收藏 | 深度学习有哪些trick?
Posted 人工智能博士
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了收藏 | 深度学习有哪些trick?相关的知识,希望对你有一定的参考价值。
点上方人工智能算法与Python大数据获取更多干货
在右上方 ··· 设为星标 ★,第一时间获取资源
仅做学术分享,如有侵权,联系删除
转载于 :作者丨DOTA、永无止境、冯迁
来源丨知乎问答
编辑丨极市平台
问答来源:https://www.zhihu.com/question/30712664
# 回答一
作者:DOTA
京东算法工程师
来源链接:https://zhuanlan.zhihu.com/p/352971645
还是蛮多的,之前总结过一次,在这里搬运一下,DOTA:大道至简:算法工程师炼丹Trick手册
https://zhuanlan.zhihu.com/p/352971645
Focal Loss
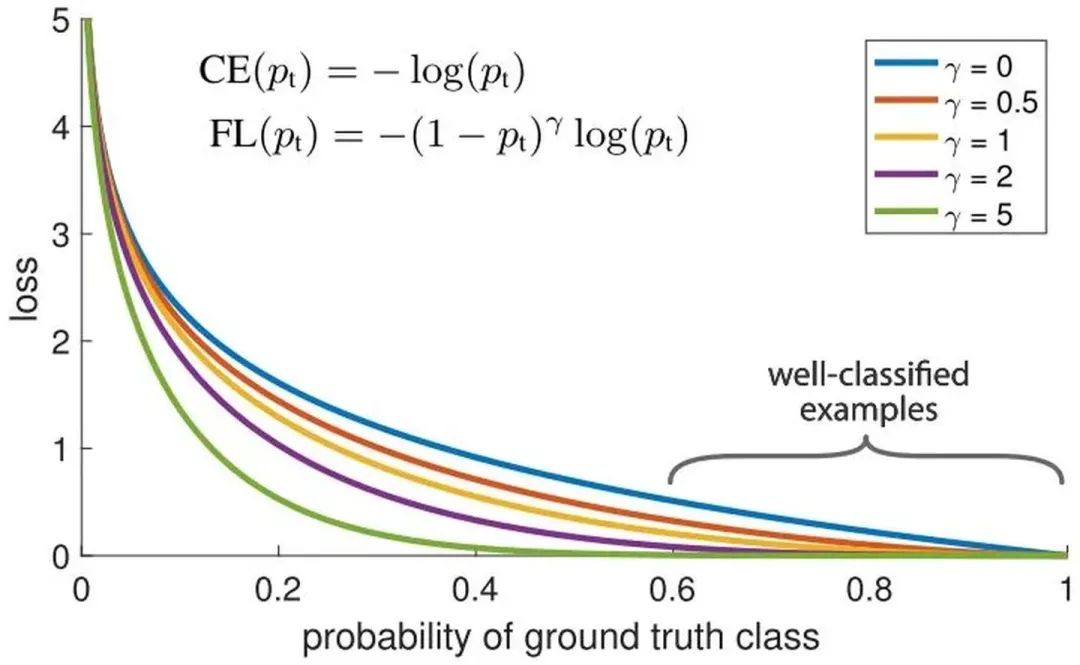
针对类别不平衡问题,用预测概率对不同类别的loss进行加权。Focal loss对CE loss增加了一个调制系数来降低容易样本的权重值,使得训练过程更加关注困难样本。
loss = -np.log(p)
loss = (1-p)^G * loss
Dropout
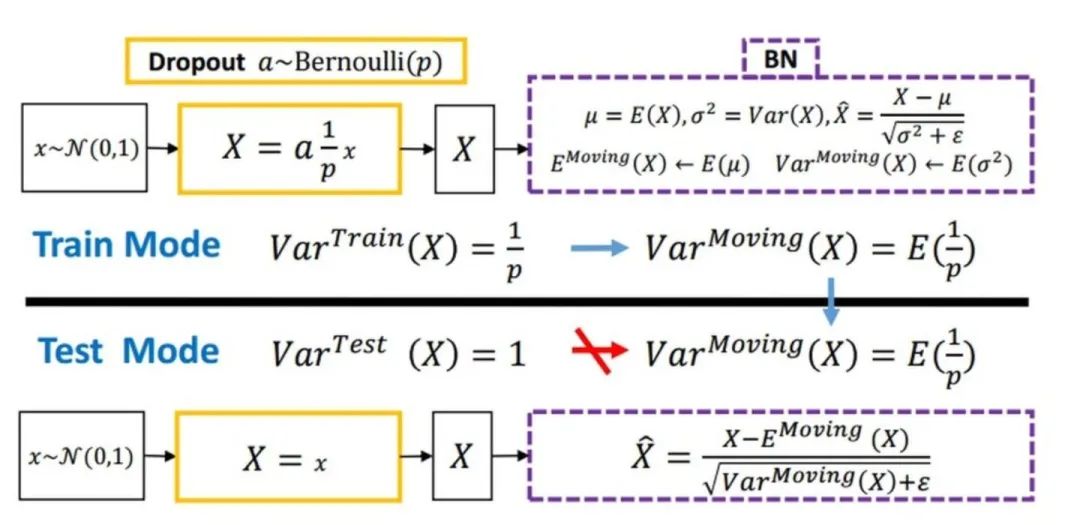
随机丢弃,抑制过拟合,提高模型鲁棒性。
