文本等。python的beautifulsoap提供了简洁的文档处理功能,能用极短的代码完成大部分文档的处理。
其实以上功能很多语言和工具都能做,但是用python能够干得最快,最干净。
想要学习Python的或者了解爬虫的兄弟们。资料已经整理好了,如果有朋友需要的话可以转发+关注后 私信@一个不秃头的 关键字【666】
常见的反爬虫措施
正是因为有爬虫对这个技术的存在,对于一般数据价值较高的网站,网站开发者都会给出一些针对网络爬虫的技术手段。这就是反爬虫。
我们也会对反爬虫进行细分,可以分为文本混淆反爬虫、行为验证反爬虫、信息校验反爬虫、动态渲染反爬虫等等。
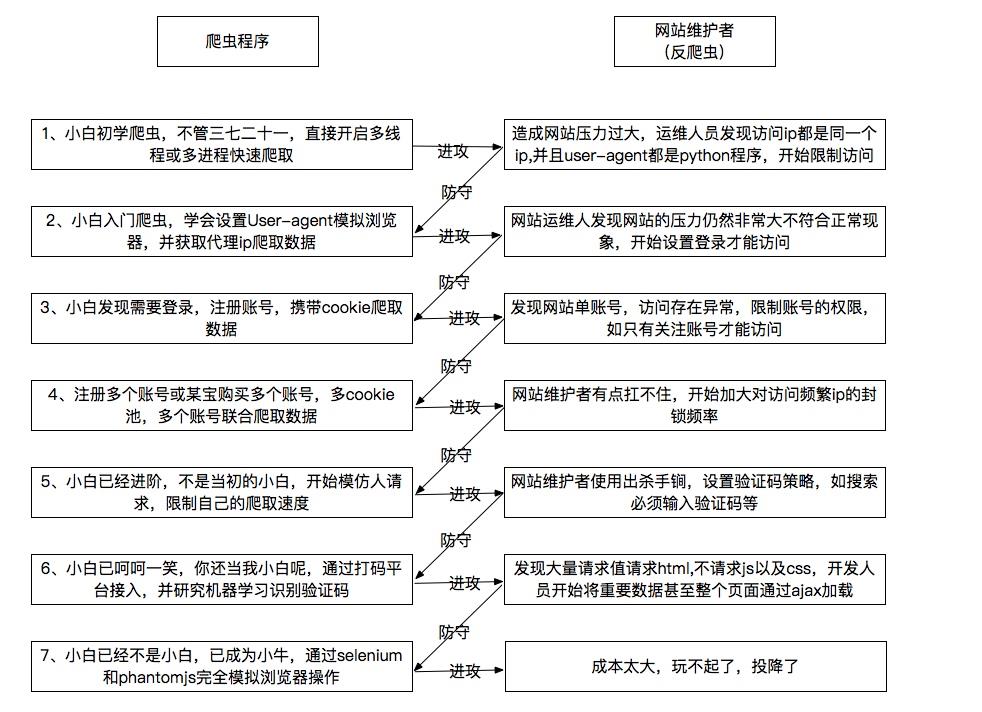
反爬虫的目的
初学者写的爬虫:简单粗暴有力量,不管对端服务器的压力,甚至会把网站爬挂掉了
数据保护:很多的数据对某些公司网站来说是比较重要的不希望被别人爬取
商业竞争问题:这里举个例子是关于京东和淘宝,假如京东内部通过程序爬取淘宝所有的商品信息,从而做对应策略这样对淘宝来说就造成了非常大的竞争。

行为验证反爬虫
行为式验证码是一种较为流行的验证码。从字面来理解,就是通过用户的操作行为来完成验证,而无需去读懂扭曲的图片文字。常见的有两种:拖动式与点触式。

根据用户识别图片之后,做出的选择来判断,当前是否是由正常的用户在进行请求,用于屏蔽掉技术含量不高的爬虫程序。
文本混淆反爬虫
