Understanding the Behaviors of BERT in Ranking
Posted Facico
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Understanding the Behaviors of BERT in Ranking相关的知识,希望对你有一定的参考价值。
Understanding the Behaviors of BERT in Ranking
该文章主要是研究BERT在passage re-ranking任务上的效果
数据集
MS MARCO数据集:QA问答数据集,从Bing上的用户搜索日志中的一些query,以及对应的一些候选passage。该任务的要求便是从候选的passage中选择能够回答该query的正确passage,包含一百多万个query和一百多万个passage。ClueWeb数据集类似
四种基于BERT的模型
-
1.BERT(Rep)
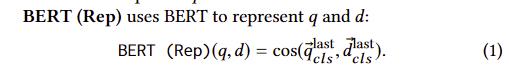 用顶层的[CLS]来作为询问和文章的表示,然后使用余弦相似度来排序。相当于做成一个representation提取器。
用顶层的[CLS]来作为询问和文章的表示,然后使用余弦相似度来排序。相当于做成一个representation提取器。 -
2.BERT(Last-Int)
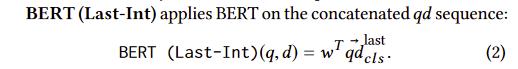 用文章的句子模型表示,和询问的原句用一个参数矩阵算出一个分数。相当于一个interaction-based的排序器
用文章的句子模型表示,和询问的原句用一个参数矩阵算出一个分数。相当于一个interaction-based的排序器 -
3.BERT(Mult-Int)
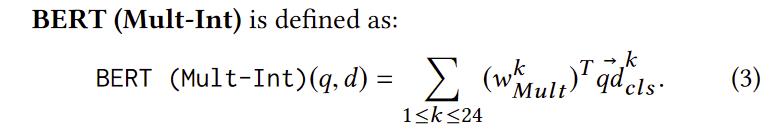 在第二个模型的形式上,句子模型表示用bert上每一层的[CLS]来加权
在第二个模型的形式上,句子模型表示用bert上每一层的[CLS]来加权 -
4.BERT(Term-Trans)
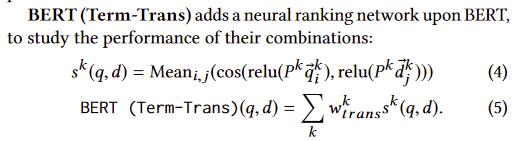 在第一个模型的形式上,对Bert每一层的query和document的每个词之间计算cosine距离,然后取平均。再用这些分数对每层加权求和(为了避免负的cosine干扰匹配分数的平均值,这里做了个relu层)
在第一个模型的形式上,对Bert每一层的query和document的每个词之间计算cosine距离,然后取平均。再用这些分数对每层加权求和(为了避免负的cosine干扰匹配分数的平均值,这里做了个relu层)
实验
各个模型的表现
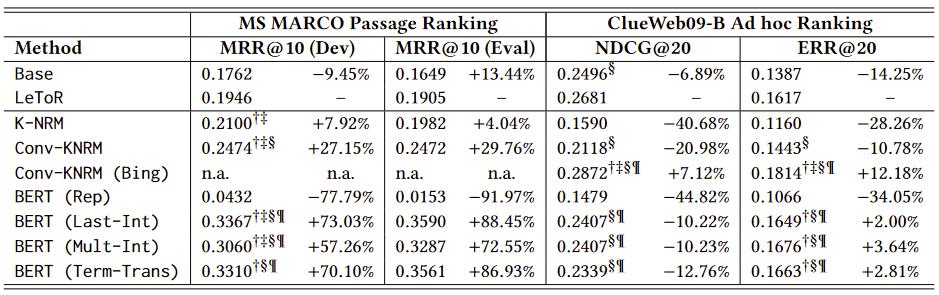
- 把bert当做representation使用效果不好且近似随机,说明在排序问题上bert不适合做一个representation model(可能是没有归一化)
- 稍微复杂的模型效果会变差,说明很难在fine-tune中显著地修改预训练的BERT
attention的可视化
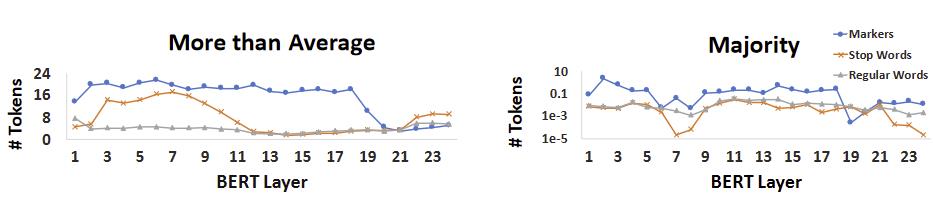 y轴是大于average 或 majority attention的token个数
y轴是大于average 或 majority attention的token个数
- 这里说明[SEP],[UNK]这种markers的很重要
- 当网络越深,attention就传播到整个句子上面,且embedding是与上下文有关的
随机去掉一个词对效果的影响
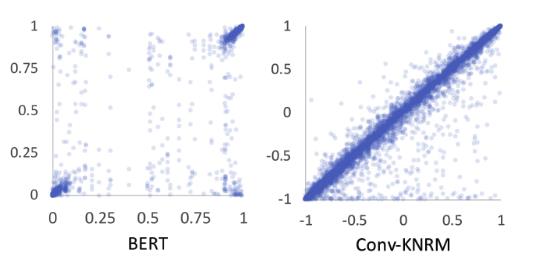 x轴是未去掉词之前的分数,y轴是去掉某个词之后的分数
x轴是未去掉词之前的分数,y轴是去掉某个词之后的分数
- 说面对bert而言,分数偏向0或1,学习效果较好
- 去掉某个词之后结果影响不是很大(集中在左下角和右上角),说面bert是一个上下文学习很好的模型
以上是关于Understanding the Behaviors of BERT in Ranking的主要内容,如果未能解决你的问题,请参考以下文章
Understanding the ASP.NET MVC Execution Process
Understanding the Module Pattern in JavaScript
Graying the black box: Understanding DQNs
mysql官方文档之Optimization(8.8 Understanding the Query Execution Plan)
每日一读Towards Understanding the Instability of Network Embedding
(转)Understanding Memory in Deep Learning Systems: The Neuroscience, Psychology and Technology Perspe