Normalization
Batch Normalization 于2015年由 Google 提出,开 Normalization 之先河。其规范化针对单个神经元进行,利用网络训练时一个 mini-batch 的数据来计算该神经元的均值和方差,因而称为 Batch Normalization。
x = (x - x.mean()) / x.std()
relu
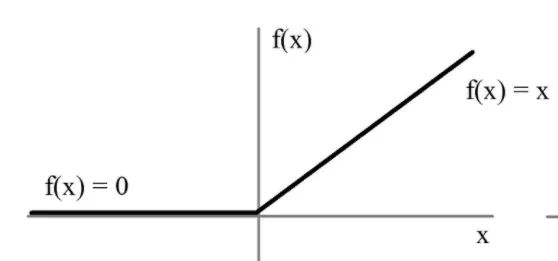
用极简的方式实现非线性激活,缓解梯度消失。
x = max(x, 0)
Cyclic LR
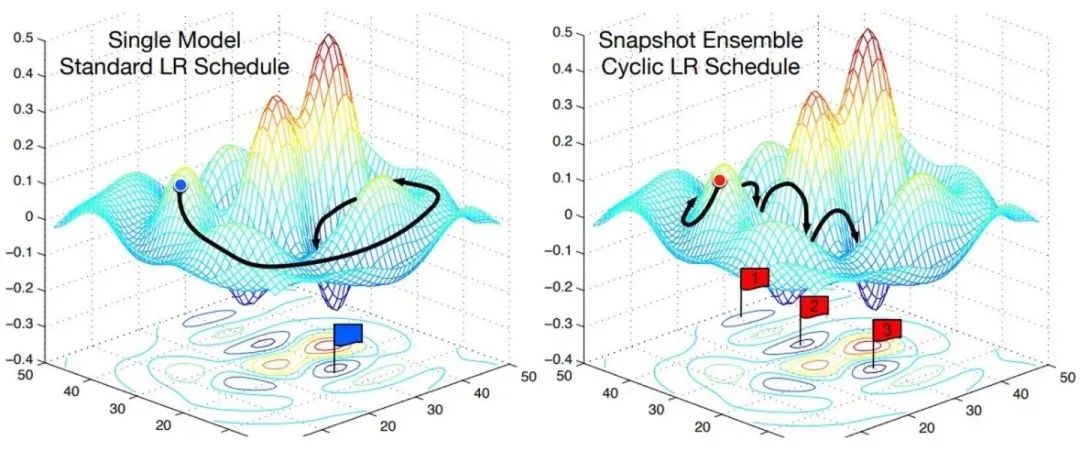
每隔一段时间重启学习率,这样在单位时间内能收敛到多个局部最小值,可以得到很多个模型做集成。
scheduler = lambda x: ((LR_INIT-LR_MIN)/2)*(np.cos(PI*(np.mod(x-1,CYCLE)/(CYCLE)))+1)+LR_MIN
With Flooding
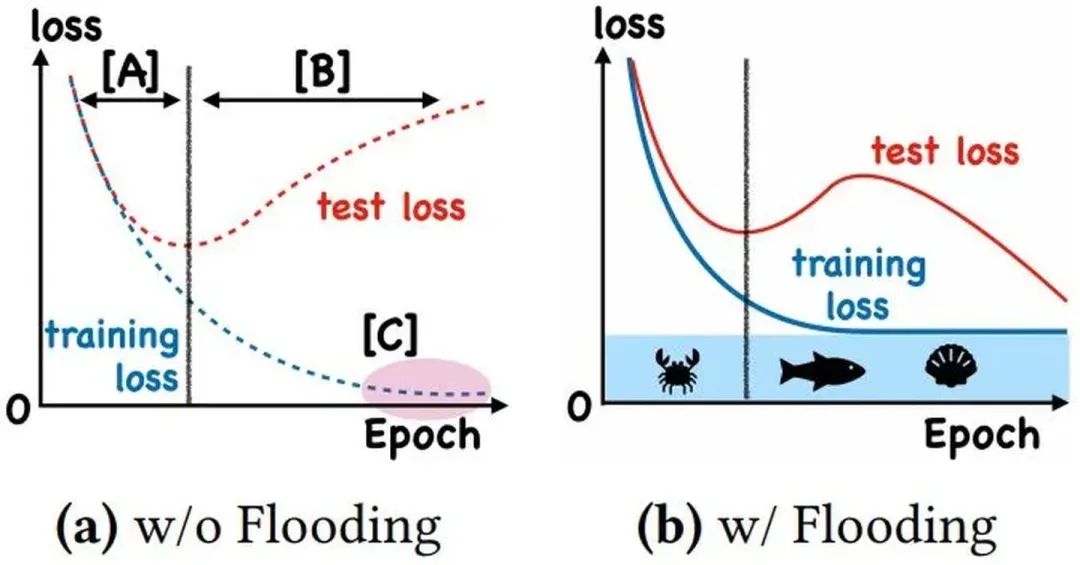
当training loss大于一个阈值时,进行正常的梯度下降;当training loss低于阈值时,会反过来进行梯度上升,让training loss保持在一个阈值附近,让模型持续进行"random walk",并期望模型能被优化到一个平坦的损失区域,这样发现test loss进行了double decent。