文本混淆简单来讲就是如何有效地避免爬虫获取Web应用中重要的文字数据。反爬虫的前提是不能影响用户正常浏览网页和阅读文字内容,直接混淆文本很容易被看出来,因此开发者通常是利用字体之间的映射关系来实现混淆。
在这里通过对一些特殊文字进行字体映射,当网络爬虫在进行数据采集时无法直接获取到完整的数据,并且不影响正常用户的正常阅读。
动态渲染反爬虫
随着时代技术的不断迭代,越来越多的网站已经由传统的静态数据加载变为了动态数据加载,并且在动态加载的过程还伴随着越来越多的数据加密。
动态数据加载简单的理解,就是让浏览器先加载网站的大体框架,完成之后再发出异步的请求完成数据的填充,在发送请求的过程通过对请求参数的加密,来屏蔽掉非常低级的爬虫程序脚本。
例如:红人点数据集---js参数加密
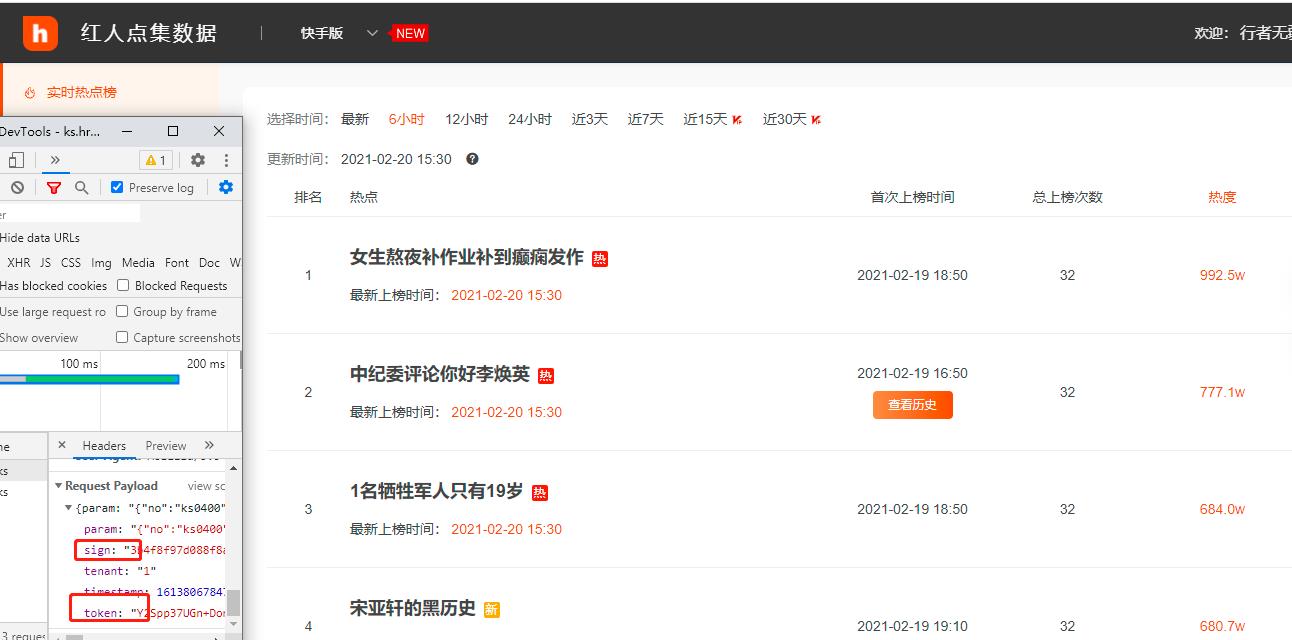
这里通过在发送异步请求时,校验关键参数,直接拦截一些最基本的爬虫请求,必须通过模拟参数加密的过程,才能正常的获取到数据。
爬虫与反爬虫是互联网开发工程师之间的斗智斗勇。
想要深入学习可以继续关注,接下来会更新一系列具体的网站反爬虫的解决方案。
另外我这里也有挺多关于爬虫的资料,需要的可以私信我 每条都会看会回复的哦~
如果您对编程有更多的兴趣,欢迎您私信我一起聊一聊,我们也会给您更加具体的建议和帮助!如果您喜欢小编的文章的话请别忘了一键三连呀~
以上是关于Python爬虫入门教程!全网最全反爬虫系列的主要内容,如果未能解决你的问题,请参考以下文章
常见的一些反爬虫策略(上篇)-Java网络爬虫系统性学习与实战系列