flood = (loss - b).abs() + b
Group Normalization
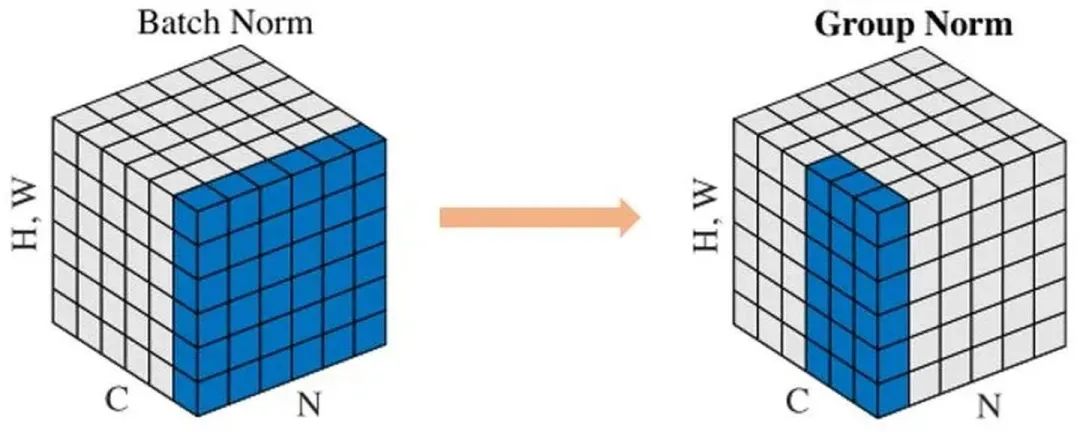
def GroupNorm(x, gamma, beta, G, eps=1e-5):
# x: input features with shape [N,C,H,W]
# gamma, beta: scale and offset, with shape [1,C,1,1]
# G: number of groups for GN
N, C, H, W = x.shape
x = tf.reshape(x, [N, G, C // G, H, W])
mean, var = tf.nn.moments(x, [2, 3, 4], keep dims=True)
x = (x - mean) / tf.sqrt(var + eps)
x = tf.reshape(x, [N, C, H, W])
return x * gamma + beta
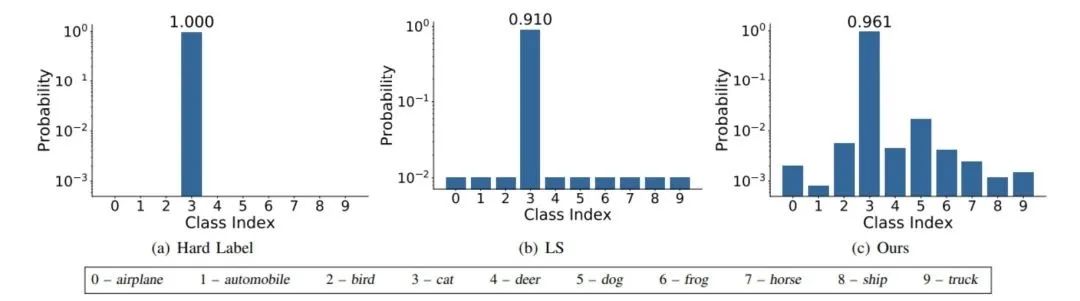
Label Smoothing
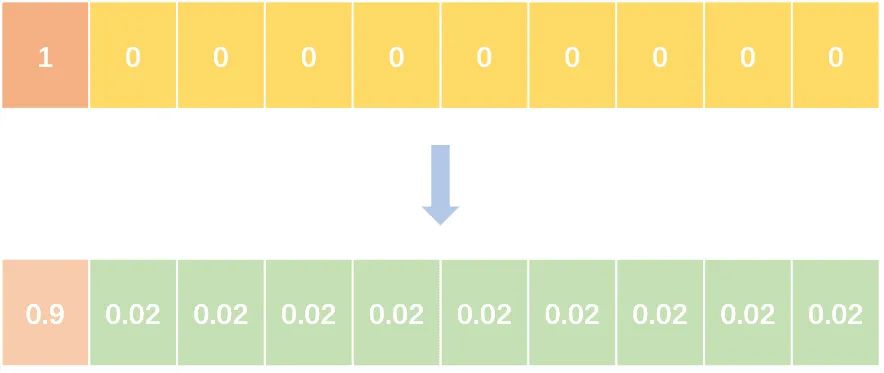
abel smoothing将hard label转变成soft label,使网络优化更加平滑。标签平滑是用于深度神经网络(DNN)的有效正则化工具,该工具通过在均匀分布和hard标签之间应用加权平均值来生成soft标签。它通常用于减少训练DNN的过拟合问题并进一步提高分类性能。
targets = (1 - label_smooth) * targets + label_smooth / num_classes
Wasserstein GAN
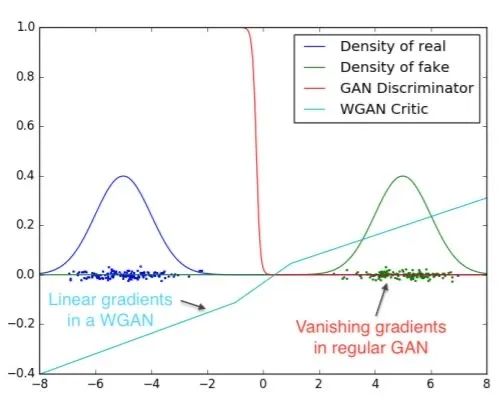
彻底解决GAN训练不稳定的问题,不再需要小心平衡生成器和判别器的训练程度
基本解决了Collapse mode的问题,确保了生成样本的多样性训练过程中终于有一个像交叉熵、准确率这样的数值来指示
训练的进程,数值越小代表GAN训练得越好,代表生成器产生的图像质量越高
不需要精心设计的网络架构,最简单的多层全连接网络就可以做到以上3点。
Skip Connection
一种网络结构,提供恒等映射的能力,保证模型不会因网络变深而退化。
F(x) = F(x) + x
参考文献
https://www.zhihu.com/question/427088601
https://arxiv.org/pdf/1701.07875.pdf
https://zhuanlan.zhihu.com/p/25071913
https://www.zhihu.com/people/yuconan/posts
# 回答二
作者:永无止境
来源链接:
https://www.zhihu.com/question/30712664/answer/1341368789在噪声较强的时候,可以考虑采用软阈值化作为激活函数:

软阈值化几乎是降噪的必备步骤,但是阈值τ该怎么设置呢?
阈值τ不能太大,否则所有的输出都是零,就没有意义了。而且,阈值不能为负。
针对这个问题,深度残差收缩网络[1][2]提供了一个思路,设计了一个特殊的子网络来自动设置:
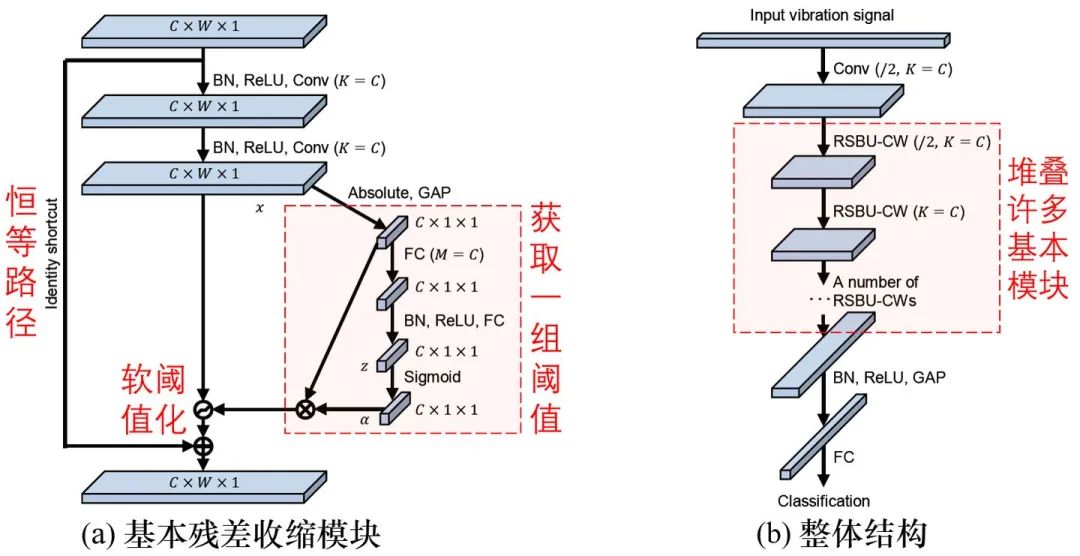
Zhao M, Zhong S, Fu X, Tang B, Pecht M. Deep residual shrinkage networks for fault diagnosis. IEEE Transactions on Industrial Informatics. 2019 Sep 26;16(7):4681-90.
参考:
^深度残差收缩网络:从删除冗余特征的灵活度进行探讨 https://zhuanlan.zhihu.com/p/118493090
^深度残差收缩网络:一种面向强噪声数据的深度学习方法 https://zhuanlan.zhihu.com/p/115241985
# 回答三
作者:冯迁
来源链接:https://www.zhihu.com/question/30712664/answer/1816283937
赞比较多的给了些,损失函数(focal),模型结构(identity skip),训练方面(strategy on learning rate),稳定性方面(normalization),复杂泛化性(drop out),宜优化性(relu,smooth label)等,这些都可以扩展。
focal 可以扩展到centernet loss,结构有尺度fpn,重复模块,堆叠concatenate,splite,cross fusion等,训练方面有teaching,step learning,对抗(本身是个思想),多阶段优化,progress learning,稳定性方面,batch normal,instance normal,group normal之外,还有谱范数等,复杂性还有正则l1/2等,宜优化性,可以扩展到检测的anchor等。
dl你得说优化器吧,把动量,一二阶考虑进来,梯度方向和一阶动量的折中方向,把随机考虑进来sgd
以上可能带来最多10的收益,你得搞数据啊
数据方面的处理clean,various ,distribution,aug data等更重要(逃…
“理论”在收敛速度,稳定,泛化,通用,合理等方面着手,性能在数据方面着手,也许
---------♥---------
声明:本内容来源网络,版权属于原作者
图片来源网络,不代表本公众号立场。如有侵权,联系删除
AI博士私人微信,还有少量空位


点个在看支持一下吧

以上是关于收藏 | 深度学习有哪些trick?的主要内容,如果未能解决你的问题,请参考以下文章
深度学习Trick——用权重约束减轻深层网络过拟合|附(Keras)实现代码